Pysparkで破産?
Databricksでは、Clusterという有償のコンピューティングリソースを用いてデータソースにアクセスしたり、プログラムを動かしたりします。
Clusterは従量課金制であり、その単位はDBUというもので表されます。
契約形態やClusterの種類にもよりますが、およそ1DBUは0.15~0.65ドル。ドルです。
Clusterはデータ量の大きさに応じれるようさまざまなマシンのサイズが用意されていますが、一番よく使うサイズであるi3 Xlargeインスタンスの3ノード(90GBくらい)で、だいたい1時間3DBU、つまり2ドルくらいです。
そしてClusterの裏側は自前で契約しているクラウドのコンピューティングリソース(AWSならEC2)なので、その料金もかかってきます。
だいたいDatabricks Cluster料金の等倍か、それ以下くらいだそうな。
なのでDatabricksでは、Sparkのメリットを受けられるほど大きくないデータを扱うだとか、慣れてないPysparkのコマンドを壁にぶち当たりつつ検証する、という使い方だと少しもったいないことになるというのは想像に難くないと思います。
皿洗いで、蛇口を開けたまま、なかなか取れない油汚れに苦戦するのと同じ感じで。
そこで、特に後者の「慣れてないPysparkのコマンドを壁にぶち当たりつつ検証する」で財布を痛めるのを回避するために、Pysparkを無料で使う方法をご紹介します。
Google Colabを使う
いろいろ試しましたが、「とにかく手軽にPysparkを試してみる」というニーズであれば、無料のPython環境であるGoogle Colabを使うのが最も手軽なのではないかと思います。
僕は最初ブラウザでのPython環境でJupyterNoteBookを使いましたが、Google Colabもなかなか使いやすいですよね!
検証にはGMO様のサイトを参考にしました。
結論、モジュールを入れるときにも使う!pip をするだけで出来ちゃいます。
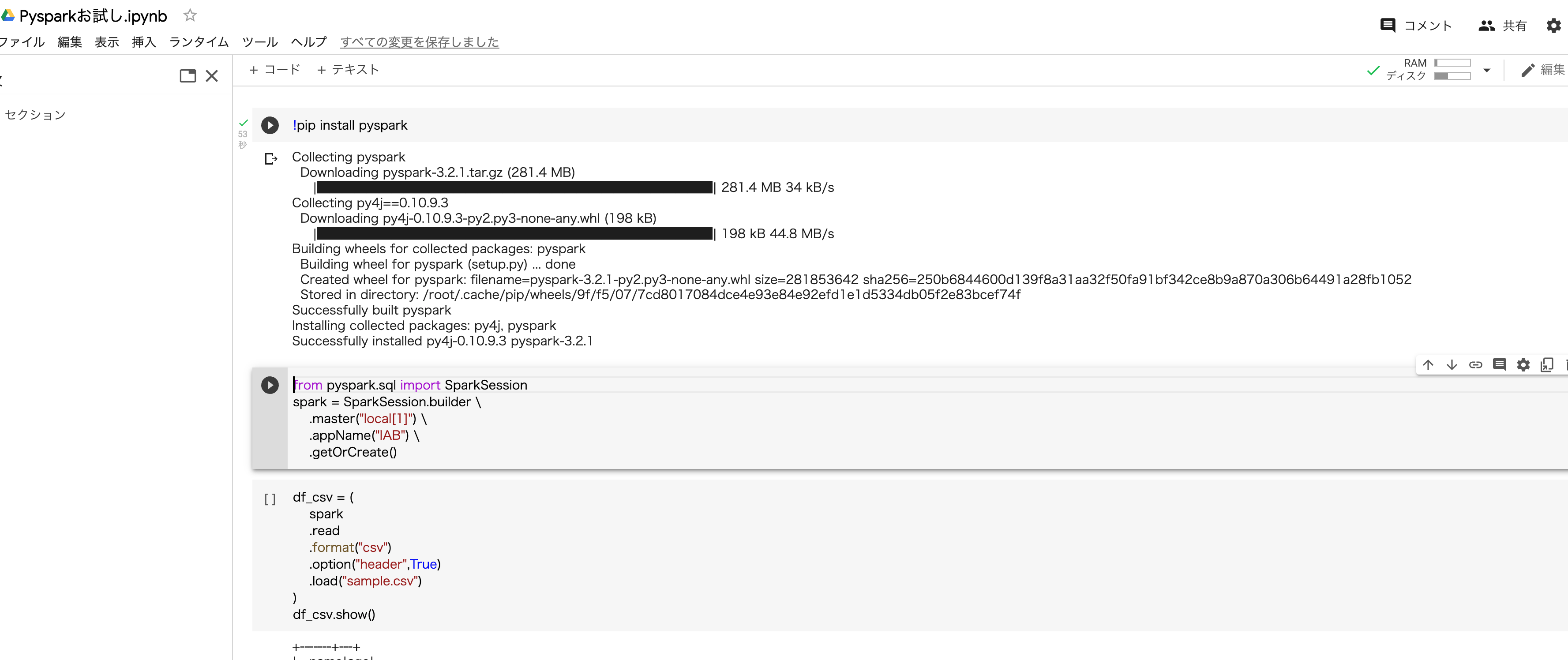
!pip install pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("local[1]") \
.appName("IAB") \
.getOrCreate()
これでsparkが定義されたので、あとはGoogle ColabにサンプルCSVを取り込むなり、スクリプト上でテストデータを作成して.createDataFrame()するなりでSpark DataFrameを作成、検証したいコードを実行することが出来ます。
今回はこうしたプチ節約術を紹介しましたが、機械学習での大量の教師データをクレンジング・学習するぜ!となったときは、さすがにシングルノードでは厳しいものがあると思いますので、そういうときに有償・高性能なDatabricks Clusterが活きるはず。
適材適所で、いいPysparkライフを送りたいですね!