この記事は以下の続きです
今回は楽天レシピから取得した「材料」と「量」のデータを加工していきます。
買い物リスト作成アプリの機能として、
・同じ材料名の量を足す(玉ねぎ:1玉 + 玉ねぎ:1/2玉 = 玉ねぎ:3/2玉 みたいな)
・ユーザーが欲しい人数分の量に変換する(1人前:玉ねぎ:1/2玉 → 3人前:玉ねぎ:3/2玉 みたいな)
というところを実装したいです。
これがやり易いようにデータを加工していきます。
買い物リスト作成アプリの概要はこちら
★このページは以下項目で構成されています★
| 項番 | ページ内リンク |
|---|---|
| 1 | 目指すデータ型 |
| 2 | やること |
| 3 | 記号を消す・文字を変換する |
| 4 | 行の削除 |
| 5 | 「少々」や「適量」など扱う量が数字ではない時の処理を考える |
| 6 | 量を数字と単位に分割 |
| 7 | 二つの列を合体させる |
| 8 | 学んだこと |
目指すデータ型
最終的のこの形にしていきます。
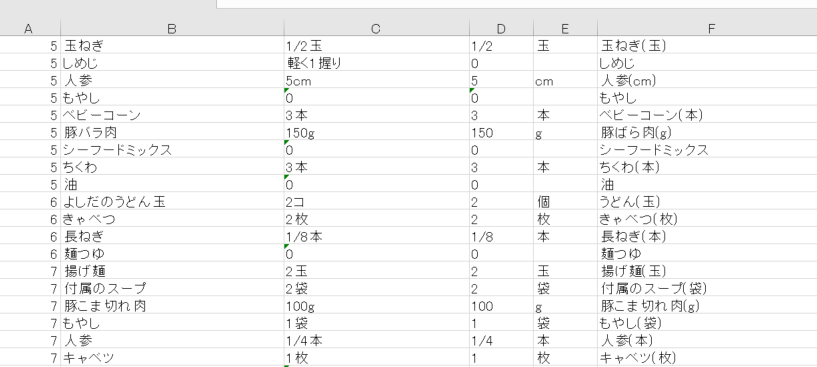
この型になるまで、紆余曲折ありデータ加工に3週間かかりました・・・。
理由は後程・・・。
やること
上記のデータ型にするためにやることは以下です。
・材料名に☆や★などの、記号や材料と関係のないワードがある場合、消す
・「にんじん」「人参」「ニンジン」の様に、同じ材料なのに表記が違うものは、材料名を統一する
・量がnoneである時の処理
・「少々」や「適量」など扱う量が数字ではない時の処理を考える
・同じ材料名の量を足しやすいように、量を数字と単位に分割
・同じ人参でも、単位が「本」の場合と「cm」の場合があるのでF列に材料と単位を一緒にした列を新たに作成
この材料は全部で14400行あるので、加工を完璧にするのは難しそう・・・ということで8割程度の加工を目指しました。
記号を消す・文字を変換する
まず、データをざっと見て消したい記号も、変換したい文字も大量にあると感じました。
メンターさんに、そのようなときは変換したい文字を表にすると良いとアドバイスを頂き、文字変換表を作りました。
文字変換表はこちら
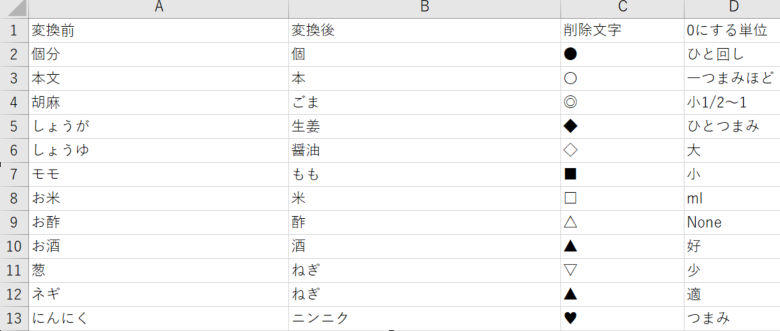
変換したい文字は169個、削除したい文字は69個ありました。
記号を消す
まず、文字変換表から削除したい記号列をリスト化します。
import openpyxl #Excel扱うのに必要
#読み込むExcelファイル指定
file = "test"
wb= openpyxl.load_workbook(file + ".xlsx")
ws = wb.worksheets[0]
#文字変換Excelファイル指定
read_file = "文字変換.xlsx"
read_wb= openpyxl.load_workbook(read_file)
read_ws = read_wb.worksheets[0]
#文字変換excelから削除文字列のリストを作る
delete_list= []
for row in read_ws.iter_rows(min_row=2,max_row=69, min_col=3, max_col=3): #削除文字の範囲を選択
for cell in row:
delete_list.append(cell.value)
次に、replaceを使って削除文字リストが材料の列にある時に、文字が消える様にします。
for delete in delete_list:
for row in ws.iter_rows():
for cell in row:
#列を指定
if cell.col_idx == 1:
#文字に削除したい記号が含まれている時に実行
if delete in str(cell.value):
#文字を置換
new_text = cell.value.replace(delete, "") #replace(●, ○)で、●を○に置換する。
cell.value = new_text
#保存
wb.save(file + ".xlsx")
こちらの test.xlsxファイルで実行してみます。
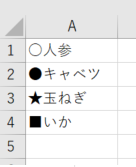
結果はこちら

記号を消すことができました!
文字を変換する
同じようにreplaceを使って文字を変換してみます。
まず、変換前の文字リストと、変換後の文字リストを作ります。
ファイルを読み込む部分は省略します。
#置換文字列のリストを作る
Henkan_mae = []
for cell in read_ws["A"]: #ワークシート名.["列"]でExcelの列指定が出来る
Henkan_mae.append(cell.value)
Henkan_go = []
for cell in read_ws["B"]:
Henkan_go.append(cell.value)
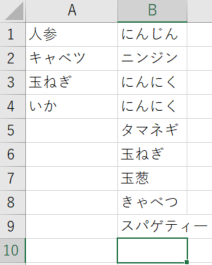
今回も test.xlsxの B列の文字を変換していきます。
i = 0
for moji in Henkan_mae:
i = i + 1
#変換したい文字列があるワークシートを指定
for row in ws.iter_rows():
for cell in row:
#文字変換したい列指定
if cell.col_idx == 2:
#セルにmojiが含まれていたら
if str(moji) in str(cell.value):
#mojiを変換
new_text = str(cell.value).replace(str(moji), str(Henkan_go[i-1]))
cell.value = new_text
#保存
wb.save(file + ".xlsx")
結果はこちら

概ね上手く変換できました。「タマねぎ」や「パスター」は再度文字変換して直して行きます。
行の削除
楽天レシピの、以下の様に量が無い場合、
材料表の量の部分には none と入力されるように前回データ収集をしました。

そして、noneが入力されている材料の部分は、コメントになっているので
行ごと削除することにしました。
また、材料が「塩、水、お湯、熱湯、胡椒、砂糖」などどこのご家庭にもありそうな場合や
買う必要がない場合の材料の行も削除します。
「塩、しお、シオ」、「みず、水」など複数の表記方法がありますが、左記に上記の文字変換コードで表記を統一しておくと楽です!
#Excelを読み込む部分は省略
#range(開始,終了,増加量)を使う
for i in range(ws.max_row, 1, -1):
if "塩" in str(ws.cell(i, 2).value): #材料に含まれていたら行ごと削除したい文字を入力
ws.delete_rows(i)
wb.save(file + ".xlsx)
「少々」や「適量」など扱う量が数字ではない時の処理を考える
これは悩みました。
大体、「少々」や「適量」の表記があるものは、調味料であることが多いです。
「オリーブオイル:適量」
「塩コショウ:少々」など
たまに「唐辛子:少量」とかもありますが・・・
考えた結果、お買い物リストにしたいので、細かな量は必要ないのではという発想に至りました。
さらに、「醤油:大さじ1」や「ラー油:5滴」や「酒:20ml」など、その調味料自体が必要なことが分かればいいのでは!
と思い、調味料や少量の材料の量は 「0」 で表記することにしました。
ということで、量を0にしたいワードリストを文字変換ファイルにつくりました。

コードは以下です
import openpyxl
file = "test"
filename = file + ".xlsx"
wb= openpyxl.load_workbook(filename)
ws = wb.worksheets[0]
read_file = "文字変換.xlsx"
read_wb= openpyxl.load_workbook(read_file)
read_ws = read_wb.worksheets[0]
#置換文字列のリストを作る
amount_delete = []
for cell in read_ws["D"]:
Ryo_delete.append(cell.value)
i = 0
#リストをループ
for i in range(ws.max_row, 1, -1):
for moji in amount_delete:
if moji in ws.cell(i, 2).value:
#今回は置換文字が含まれているセルをまるごと0に変える
#今後、量を数字と単位に分割するので、3列目に0を入力
new_text = ws.cell(i,3).value.replace(cell.value,"0")
cell.value = new_text
#保存
wb.save(file + ".xlsx")
量を数字と単位に分割
同じ材料の量を足し算したり、量を欲しい人数分に変換したりしたいので、
計算しやすいように量を数字と単位に分けていきます。
この様に、数字をD列、単位をE列に格納します。

今回はsplit関数を使いました。
split("分割したい文字列")で、分割したい文字列を含まずに、前後の文字をリストで返してくれます。
list=[aiueo]
i = list.split("u")
print(i)
#結果
[ai,eo]
という感じです。
量の列をざっと見ると、調味料以外の材料の単位はそんなに多くはないと感じ、今回は表にせずにリストとして作りました。
でも、全部書いてみると以外と多かったので、表にしたら良かったです。
#ファイル読み込みは省略
tani_list = ["合","g","腹","粒","把","袋","個","kg","枚","本","玉","丁","食","缶","cm","束","房","人前","片","カット","株","箱","つ","匹","切れ","柵","冊","杯","皿"]
for row in ws.iter_rows(min_row=2, max_row=14423, min_col=3, max_col=5):
for tani in tani_list:
if tani in str(row[0].value):
amount = row[0].value.split(tani)[0] #単位は最後についているので、split()[0]にすると数字のみ返せます
row[1].value = amount
row[2].value = tani
wb.save("recipe_ingredients.xlsx")
二つの列を合体させる
最後のデータ加工です!
同じ材料でも単位が違うことがあるので、判別するためには材料と単位を合体させるのが良いと考えました。
そこで、材料と単位を一緒にした列を新たに作成します!
キャベツ(枚)
キャベツ(玉)
のような感じです。
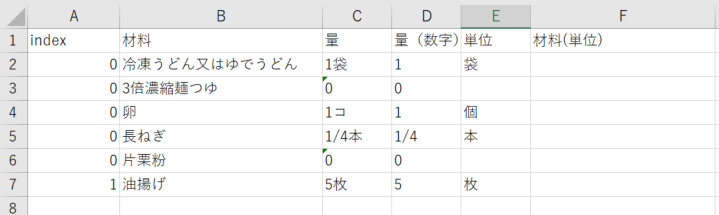
このテストファイルで実行してみます。
#ファイル読み込みは省略
#Excelの6列目に新たに 合体した材料と単位を入力したいので、 min_col=2, max_col=6で範囲指定
for row in ws.iter_rows(min_row=2, min_col=2, max_col=6):
if str(row[2].value) == str("0") : # D列が0の時は単位が無いので、材料名と単位は合体させない
row[4].value = row[0].value
else: #それ以外は材料と単位を合体する
sum_cell = str(row[0].value) + "(" + str(row[3].value) + ")"
row[4].value = sum_cell
#保存
wb.save("recipe_ingredients.xlsx")
材料と単位が合体できました!
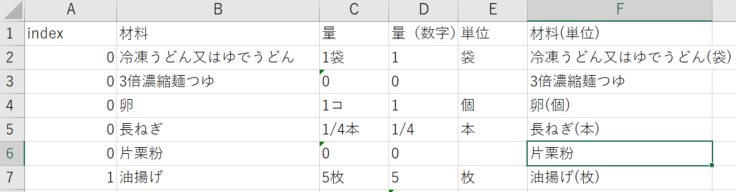
これでやっとデータ収集から加工まで終わりです。
アプリを作る2か月の内、1.5か月をここまでかけてしまいました・・・
いかんせん、データ量が多すぎる!!データ加工しても加工しても終わりが見えないというドツボにハマってしまいました。
学んだこと
同時に、データ加工しやすいように情報を集める重要性と、
ある程度データ加工しやすいようにアプリを作るのって大切だと感じました。
(入力欄は自由記入ではなくて、選択性にしてみるなど)
次から、検索システムを作っていきます!