DMMデータインフラ部に所属しているyuuaです
DMMデータインフラ部では、一部プロダクトにてaws step functions を活用してプロダクト開発を行っております。
背景
複数のサイトを運営しており、その際のデータを収集するため一部APIリクエストを使用しています
その際に正しい値がPOSTされているかを毎回手動でチェックしていたため
こちらをStep functionsを使用し並列に自動で行うための仕組みを作成しました。
構成
今回はStep functionsのMapがどういうものなのかをわかりやすくするため
数値のListを生成し偶数か奇数かを判定する簡易的なLambda関数を実装し、step functionsで並列処理します
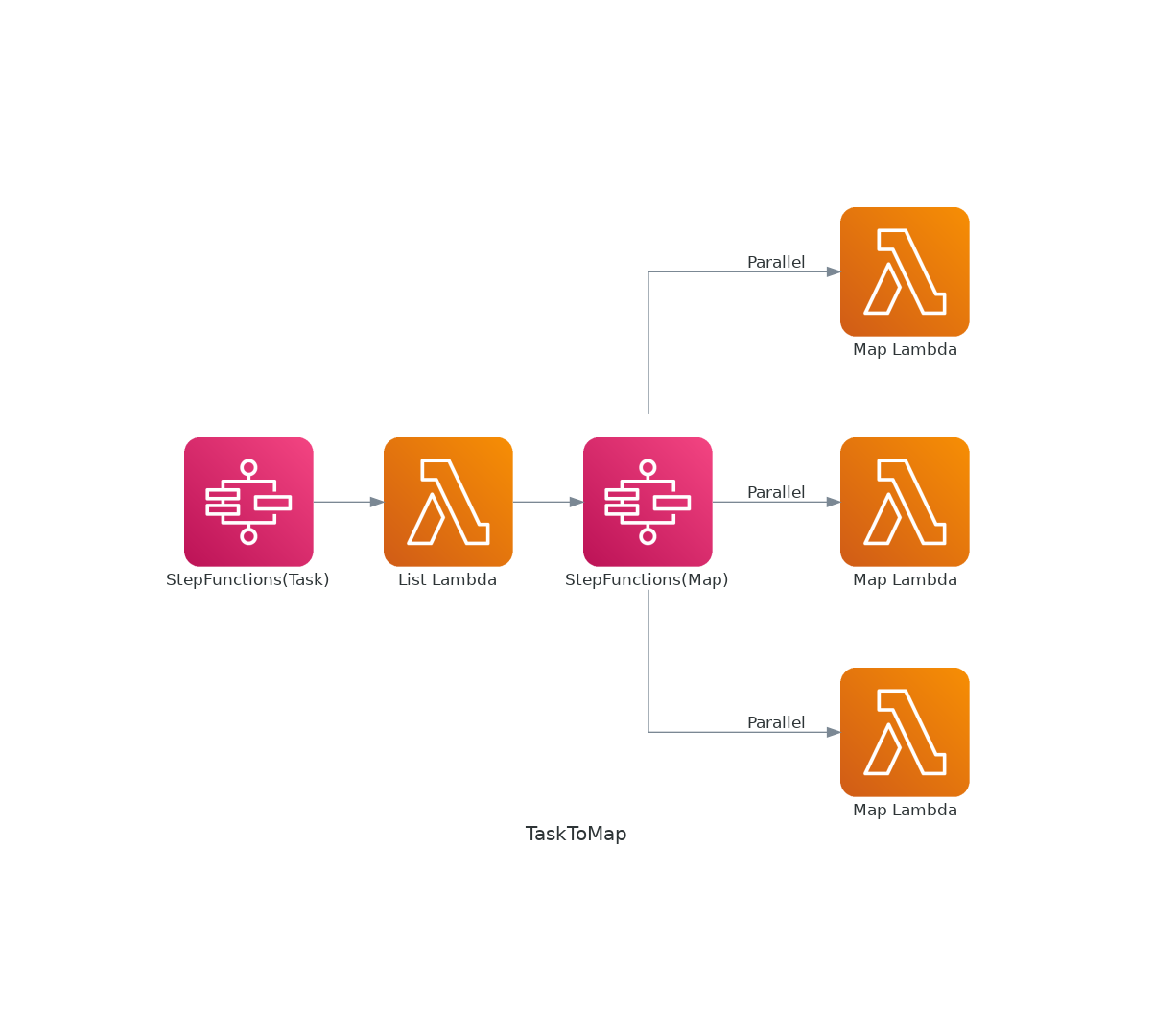
step functions map概要
Map 状態 ("Type": "Map") を使用して、入力配列の要素ごとに一連のステップを実行できます。
Parallel 状態は同じ入力を使用して複数のステップのブランチを実行しますが、
Map 状態は状態入力の配列の複数のエントリに対して同じステップを実行します。
こちらのaws公式ドキュメントの説明通り、入力配列の要素ごとにステップを実行することができ、
Parallelは同じデータに対する実行ですが、Mapは動的な個々(異なる)の値に対してステップを実行することができます。
aws resources作成
terraformで構成を管理書くことが多いのでterraformで作成します
step functionsの内容を定義するjsonファイル
- Statesで実行するlambda関数を定義しそれを実行します
- Nextでは次のステップで実行するtask名を定義します
- Mapの定義自体は通常のTaskと同じように定義します
- Mapのパラメータに関してはlambdaのeventで渡されます
- concurrencyはMapの最大並列実行数です、Lambdaを指定する場合は関数の最大実行数を考慮して設定してください
- Retry/Catchに関してはMap内の処理が一つでも失敗した場合ステートマシン自体が失敗になり処理が中止されてしまうため定義しています。(通常ではここでエラー内容の通知を行っていますが、今回はエラー処理自体をパスします)
- 当然ですがRetryに関してはMap内のみRetryされます
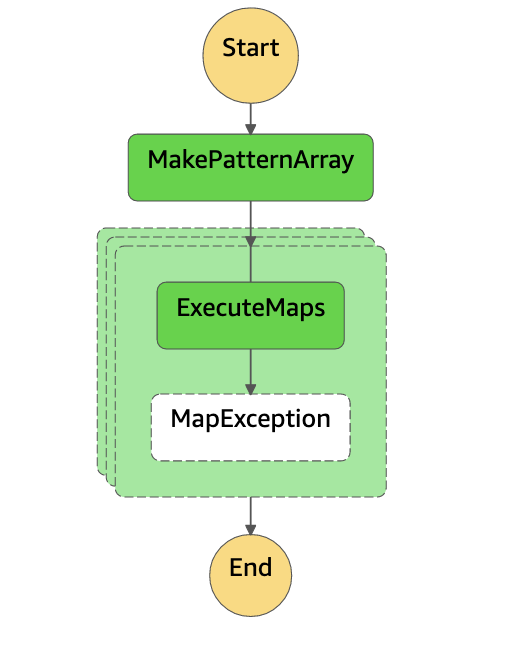
{
"Comment": "state machine",
"StartAt": "MakePatternArray",
"States": {
"MakePatternArray": {
"Type": "Task",
"Resource": "${list_lambda_arn}",
"Next": "ExecuteMap"
},
"ExecuteMap": {
"Type": "Map",
"MaxConcurrency": ${concurrency},
"Iterator": {
"StartAt": "ExecuteMaps",
"States": {
"ExecuteMaps": {
"Type": "Task",
"Resource": "${map_lambda_arn}",
"Retry": [ {
"ErrorEquals": [ "States.ALL" ],
"IntervalSeconds": 2,
"BackoffRate": 2.0,
"MaxAttempts": 3
}],
"Catch": [{
"ErrorEquals": ["States.ALL"],
"Next": "MapException"
}],
"End": true
},
"MapException": {
"Type": "Pass",
"Result": "Error",
"End": true
}
}
},
"End": true
}
}
}
- lambdaやroleなどは別途作成してある想定
data "template_file" "definition_json" {
template = file("definition.json")
vars = {
list_lambda_arn = var.list_lambda_arn
map_lambda_arn = var.map_lambda_arn
concurrency = 10
}
}
resource "aws_sfn_state_machine" "sfn_state_machine" {
name = "${var.step_function_name}-state-machine"
role_arn = aws_iam_role.state_machine_role.arn
definition = data.template_file.definition_json.rendered
}
Lambda関数の定義
数値の配列を返すlambda
exports.handler = async () => {
const response = [291,394,290,111,2,8,10]
return response;
};
上では数値の配列を生成していますがObject自体を返すこともできます。
下記のようにObjectを生成してlambdaのeventをMap側で受け取ることも可能
ただし、渡せるデータ容量には制限があるので注意してください
exports.handler = async () => {
const response = [
{
'aaa': 123
`bbb`: 333
},
{
'aaa': 1231
`bbb`: 3333
}
]
return response;
};
判定するLambda
整数値以外は許容していない、非常に適当な関数ですが...
exports.handler = async (event) => {
if (event % 2 == 0) {
return '偶数'
}
return '奇数'
};
今回はstep functionsのDSL内にて Catch を使用してエラーが発生したものは Passするようになっているため
一部が失敗してもstate machine自体は成功します
state machineを起動する
起動方法はCloudWatch eventやCliなどいろいろありますが、ここではコンソールで起動/実行します
作成したstate machine

作成したstate machineから 実行の開始 を選択肢(パラメータが必要であれば入力/json)すると起動されます。
起動後の画面は上記のグラフインスペクターとLogなどが表示されます。
成功時
成功時はstate machine内のtaskが緑色になります
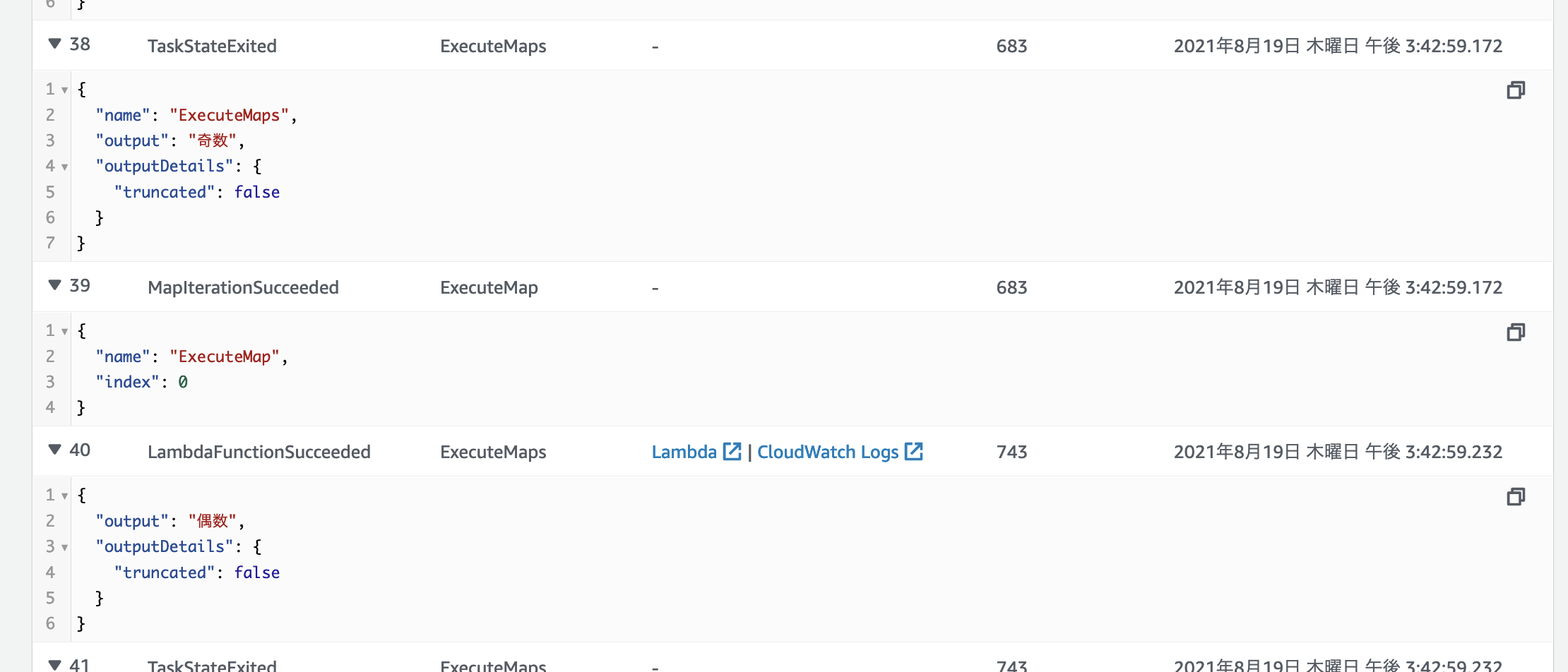
taskの選択もしくは実行イベント履歴からOutputされたデータの確認も可能です
エラー発生時
失敗時は下記の画像のように失敗したtaskが赤くなり、Catch を定義していない場合は
state machine全体が失敗になります。

失敗したtaskを選択もしくは
実行イベント履歴にあるLogからエラー内容を確認することが可能です
まとめ
step functionsのMapを使用することで動的に生成した異なるデータに対して簡単に並列にアプローチをすることができます。一連のworkflowの中で、動的データを並列に処理することができれば、処理の高速化などといったメリットになると思います。
step functionsには他にもいろいろなStatesや様々なawsサービスとの連携も簡単に行うことができ非常に便利なので
workflowエンジンをお考えの際は有力な選択肢としてぜひ一度使ってみてはいかがでしょうか。
データインフラ部では、AWSでのビッグデータ基盤関連の運用を行っており、
Step Functions なども活用したプロダクト開発を行っています。
中途採用などもおこなっておりますので、興味のある方は、一度弊社HPなどから
カジュアル面談など、是非ご応募ください。