Gemmaについて
Gemma は Google が開発した軽量なオープンモデルファミリーです。

Gemini との違い
Gemini は Google が開発したマルチモーダルな生成AIモデルです。
大きくは、 Gemini がマルチモーダルなのに対し、Gemma は基本としてはテキストに対応しています。その代わり Gemma は軽量でオープンソースとして使えるため、研究開発には向いています。
2024年12月時点の両者の比較になります。
| 特徴 | Gemma | Gemini |
|---|---|---|
| モデル | 軽量、オープンソース | 大規模、商用 |
| 利用用途 | 開発や研究など | 高度な研究やアプリケーション向け |
| サイズ | 2~27B | 1.56T |
| アクセス | 改変、再配布可能 | Google APIやGoogle Cloudで利用 |
| 互換性 | TensorFlow、PyTorch、JAXなど | Google独自のインフラ、ツールに対応 |
| チューニング | インストラクション・チューニング | 多くのリソースが必要 |
※"B"は10億(Billion)、"T"は1兆(trillion)
Llamaへの対抗
これはオープンソースな LLM として Mata 社の Llama と比較されることがあります。
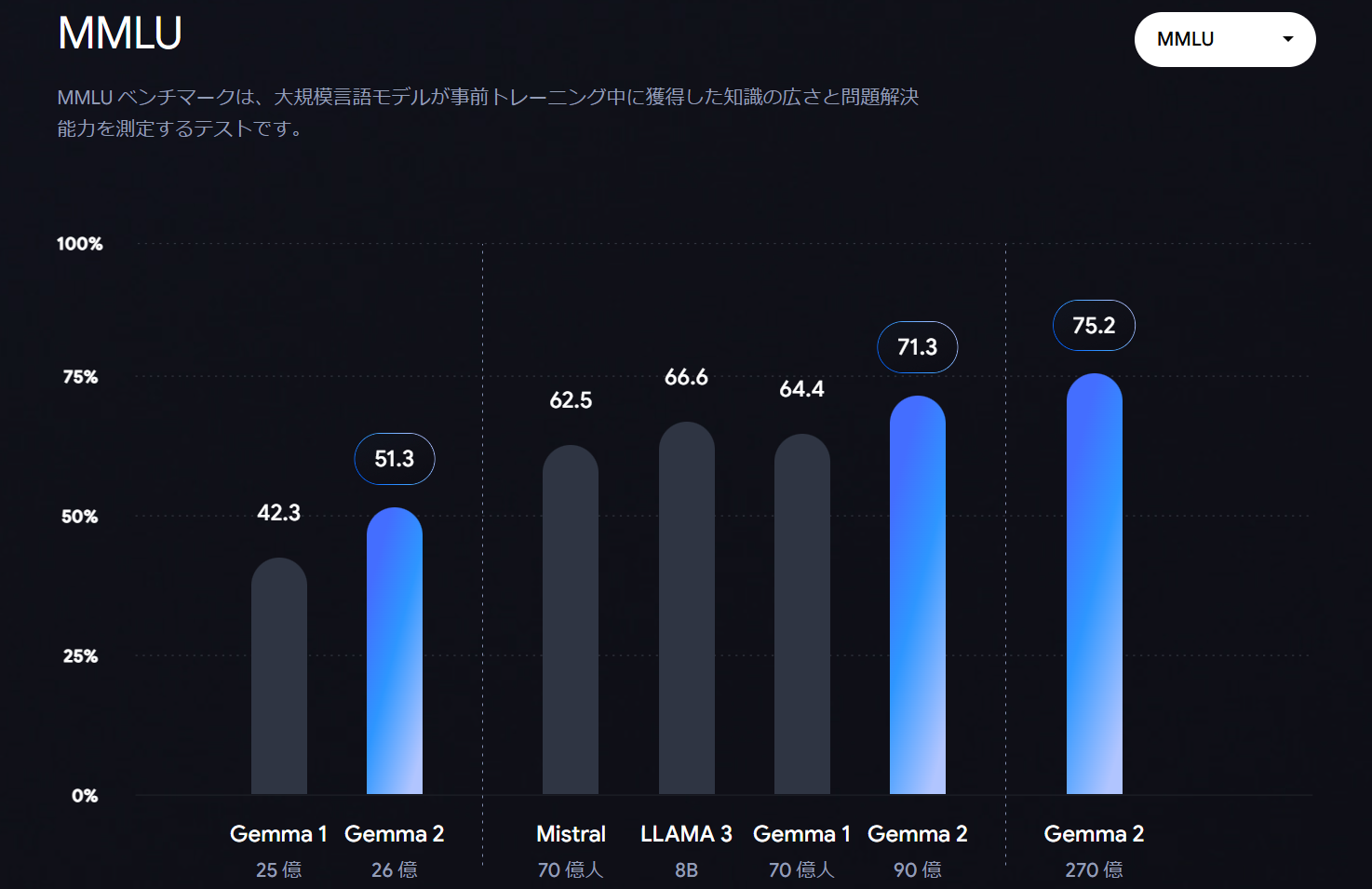
パラメータ数や MMLU というベンチマークで Llama や Mistral を超えることが示されています。
ファミリーとは
Gemma にはファミリーモデルと呼ばれる派生モデルがあります。
1. PaliGemma:
視覚言語モデル(VML)。オートセグメンテーションなどができる
2. RecurrentGemma:
長い文章に対応したモデル。Griffin をベースにしている
3. DataGemma:
ハルシネーション対策を目的としたLLM。ナレッジとしてData Commons と連携している
4. CodeGemma:
コード生成に特化したLLM
日本語モデルを使うには
日本語のモデルは "jpn" が付いています。他にも韓国語などがあります。
リソースは HuggingFace が充実しています。
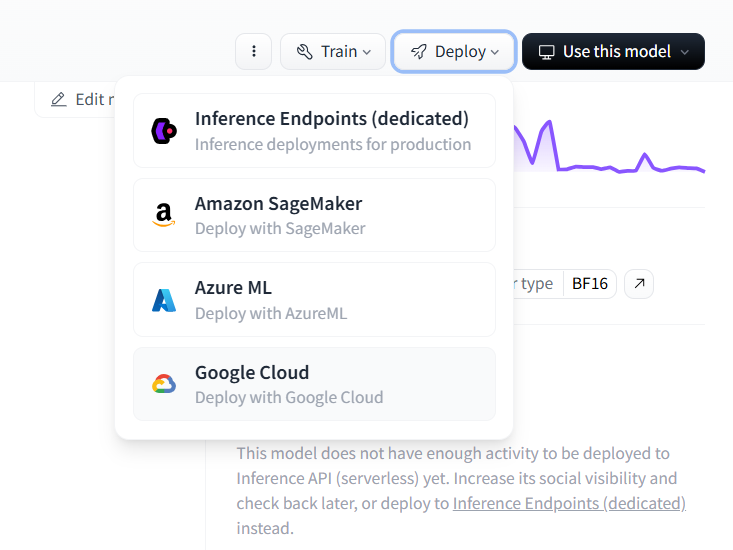
デプロイ方法は現在4パターンです。今回は Inference Endpoints について説明します。
Inference Endpoints
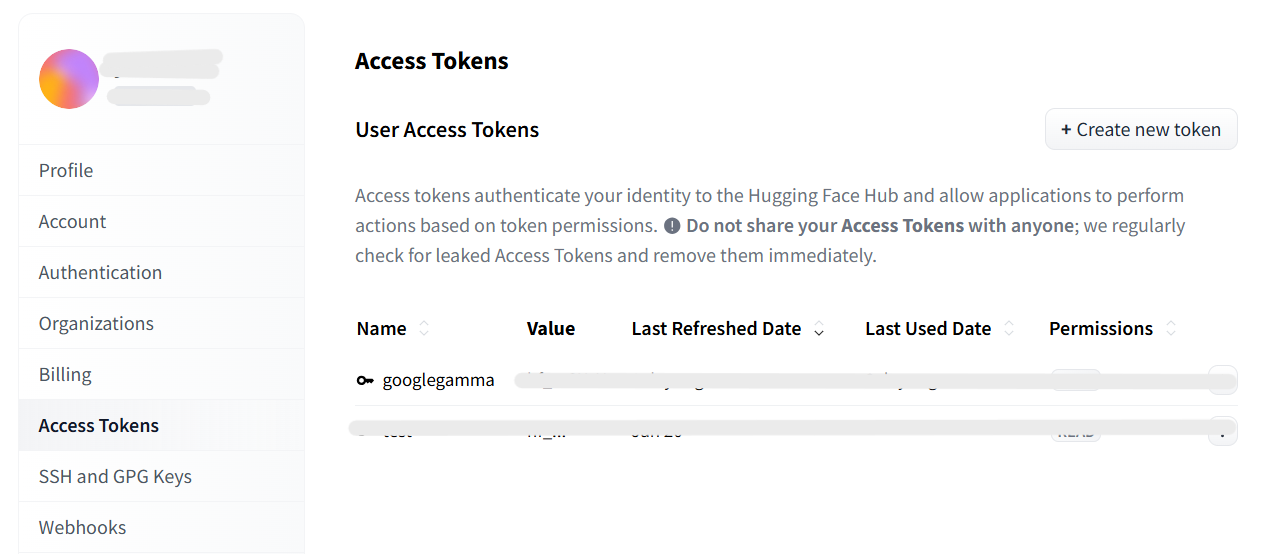
まずは HuggingFace の Access Token を取得しておきます。
先ほどモデルのページからdeploy→Inference Endpoint(dedicated)へと進みます。
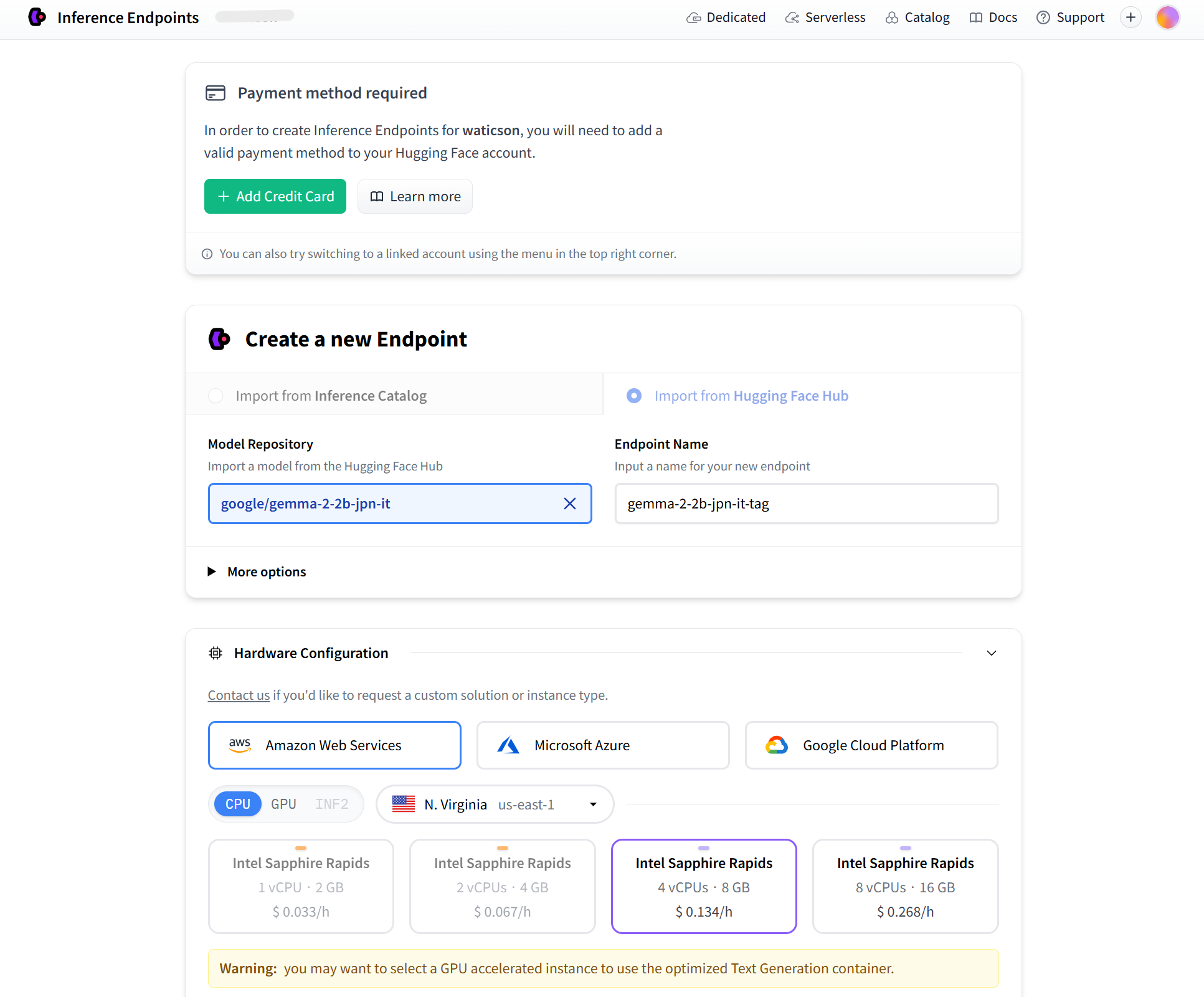
このような画面からエンドポイントを使うのに必要な設定していきます。
- 決済情報:クレジットカード情報を入れます
- マシンの選択:AWSやAzureなどの計算リソースを選びます
他にもこまごました設定がありますが初めての場合はいじらなくて大丈夫です。
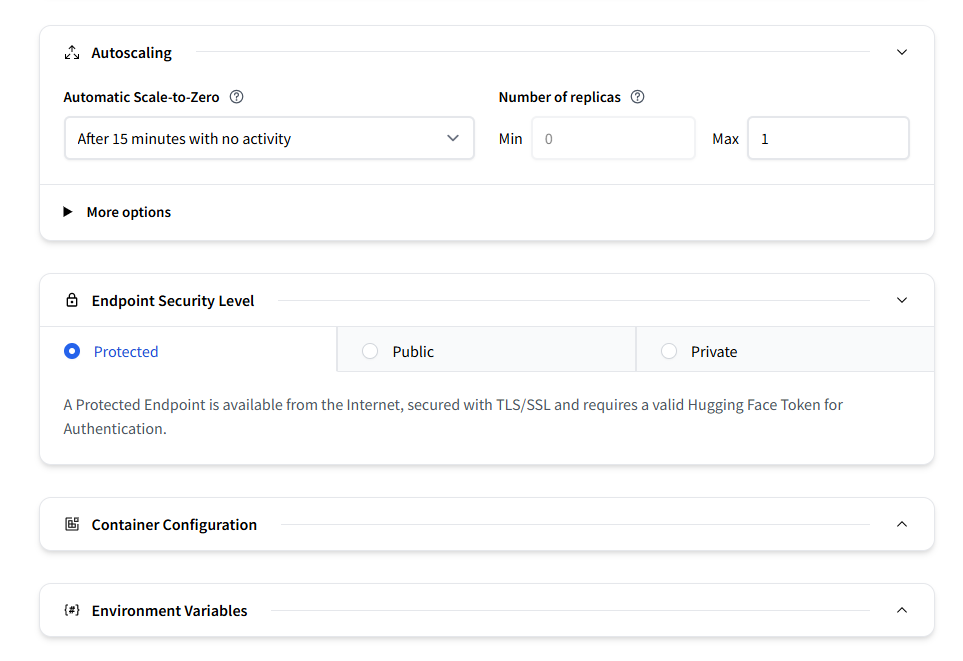
設定が終わると、Endpointの準備をします。
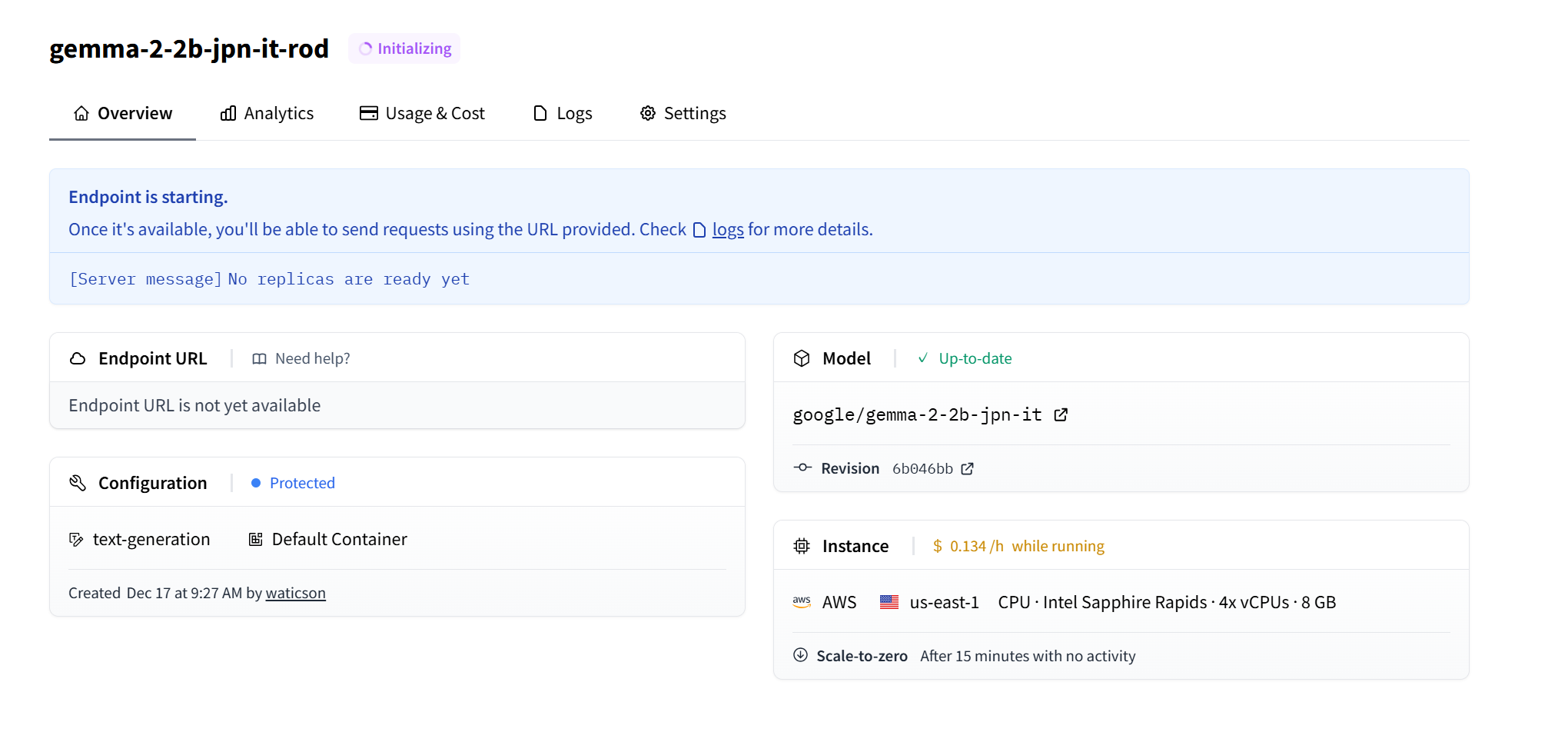
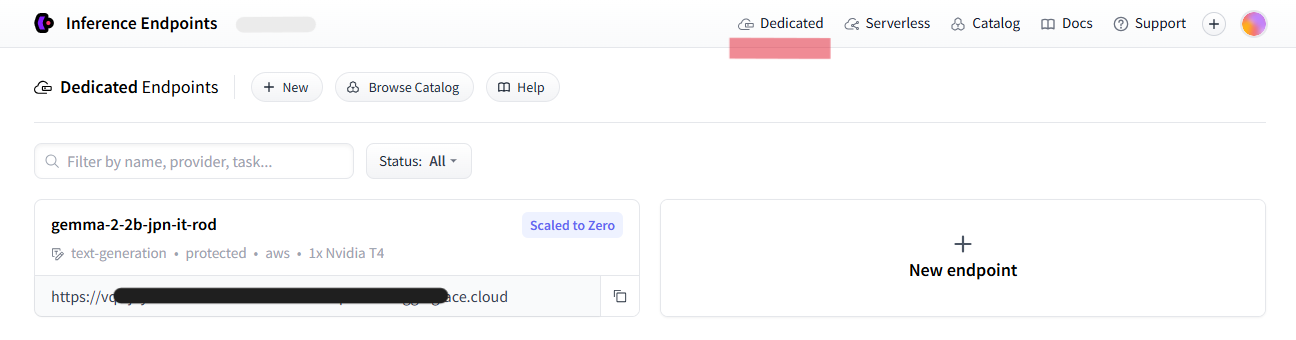
完了したら早速エンドポイントを使うことができます。
サンプルコード
# 取得したエンドポイント
API_URL = "https://XXXXXXXXXXXXXXXX.aws.endpoints.huggingface.cloud"
headers = {
"Accept" : "application/json",
"Authorization": "Bearer hf_XXXXXXXXXXXXXXXX", # HuggingFaceのアクセストークン
"Content-Type": "application/json"
}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload,verify=False )
return response.json()
おまけ: Kaggler は kaggle アカウントがあれば使える!
こちらの指示に従ってライセンスを取得します。
登録できると自由に Notebook で使うことができます。
Kaggle上に限らず、Google Colaboratory でも Kaggle のシークレットキーを設定すれば扱うことができます。
import os
from google.colab import userdata, drive
# vars as appropriate for your system.
os.environ["KAGGLE_USERNAME"] = userdata.get("KAGGLE_USERNAME")
os.environ["KAGGLE_KEY"] = userdata.get("KAGGLE_KEY")