はじめに
去る9/20、21日、PyCon2016に行ってきました。
諸事情でPython3のお勉強のお題を探しつつトークを聞いていたのですが、Pythonで作るWebクローラ入門で紹介されていた「Scrapy」が面白そうだったのと、ちょうどPython3に対応したとの事で、いっちょPython3でクローラー作ってみようと思いました。
ご注意!
- 理論よりも、とりあえず触って理解するやり方が好きなので、色々と雑です。
- さらに文盲ということで、分かりづらい文章になると思ってます。
- そんな訳で読んでてツッコミたくなる内容は多々あると思いますが、ご了承頂きたく!
※優しいツッコミは大歓迎です - クローリングは「紳士的に」
Webスクレイピングの注意事項一覧
3行でまとめ
- ScrapyとDjangoでラーメンマップ作った。
- Scrapy簡単&面白い。用法用量は注意。
- Python3もまぁなんとかなりそう!
システム構成
今回は食べログから会社近くのラーメン屋の名前、点数、座標をScrapyで取ってきて、ただ取ってくるだけじゃ面白くないのでGoogleMapのJavascriptAPIを使って地図に一括でプロットしてみました。
(念のため食べログの**robots.txt**でクローリングが禁止されていないことは確認済み)
構成はシンプルです。
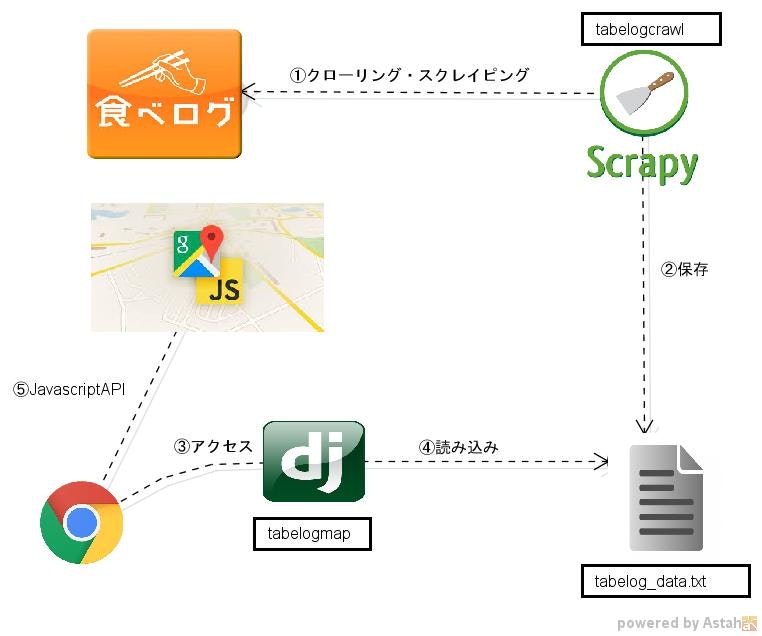
流れはこんな感じ
① Scrapyで食べログから店名、点数、緯度経度を取ってくる。
② お店の情報をファイルに保存。
③ ブラウザからサーバーにアクセス。
④ django(+djang-gmapi)がお店の情報を読み込んで、JavascirptAPIを呼び出すようにJinjaテンプレートに埋め込んで返却。
⑤ JavascriptでGoogleMapを表示。
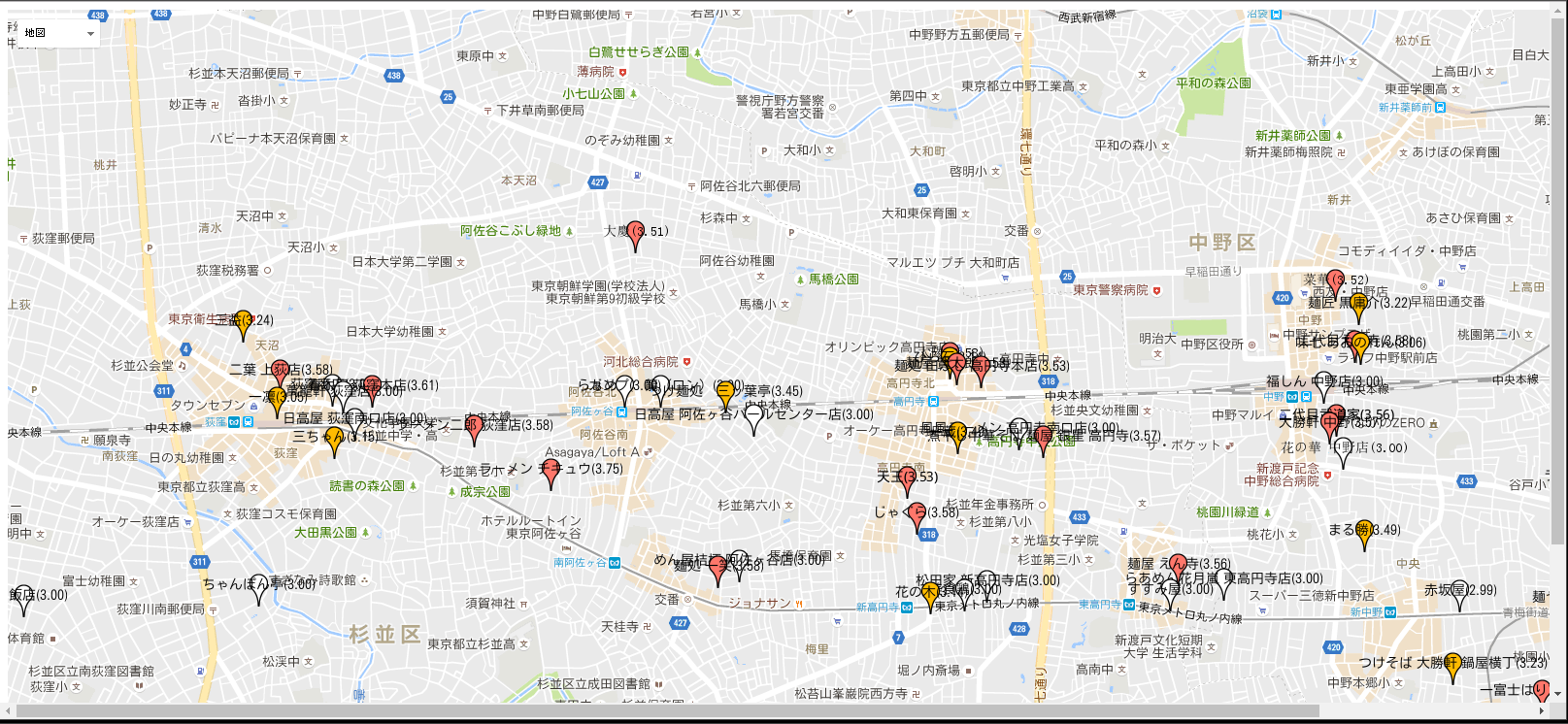
出来た
こんな感じになりました!(見やすいように件数は1/5位に減らしました。)
マーカーは、点数が3.5以上は赤色、3.0以下は白色、間は黄色にしてます。
予想通り、荻窪・高円寺駅前はスコアの高いラーメン店が多い…!
何気に中野駅から少し歩いた場所にもお店が。
クローリング・スクレイピングの流れ
こんな感じでクローリング・クスクレイピングしてます。
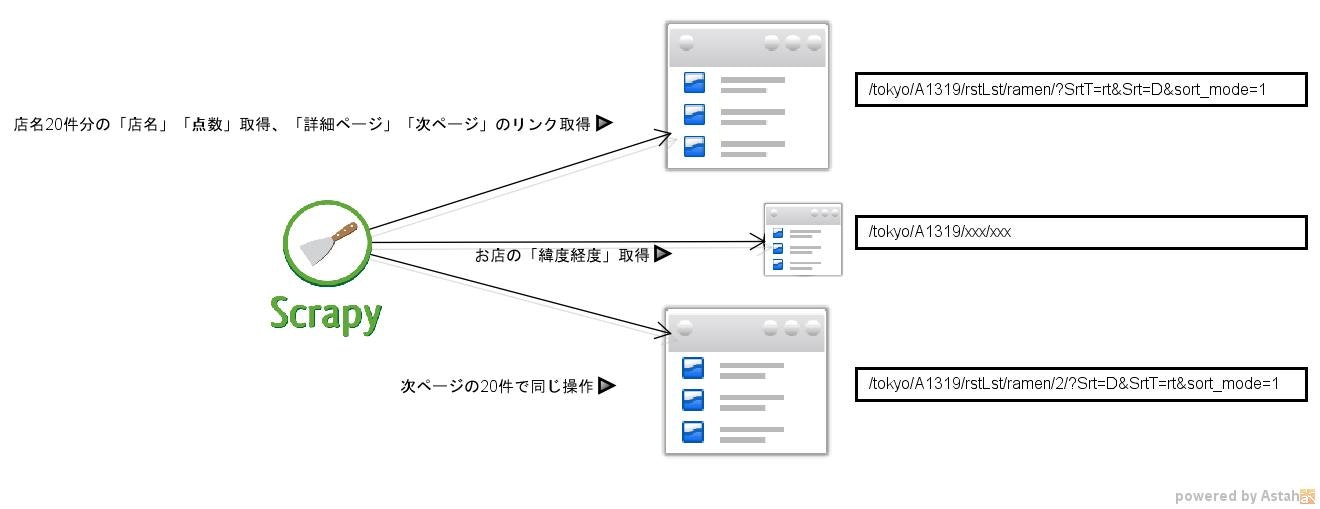
20件ずつ表示される一覧から「店名」「点数」は取得できますが「緯度経度」だけは、
各お店の詳細情報からしか取れないので、そちらから取ってきます。
20件から取り終えたら、次の20件を取得しに行きます。
収集間隔は手動と同じくらい(10秒)開けてます。**紳士的なクローリング(のつもり)**です。
食べログのURLの構造はシンプルなので、基点とするURL(start_urls)を変えれば、
ラーメン以外のリストや、東京以外の場所、色んなパターンでクローリング&マッピングできそうです。
動作環境
・Ubuntu 16.04.1
・Python 3.5.2
・Scrapy 1.2.0 ※pipでインストール
・Django 1.8
・Django-gmapi https://bitbucket.org/dbinit/django-gmapi/
トーク発表者の真嘉比さんの話だと、Ubuntuはapt-getでインストールした方が良さそうだったのですが、
Python3のScrapyはまだaptでは落とせない?ようだったので、Scrapyはpipでインストールしました。
今のところ、特に問題なく動かせてます。
ソースコード
クローリングの肝になってるSpider部分の抜粋です。
パース処理は今回BeutifulSoupを使いました。
# -*- coding: utf-8 -*-
from urllib.parse import urlparse, parse_qs
from datetime import datetime
import pytz
import scrapy
from scrapy.contrib.spiders import CrawlSpider
from bs4 import BeautifulSoup
from tabelogcrawl.items import TabelogcrawlItem
# 1ページ辺り何件取得するか(動作確認時は1とかにする)
LIMIT_GET_PER_PAGE = 20
class TLSpider(CrawlSpider):
name = "tlspider"
allowed_domains = ["tabelog.com"]
start_urls = (
'https://tabelog.com/tokyo/A1319/rstLst/ramen/1/?Srt=D&SrtT=rt&sort_mode=1',
)
def parse(self, response):
# 店の情報、店のスコアをリストから抽出。
soup = BeautifulSoup(response.body, "html.parser")
summary_list = soup.find_all("a", class_="cpy-rst-name")
score_list = soup.find_all(
"span", class_="list-rst__rating-val", limit=LIMIT_GET_PER_PAGE)
for summary, score in zip(summary_list, score_list):
# 店ごとに必要な情報をTabelogcrawlItemに格納。
jstnow = pytz.timezone(
'Asia/Tokyo').localize(datetime.now()).strftime('%Y/%m/%d')
item = TabelogcrawlItem()
item['date'] = jstnow
item['name'] = summary.string
item['score'] = score.string
href = summary["href"]
item['link'] = href
# 店の緯度経度を取得する為、
# 詳細ページもクローリングしてTabelogcrawlItemに格納。
request = scrapy.Request(
href, callback=self.parse_child)
request.meta["item"] = item
yield request
# 次ページ。
soup = BeautifulSoup(response.body, "html.parser")
next_page = soup.find(
'a', class_="page-move__target--next")
if next_page:
href = next_page.get('href')
yield scrapy.Request(href, callback=self.parse)
def parse_child(self, response):
# 店の緯度経度を抽出する。
soup = BeautifulSoup(response.body, "html.parser")
g = soup.find("img", class_="js-map-lazyload")
longitude, latitude = parse_qs(
urlparse(g["data-original"]).query)["center"][0].split(",")
item = response.meta["item"]
item['longitude'] = longitude
item['latitude'] = latitude
return item
Djangoの方はview部分を抜粋。
点数を元に色を決めてる部分は適当なので、正規化等でもう少し良い感じに色付けしたいです。
# -*- coding: utf-8 -*-
import codecs
import ast
from django import forms
from django.shortcuts import render_to_response
from gmapi import maps
from gmapi.forms.widgets import GoogleMap
SAVE_FILE = "../tabelog_data.txt"
class MapForm(forms.Form):
map = forms.Field(
widget=GoogleMap(
attrs={'width': 1850, 'height': 900}))
def index(request):
json_path = SAVE_FILE
raw_list = codecs.open(json_path, "r", encoding="utf-8").read().split("\n")
gmap = maps.Map(opts={
'center': maps.LatLng(35.70361991852944, 139.64842779766255),
'mapTypeId': maps.MapTypeId.ROADMAP,
'zoom': 15,
'mapTypeControlOptions': {
'style': maps.MapTypeControlStyle.DROPDOWN_MENU
},
})
info = maps.InfoWindow({
'content': 'ラーメンマップ',
'disableAutoPan': True
})
for raw_data in raw_list:
try:
json_data = ast.literal_eval(raw_data)
except:
continue
if float(json_data["score"]) > 3.5:
color = "FF776B"
elif float(json_data["score"]) > 3.0:
color = "FFBB00"
else:
color = "FFFFFF"
marker_info = {
'map': gmap,
'position': maps.LatLng(
float(json_data["longitude"]),
float(json_data["latitude"])),
"label": "%s(%s)" % (
json_data["name"],
json_data["score"]),
"color": color
}
marker = maps.Marker(opts=marker_info)
maps.event.addListener(marker, 'mouseover', 'myobj.markerOver')
maps.event.addListener(marker, 'mouseout', 'myobj.markerOut')
info.open(gmap, marker)
context = {'form': MapForm(initial={'map': gmap})}
return render_to_response('index.html', context)
所感
Scrapy使いやすいです。レイヤの低い処理を良い感じに隠蔽してくれてる感。
スケジューリング機能等も良い感じに使いこなせると楽しそう。
なんか簡単すぎてPython3の勉強にはなりませんでしたが笑
むしろdjango-gmapiがPython3対応してなかったので、
2to3で変換しつつゴニョゴニョして動かしましたが、そっちの方がちょっと時間かかった…。
Python3もそれ程怖くないのはわかったけど、まだちょっと勉強は必要だなぁ。