2024年3月から、オンライン学習サービスのデータ分析講座や自主学習を通じて、Pythonによる機械学習やデータ分析を中心に、幅広い分野を学習しました。その成果として、取り組んだ内容や成果物をまとめた記事を作成しました。
はじめに
現代のデジタル音楽市場において、音楽推薦システムはユーザー体験を向上させる重要な役割を果たしています。SpotifyやApple Musicなどのストリーミングサービスは、ユーザーが好む楽曲を効果的に推薦することで、多くのユーザーに利用されています。
本記事では、Spotify APIを使用して楽曲データを取得し、機械学習アルゴリズムを用いた音楽推薦システムの構築方法を説明します。具体的には、データの取得、前処理、モデルのトレーニングと評価、そしてユーザーインターフェースの作成までの手順を解説します。
本記事は、データサイエンティスト、機械学習エンジニア、プログラミングに興味がある方、また私と同じくPythonの学習を始めた方へ何らかの参考になればと思い提供します。
フィルタリングの選択
レコメンドアルゴリズムのフィルタリングには大きく分けて、協調フィルタリングとコンテンツベースフィルタリングの二つがあります。
協調フィルタリング
ユーザーの行動データ(評価、再生履歴など)に基づき、類似したユーザーの好みを参考にしてアイテムを推薦する手法。
-
メリット
ユーザーの行動データに基づいて推薦するため、個別の嗜好が反映されやすく、他のユーザーが好む新しいアイテムを推薦できる。 -
デメリット
新規ユーザーや新規アイテムに対してはデータ不足で精度が低下してしまう。
コンテンツベースフィルタリング
アイテムの特徴量に基づき、ユーザーの過去の好みに類似するアイテムを推薦する手法。
-
メリット
アイテムの特徴量を直接使用するため、新規アイテムにも対応しやすく、少量のデータで推薦が可能。 -
デメリット
ユーザーの過去の好みに基づくため、新しいタイプのアイテムの発見が難しく、アイテムの詳細な特徴量が必要。
今回は学習を始めてから初めての制作物ということで、データの入手容易性、実装のシンプルさからコンテンツベースのフィルタリングを選択しました。また、デメリットへの対応としてより多くの特徴量を取り入れ、ユーザーの好みを細かく分析することで、推薦の精度を向上させます。
類似度の計算
このシステムではユーザーが入力した楽曲と他の楽曲の類似度を計算するために cos類似度 を使用します。
cos類似度とは二つのベクトル間の類似度を計算する手法で、ベクトルの内積をそれぞれのベクトルの大きさで割ることで求められます。
cosθ = \frac{⟨x,y⟩}{∥x∥∥y∥}
開発環境
- OS : MacOS Sonoma 14.5
- RAM : 32GB
- 言語 : Python
- Pythonバージョン : 3.9.19
- IDE : Anaconda, PyCharm
使用したライブラリとツール
- spotipy : Spotify Web APIを利用するためのライブラリ。
- requests : HTTPリクエストを送信するためのライブラリ。
- time : 時間に関する操作を行うための標準ライブラリ。
- logging : ログを記録するための標準ライブラリ。
- pandas : データ操作および分析のためのライブラリ。
- numpy : 数値計算のためのライブラリ。
- scikit-learn : 機械学習モデルの構築と評価のためのライブラリ。
- tkinter : GUIを構築するための標準ライブラリ。
- PySimpleGUI : より簡単にGUIを構築するためのライブラリ。
- pyperclip : クリップボード操作のためのライブラリ。
- flask : ウェブアプリケーションを構築するためのフレームワーク。
実装
全体の流れ
1. Anacondaで仮想環境の構築
2. Spotify APIからデータを取得 (spotify_NewHits_features.py)
3. データの前処理 (data_preprocessing.py)
4. 推薦システムの構築 (recommendation_system.py)
5. ユーザーインターフェースの実装(music_recommendation_gui.py)
このようにして、Spotifyの最新ヒット曲を基にした音楽推薦システムが構築されました。各段階での細かな調整と実装を通じて、ユーザーフレンドリーで効果的なシステムを完成させることができました。
1. 仮想環境の構築
最初に行ったのは、Anacondaを使用して仮想環境を構築することです。仮想環境を使用することで、必要なライブラリやツールを管理しやすくなり、システム全体の整合性を保つことができます。
-
Anacondaのインストール
Anacondaのインストールは下記のURLから行えます。
https://www.anaconda.com/download
-
仮想環境の作成
' conda ' コマンドを使用して、新しい仮想環境を作成しました。この仮想環境を作成することで、システム全体に影響を与えずに必要なライブラリをインストールできます。
< music_recommendation_system > は作成する仮想環境の名前です。
conda create -n music_recommendation_system python=3.9.19
-
仮想環境のアクティベート
作成した仮想環境をアクティベートして使用できる状態にします。
conda activate music_recommendation_system
2. Spotify APIからデータを取得
次にPyCharmを使用してデータの収集を行います。
PyCharmは、Python開発に特化した統合開発環境(IDE)であり、コードの編集、デバッグ、実行が簡単に行えます。
-
PyCharmのインストール
PyCharmのインストールは下記のURLから行えます。
https://www.jetbrains.com/ja-jp/pycharm/
-
データ収集スクリプトの作成
PyCharmで新しいプロジェクトを作成し、Anacondaで作成した仮想環境を指定します。
今回は ' spotify_NewHits_features.py 'というスクリプトを作成し、Spotify APIを使用して最新のヒット曲とその特徴量を取得するコードを実装しています。
-
ライブラリのインポートとログの設定
スクリプトの実行状況を把握するため、ログの設定を行っています。
実行には直接関係ありませんが、現在進行形で実行状況の視覚化ができるため最初のうちはオススメです。
# 必要なライブラリのインポート
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import pandas as pd
import time
import logging
# ログ設定
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
-
Spotify APIの設定
Spotify APIの認証情報はSpotify for Developerからリクエストを送ることで取得できます。
https://developer.spotify.com
# Spotify APIの認証情報(実際の値はここでは伏せています)
CLIENT_ID = 'CLIENT_ID'
CLIENT_SECRET = 'CLIENT_SECRET'
# Spotify APIへの認証
sp = spotipy.Spotify(auth_manager=SpotifyClientCredentials(client_id=CLIENT_ID, client_secret=CLIENT_SECRET))
# リクエスト制限に対応するための待機時間(秒)
REQUEST_DELAY = 1 # 通常は1-2秒が適切です
MAX_RETRIES = 3 # 最大リトライ回数
# プレイリストごとにトラックIDを取得
def get_track_ids_from_playlists(playlist_ids, tracks_per_playlist=100):
track_ids = set() # 重複を避けるためセットを使用
for playlist_id in playlist_ids:
playlist_tracks = sp.playlist_tracks(playlist_id, limit=tracks_per_playlist)
for item in playlist_tracks['items']:
track_ids.add(item['track']['id'])
logger.info(f'Playlist ID: {playlist_id}, Tracks fetched: {len(track_ids)}')
time.sleep(REQUEST_DELAY) # リクエスト制限に対応するための待機時間
return list(track_ids)
# トラックの特徴量を取得してデータフレームに保存
def get_track_features(track_ids):
features_list = []
track_info_list = []
total_tracks = len(track_ids)
for i in range(0, total_tracks, 50): # 50件ずつ取得
batch = track_ids[i:i + 50]
for attempt in range(MAX_RETRIES):
try:
features = sp.audio_features(batch)
for feature in features:
if feature: # 有効な特徴量データがある場合
features_list.append(feature)
track_info = sp.track(feature['id'])
track_name = track_info['name']
artist_name = track_info['artists'][0]['name']
track_info_list.append({'id': feature['id'], 'track_name': track_name, 'artist_name': artist_name})
logger.info(f'Processed {i + len(batch)} / {total_tracks} tracks')
time.sleep(REQUEST_DELAY) # リクエスト制限に対応するための待機時間
break # 正常に処理された場合はループを抜ける
except Exception as e:
logger.error(f'Error processing batch {i // 50 + 1}: {e}')
time.sleep(REQUEST_DELAY * (attempt + 1)) # 待機時間を増やして再試行
if attempt == MAX_RETRIES - 1:
logger.error(f'Failed to process batch {i // 50 + 1} after {MAX_RETRIES} attempts')
return pd.DataFrame(features_list), pd.DataFrame(track_info_list)
# プレイリストIDのリスト(日本を中心に人気プレイリストのID 計30, 右側はプレイリスト名)
playlist_ids = [
'37i9dQZEVXbKXQ4mDTEBXq', # Top 50 - Japan
'37i9dQZF1DXafb0IuPwJyF', # Tokyo Super Hits!
'37i9dQZF1DWT8aqnwgRt92', # Anime Now
'37i9dQZF1DWV8IND7NkP2W', # Road Trip To Tokyo
'37i9dQZF1DWX9u2doQ8Q2L', # Tokyo Rising
'37i9dQZF1DXayDMsJG9ZBv', # Hot Hits Japan
'37i9dQZF1DX9vYRBO9gjDe', # Spotify Japan 急上昇チャート
'37i9dQZF1DXbR32Ldau7WM', # Big in Japan
'37i9dQZF1DX6ntWKaOqGAp', # J-Rock Now
'37i9dQZF1DX6UkADhBpEnE', # 元気Booster
'37i9dQZF1DWYBDycFJuxRt', # Nwe Music Wednesday
'37i9dQZF1DXdcuhTbpro3s', # 100MILLION+一億超えヒット
'37i9dQZF1DX4OR8pnFkwhR', # RADAR;Early Noise
'37i9dQZF1DX8XStIuaEA9J', # Teen Culture
'37i9dQZF1DXcBWIGoYBM5M', # Today's Top Hits
'37i9dQZEVXbMDoHDwVN2tF', # Top 50 - Global
'37i9dQZF1DX0XUsuxWHRQd', # Rap Caviar
'37i9dQZF1DX10zKzsJ2jva', # Viva Latino
'37i9dQZF1DWY7IeIP1cdjF', # Baila Reggaeton
'37i9dQZF1DWWMOmoXKqHTD', # Song to Sing in the Car
'37i9dQZF1DX4o1oenSJRJd', # All out 2000s
'37i9dQZF1DXbiEfzyzIRj9', # Altar JP
'37i9dQZF1DWZASvfwxHkco', # mint Japan
'37i9dQZF1DX2vYju3i0lNX', # Chilled jazz
'37i9dQZF1DWZCkamcYMQkz', # Feel Good Jazz
'37i9dQZF1DX5pzlFKAwpZ5', # Ambient Japan
'37i9dQZF1DWWjGdmeTyeJ6', # Fresh Finds
'37i9dQZF1DWTyiBJ6yEqeu', # Top Gaming Tracks
'37i9dQZF1DX3diUVrKEuXr', # Buzz On TV
'37i9dQZF1DWZZbpkxU5t9L', # Weekly Buzz Tokyo
]
# トラックIDを取得
logger.info('Fetching track IDs...')
track_ids = get_track_ids_from_playlists(playlist_ids)
# 特徴量とトラック情報を取得
logger.info('Fetching track features and info...')
df_features, df_track_info = get_track_features(track_ids)
# 特徴量データフレームにトラック情報を結合
df = pd.merge(df_features, df_track_info, on='id')
# 必要な列のみを選択(ここでは全て選択しています)
df = df[['id', 'track_name', 'artist_name', 'acousticness', 'danceability', 'energy', 'valence', 'instrumentalness', 'speechiness', 'tempo', 'loudness', 'mode', 'key', 'duration_ms', 'time_signature']]
# データを保存
df.to_csv('spotify_NewHits_features_with_info.csv', index=False)
logger.info("日本のSpotify楽曲特徴量データがspotify_NewHits_features_with_info.csvに保存されました。")
無事出力が完了すると下記のような csv ファイル (一部抜粋) が保存されます。
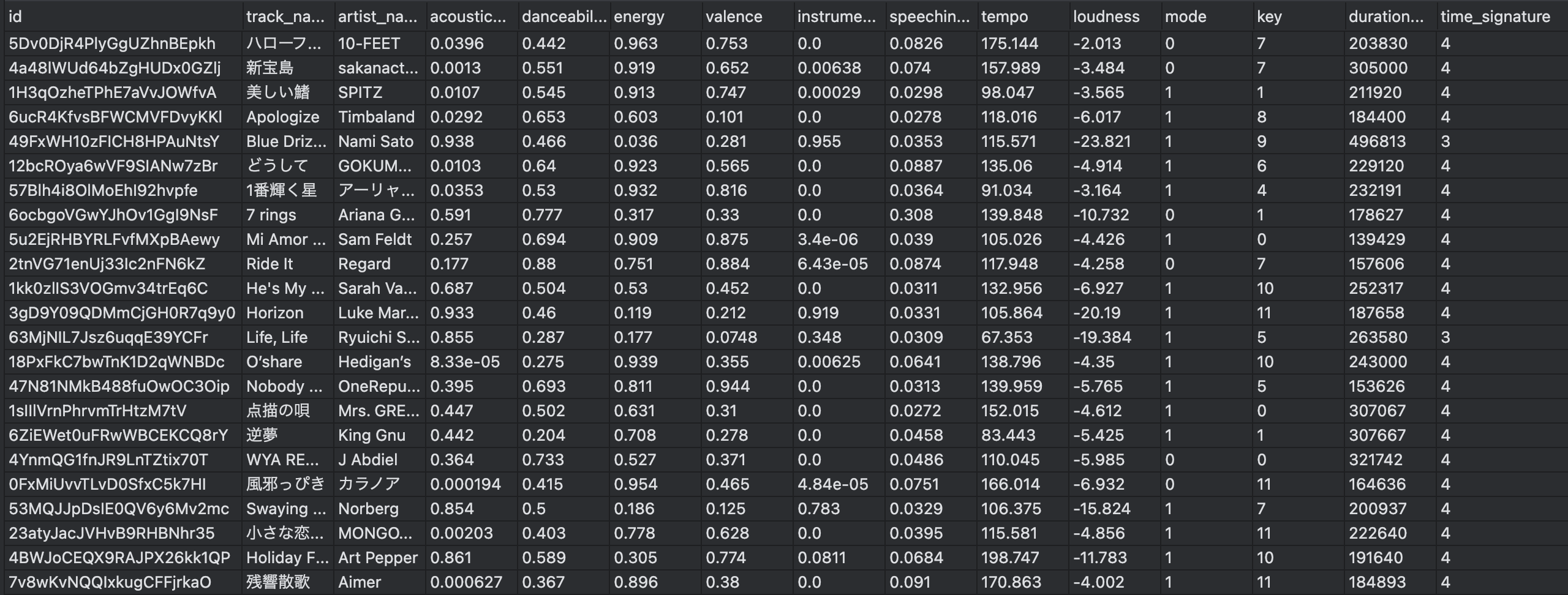
3. データの前処理
# 必要なライブラリのインポート
import pandas as pd
from sklearn.preprocessing import StandardScaler
# データの読み込み (前項で作成したcsvファイル)
df = pd.read_csv('spotify_NewHits_features_with_info.csv')
# データの内容を確認
print("元のデータの最初の5行:")
print(df.head())
# 欠損値の確認
print("\n欠損値の確認:")
print(df.isnull().sum())
-
特徴量の選択
今回は6種類の特徴量を元にレコメンドしています。なぜこの6種類を選んだかというと、他の特徴量と類似性が少なく音楽の特性を効果的に捉えることができると考えたからです。各特徴量の詳しい説明はSpotify for developersの公式サイトをご参照ください、
https://developer.spotify.com/documentation/web-api/reference/get-audio-features

# 必要な特徴量の選定 (今回は6種類を選択)
features = df[['acousticness', 'danceability', 'energy', 'valence', 'instrumentalness', 'speechiness']]
# 特徴量の内容を確認
print("\n選定した特徴量の最初の5行:")
print(features.head())
# 特徴量のスケーリング
scaler = StandardScaler()
features_scaled = scaler.fit_transform(features)
# スケーリング後のデータをデータフレームに保存
df_scaled = pd.DataFrame(features_scaled, columns=['acousticness', 'danceability', 'energy', 'valence', 'instrumentalness', 'speechiness'])
df_scaled.to_csv('scaled_spotify_features.csv', index=False)
print("\nスケーリング後のデータの最初の5行:")
print(df_scaled.head())
無事出力が完了すると下記のような csv ファイル (一部抜粋) が保存されます。
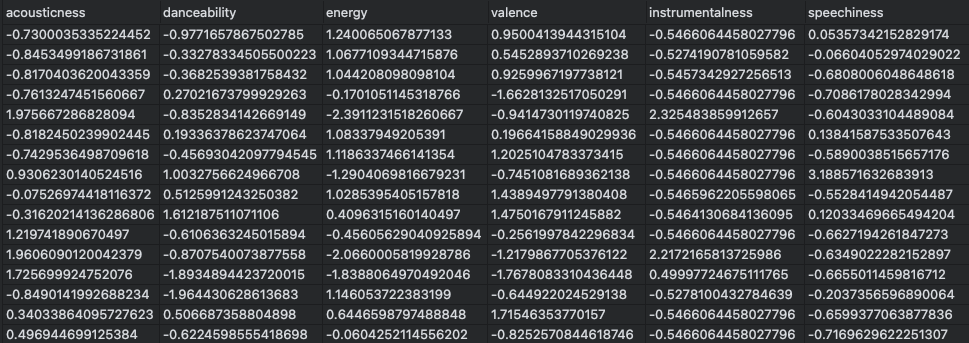
4. 推薦システムの構築
# 必要なライブラリのインポート
from flask import Flask, request, jsonify
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# Flaskアプリケーションのインスタンスを作成
app = Flask(__name__)
# 楽曲特徴量データの読み込み
df = pd.read_csv('scaled_spotify_features.csv')
df_original = pd.read_csv('spotify_NewHits_features_with_info.csv') # 元のタイトルを取得するためのデータ
# 特徴量を選択
features = df[['acousticness', 'danceability', 'energy', 'valence', 'instrumentalness', 'speechiness']]
# コサイン類似度の計算
cosine_sim = cosine_similarity(features)
# 楽曲タイトルとインデックスの対応付け
df['title'] = df_original['track_name']
df['artist'] = df_original['artist_name']
df['track_url'] = df_original['id'].apply(lambda x: f"https://open.spotify.com/track/{x}")
indices = pd.Series(df.index, index=df['title']).drop_duplicates()
-
楽曲推薦関数の定義
指定された楽曲タイトルに基づいて類似度の高い楽曲を推薦する関数を定義します。この関数は、コサイン類似度に基づいて最も類似度の高い10曲を推薦します。
def recommend_songs(title, cosine_sim=cosine_sim):
if title not in indices:
return []
idx = indices[title]
# 類似度スコアのリストを作成
sim_scores = list(enumerate(cosine_sim[idx]))
# 類似度スコアに基づいてソート
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 最も類似度が高い10曲を取得
sim_scores = sim_scores[1:11]
# 元のデータフレームから推薦曲のインデックスを取得
song_indices = [i[0] for i in sim_scores]
# 推薦曲を表示
recommendations = df[['title', 'artist', 'track_url']].iloc[song_indices]
return recommendations
-
Flaskルートの設定
recommendエンドポイントを定義し、楽曲タイトルをクエリパラメータとして受け取り、推薦結果をJSON形式で返します。
@app.route('/recommend', methods=['GET'])
def recommend():
title = request.args.get('title')
recommendations = recommend_songs(title)
return recommendations.to_json(orient='records')
-
Flaskアプリケーションの実行
Flaskアプリケーションをデバッグモードでポート 例)0000 で実行します。
if __name__ == '__main__':
app.run(debug=True, port=0000)
ここまででシステムは完成です。
これにより、ユーザーは特定の楽曲タイトルを指定して、その楽曲に似た他の楽曲を推薦するWebアプリケーションを利用することができます。
GUIを作成せずに実行する場合、Flaskアプリケーションを起動し、コマンドラインまたはPythonスクリプトからHTTPリクエストを送信して推薦結果を受け取る方法があります。これにより、GUIなしで推薦システムを動作させることができますが今回はPySimpleGUIを使ってGUIも作成します。
5. ユーザーインターフェースの実装
-
GUIの作成
今回は簡易的なGUIを作成するため、PysimpleGUIを使用します。
初回は30日間無料で使えるため、はじめて利用する際は無料期間をうまく活用することをオススメします。
# 必要なライブラリのインポート
import PySimpleGUI as sg
import requests
import pandas as pd
import pyperclip
# GUIレイアウトの定義
layout = [
[sg.Text('楽曲タイトルを入力してください')],
[sg.Input(key='-TITLE-')],
[sg.Button('検索')],
[sg.Text('おすすめの楽曲情報')],
[sg.Table(values=[], headings=['No.', 'Track Name', 'Artist', 'Track URL'], key='-TABLE-', auto_size_columns=True, enable_click_events=True, expand_x=True, expand_y=True)],
[sg.Text('クリックしたURLがここに表示され、クリップボードにコピーされます:'), sg.Input(key='-URL-', readonly=True, text_color='white')]
]
# ウィンドウの作成
window = sg.Window('Music Recommendation System', layout, resizable=True, finalize=True)
- イベント処理
1. ウィンドウが閉じられた場合
2. 検索ボタンがクリックされた場合
3. テーブル内のURLがクリックされた場合
# イベントループ
table_data = []
while True:
event, values = window.read()
print(f"Event: {event}, Values: {values}") # デバッグ情報を追加
if event == sg.WINDOW_CLOSED:
break
if event == '検索':
title = values['-TITLE-']
if title:
response = requests.get(f'http://111.0.0.1:0000/recommend?title={title}')
if response.status_code == 200:
recommendations = response.json()
table_data = [[idx + 1, rec['title'], rec['artist'], rec['track_url']] for idx, rec in enumerate(recommendations)]
window['-TABLE-'].update(values=table_data)
print(f"Table Data Updated: {table_data}") # デバッグ情報を追加
elif isinstance(event, tuple) and event[0] == '-TABLE-':
row = event[2][0]
col = event[2][1]
print(f"Row: {row}, Column: {col}") # デバッグ情報を追加
print(f"Table Data: {table_data}") # デバッグ情報を追加
if row is not None and col == 3: # Track URL列がクリックされた場合
url = table_data[row][col]
window['-URL-'].update(value=url)
pyperclip.copy(url) # URLをクリップボードにコピー
print(f"Copied URL: {url}") # デバッグ情報を追加
window.close()
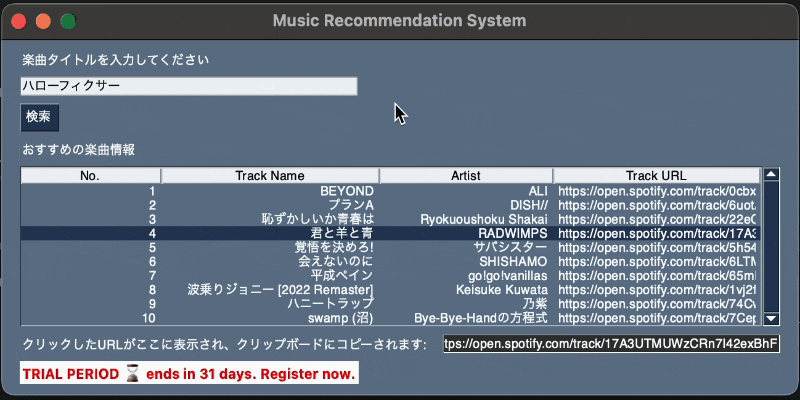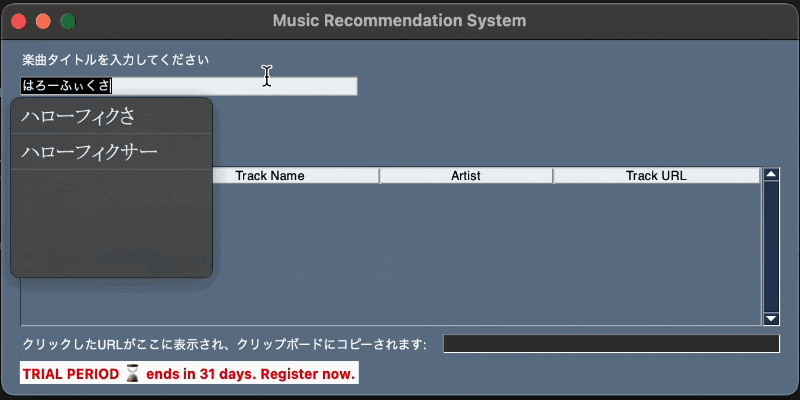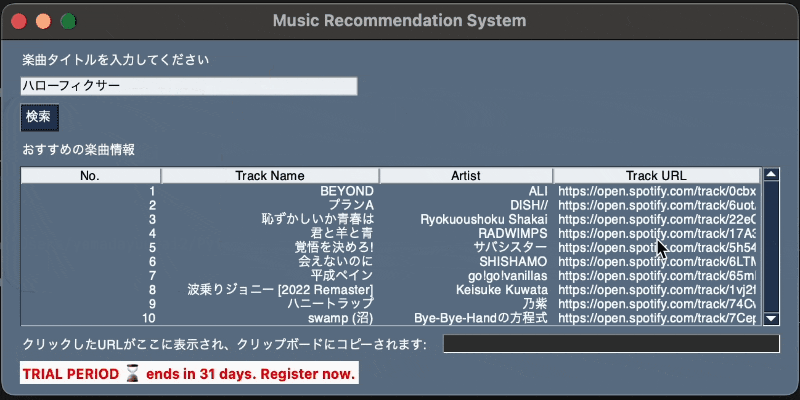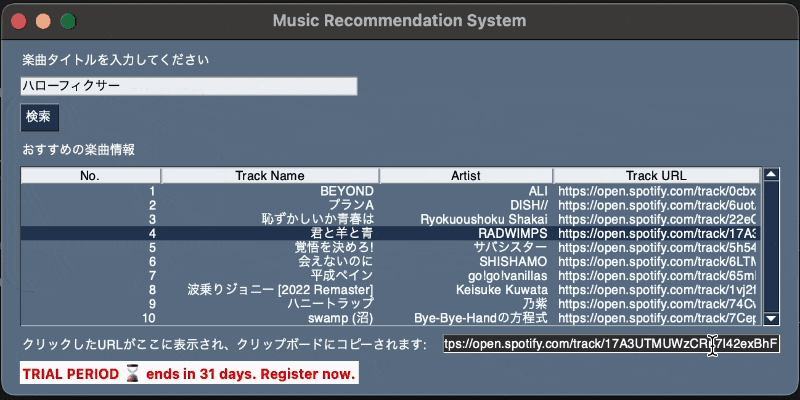
6. 使用例
楽曲タイトルを入力して検索し、HTTPリクエストを介して取得した推薦楽曲をテーブルに表示するシンプルなGUIアプリケーションです。
テーブル内のURLをクリックすることで、そのURLをクリップボードにコピーし、ウィンドウ内に表示する機能も備えています。
おわりに
今回のシステムではコンテンツベースフィルタリングを使用し、ユーザーの行動データを取り入れた協調フィルタリングや他のフィルタリングの実装は行いませんでした。そのため、ユーザーの多様な好みや新しい楽曲の発見が難しいという課題が残りました。
しかし、コンテンツベースフィルタリングではユーザーが過去に聴いたことのないジャンルやアーティストの楽曲も特徴に基づいて推薦するため、新しい音楽の発見が促進されます。また、個々の特徴量(例:テンポ、エネルギー、ダンスアビリティ)を細かく調整することで、ユーザーの好みに合わせた高度なカスタマイズが可能というメリットを確認することができました。そして、コンテンツベースフィルタリングは、ユーザーの個人データや他のユーザーとの相互関係を利用しないため、最初に作る制作物としてはデータの漏洩リスクが低くなるという安心もあります。
次にレコメンドシステムを作る際は、協調フィルタリングとコンテンツベースフィルタリングを組み合わせたハイブリッドフィルタリングを導入し、より高精度でユーザーの嗜好に合った幅広いアイテムの推薦を行えるようにしたいです。また、GUIの実装において、基本的な機能は実装できましたが、ユーザーエクスペリエンスの向上のため、推薦結果の視覚的な表示や、プレイリストの保存、共有機能の実装をするとより良いシステムになると考えます。
ここまで読んでいただきありがとうございました。