はじめに
前回の「データ前処理編」から時間が空いてしまいましたが、今回はTwitterのテキストデータをクラスタリングをしてみます。
3行でまとめ
- (やっと)クラスタリングした。
- クラスタリングした結果をmatplotlibで可視化した。
- 次回は脇道で可視化の小技紹介になるかも。
いきなりソースコード(可視化以外)
前回の「ベクトライズ」の実装に**「クラスタリング」****「次元圧縮」**の実装を追加してみました。(「可視化」のソースはちょっと長いので後で)
# ! /usr/bin/env python
# -*- coding:utf-8 -*-
import MeCab as mc
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.decomposition import TruncatedSVD
MECAB_OPT = "-Ochasen -d C:\\tmp\\mecab-ipadic-neologd\\"
NUM_CLUSTER = 3
SAMPLE_DATA = [
# 前回と同じなので省略
]
def mecab_tokenizer(text):
# 前回と同じなので省略
def main():
# ベクトライザクラス初期化(前回と同じ)
vectorizer = TfidfVectorizer(
min_df=1, stop_words=[u"Perfume", u"HTTPS"],
tokenizer=mecab_tokenizer)
# サンプルデータのベクトル化(前回と同じ)
tfidf_weighted_matrix = vectorizer.fit_transform(SAMPLE_DATA)
# K-Meansのクラスタ分析クラス初期化
km_model = KMeans(n_clusters=NUM_CLUSTER)
# ベクトル情報を食わせて、クラスタ分析を実行
km_model.fit(tfidf_weighted_matrix)
# 次元圧縮(特異値分解)クラス初期化
lsa = TruncatedSVD(2)
# サンプルデータ、及びクラスタ中心点のベクトル情報を2次元に圧縮
compressed_text_list = lsa.fit_transform(tfidf_weighted_matrix)
compressed_center_list = lsa.fit_transform(km_model.cluster_centers_)
if __name__ == '__main__':
main()
何をやっているか、ちょっとずつ見ていきます。
クラスタリング
# K-Meansのクラスタ分析クラス初期化
km_model = KMeans(n_clusters=NUM_CLUSTER)
# ベクトル情報を食わせて、クラスタ分析を実行
km_model.fit(tfidf_weighted_matrix)
処理内容はコメントに書いてある通り。ここで悩むのはKMeansクラス初期化時に渡すパラメタですが、とりあえず動かすだけならチューニングはほぼ不要です。今回は扱うデータの件数が5件と少ない為、クラスタ数はデフォルトの8から3に変更していますが、他はデフォルトのままです。
(その他のパラメタの詳細: sklearn.cluster.KMeans)
初期化後はfitでデータを食わせて分析するだけ。
主な分析結果は、km_modelの以下を参照して確認できます。
| パラメタ | 内容 | 値の例 |
|---|---|---|
| km_model.cluster_centers_ | クラスタごとの中心点のベクトル情報 | [[0, 0, 0.46369322, 0.46369322, 0, 0.46369322, 0, 0, 0, 0, 0, 0, 0, 0.37410477]...(クラスタの数だけ)] |
| km_model.labels_ | 分析対象データの要素ごとのラベル(どのクラスタに属するかを示す値) | [2 1 1 0 1] |
ただ、この結果(数値の羅列)を見せられてもナンノコッチャ過ぎるので、クラスタを可視化してみます。
そのために必要なのが次の次元圧縮です。
(可視化の為の)次元圧縮
# 次元圧縮(特異値分解)クラス初期化
lsa = TruncatedSVD(2)
# サンプルデータ、及びクラスタ中心点のベクトル情報を2次元に圧縮
compressed_text_list = lsa.fit_transform(tfidf_weighted_matrix)
compressed_center_list = lsa.fit_transform(km_model.cluster_centers_)
"次元圧縮"と聞くと反射的にファイナル○ァンタジーⅤやⅧが脳裏に浮かぶ世代です。どうもSF的な何かを彷彿させる字面ですね。ただ、目的は「高次元な情報なんて図示できないから、(近似で良いので)xyの2次元に変換したい」というだけで、(かなり強引な理解だけど)字面ほど数学界隈の尖った言葉という事でもないのです。
具体的には、今回次元数は「全テキストに登場する単語の種類」となっている為、サンプルデータは以下のような14次元のデータになっています。これを図示するのは難しいですね。
[0, 0, 0.46369322, 0.46369322, 0, 0.46369322, 0, 0, 0, 0, 0, 0, 0, 0.37410477]
これを次元圧縮によって、以下のような2次元にしてしまいます。これならxyの2軸の図にプロットできますね。
[9.98647967e-01, 0.00000000e+00]
なお次元圧縮の手法も色々とあるのですが今回は**潜在意味解析(LSA)**というものを使います。これまた強そうな字面ですが、上記ソースコードの通り、scikit-leanを使えば簡単です(今回はTruncatedSVDを使いますが、他にもあるみたいです)。上記の実装では14次元のサンプルデータのベクトル情報、クラスタ分析結果の中心点のベクトル情報を2次元に変換しています。
これで可視化の準備が整いました。
ソースコード(可視化部分)
ここまでの実装で、クラスタを可視化するために必要な情報は揃ったので、matplotlibを使った描画処理を追加してみます。
import matplotlib.pyplot as plt
from matplotlib import cm
import matplotlib.font_manager as fm
FP = fm.FontProperties(
fname=r'C:\WINDOWS\Fonts\YuGothL.ttc',
size=7)
def draw_km(text_list, km_text_labels,
compressed_center_list, compressed_text_list):
# 描画開始。
fig = plt.figure()
axes = fig.add_subplot(111)
for label in range(NUM_CLUSTER):
# ラベルごとに色を分ける。
# 色はカラーマップ(cool)におまかせする。
color = cm.cool(float(label) / NUM_CLUSTER)
# ラベルの中心をプロット
xc, yc = compressed_center_list[label]
axes.plot(xc, yc,
color=color,
ms=6.0, zorder=3, marker="o")
# クラスタのラベルもプロット
axes.annotate(
label, xy=(xc, yc), fontproperties=FP)
for text_num, text_label in enumerate(km_text_labels):
if text_label == label:
# labelが一致するテキストをプロット
x, y = compressed_text_list[text_num]
axes.plot(x, y,
color=color,
ms=5.0, zorder=2, marker="x")
# テキストもプロット
axes.annotate(
text_list[text_num], xy=(x, y), fontproperties=FP)
# ラベルの中心点からの線をプロット
axes.plot([x, xc], [y, yc],
color=color,
linewidth=0.5, zorder=1, linestyle="--")
plt.axis('tight')
plt.show()
def main():
# 次元圧縮までは同じなので省略
# データを可視化
# ※km_model.labels_にSAMPLE_DATAの各要素のラベル情報が格納されている。
draw_km(SAMPLE_DATA, km_model.labels_,
compressed_center_list, compressed_text_list)
if __name__ == '__main__':
main()
結果はこんな感じになりました!
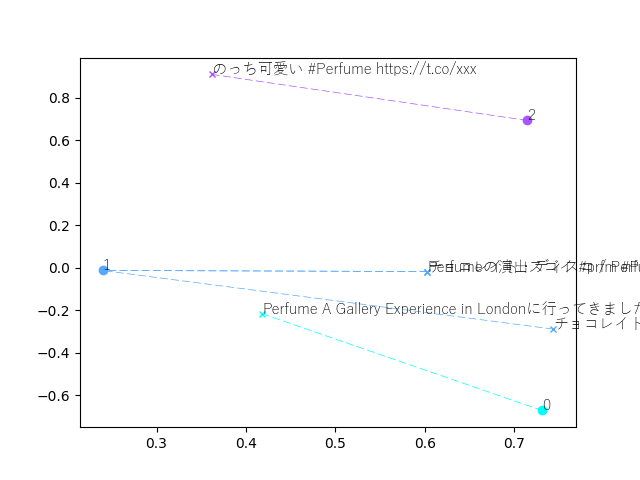
| テキスト | クラスタ |
|---|---|
| のっち可愛い #Perfume https://t.co/xxx | 2 |
| Perfumeの演出スゴイ #prfm #Perfume_um https://t.co/xxx | 1 |
| チョコレイト・ディスコ / Perfume #NowPlaying https://t.co/xxx | 1 |
| Perfume A Gallery Experience in Londonに行ってきました https://t.co/xxx | 0 |
| チョコレイトディスコの演出カッコいい。ライブ行きたい。#Perfume https://t.co/xxx | 1 |
データ数が少ないから見栄えが微妙…。
でもなんとなーく、分類出来てる気がする!
ついにクラスタリング出来た!
K-means法を使ったテキストデータのクラスタリングの触り部分は出来ました。km_modelsに新しいデータを食わせれば、どのクラスタに分類するか解を返してくれるはず。(つまりテキスト分類器!)
次回は実際に新規データを分類、データ数を増やした結果を見てみます。
あと脇道に逸れちゃいますがmatplotlibでの見せ方をちょっとだけ工夫してみたいと思います。