Hugging Face のデプロイ方法を確認しよう
Hugging Face を使ってみたい方にも参考にしていただけます🤗
Hugging Face は AI モデル版 GitHub のようなオープンソースプラットフォームです。
Llama のような LLM や Speech-to-Text の Whisper、Text-to-Image の StableDiffusion など様々な機能のモデルが公開されています。
最近何かと話題の DeepSeek AI も。
使い方はモデルのページに丁寧に説明されていることが多いですが、今回見ていくのは Deploy の部分になります。

Inference API
デプロイオプションに Inference API というものがあります。
これは Hugging Face 謹製のホスティングサービスで、モデルを REST API として簡単に利用できます。この方法なら、Hugging Face の API キーさえあれば OK です。

2025年1月28日には、他のホスティングサービスと Inference Providers という名前で統合されました。
他は fal, Replicate, Sambanova, Together AI など
ただし、これに対応しているモデルは限られています。
Inference Endpoints とは
Inference Endpoints も、Hugging Face が提供するホスティングサービスです。
特徴は、専用の環境で動作させるため、パフォーマンス向上に向けたカスタマイズが可能 なことです。
具体的には以下の通りです。
- どのクラウドを使うか
- どの計算リソースを使うか
- セキュリティレベル


Inference API は制限付きで無料であることが多いですが、こちらは従量課金制です。

使い方
1.決済方法の設定
まずは、Hugging Face で決済方法が登録されていない場合は、こちらを登録します。先述した通り、従量課金制のため必要になります。

準備ができたら Hugging Face で使いたいモデルのページのデプロイオプションから Inference Endpoints を選びます。

2.クラウドサービスと計算リソースの選択
AWS や Azure、GCP などが使えます。計算リソースは金額にかかわってくるので、ページ下部に出てくる金額を見ながら選んでください。
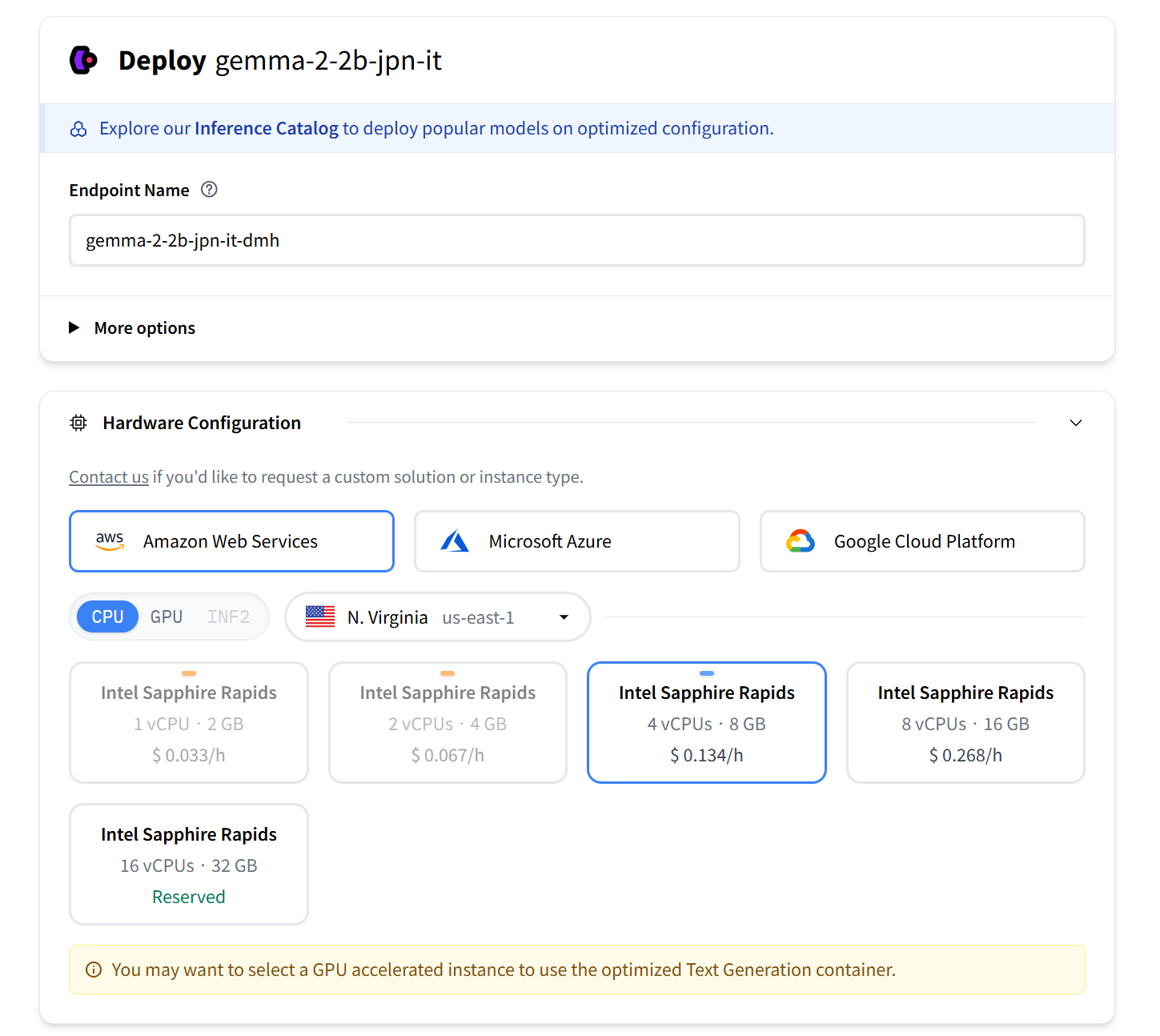
セキュリティレベルは迷ったら Protected で良いでしょう。

3.エンドポイントの作成
エンドポイントのページに遷移し初期化を始まります。
完了すると Endpoint URL が与えられます。
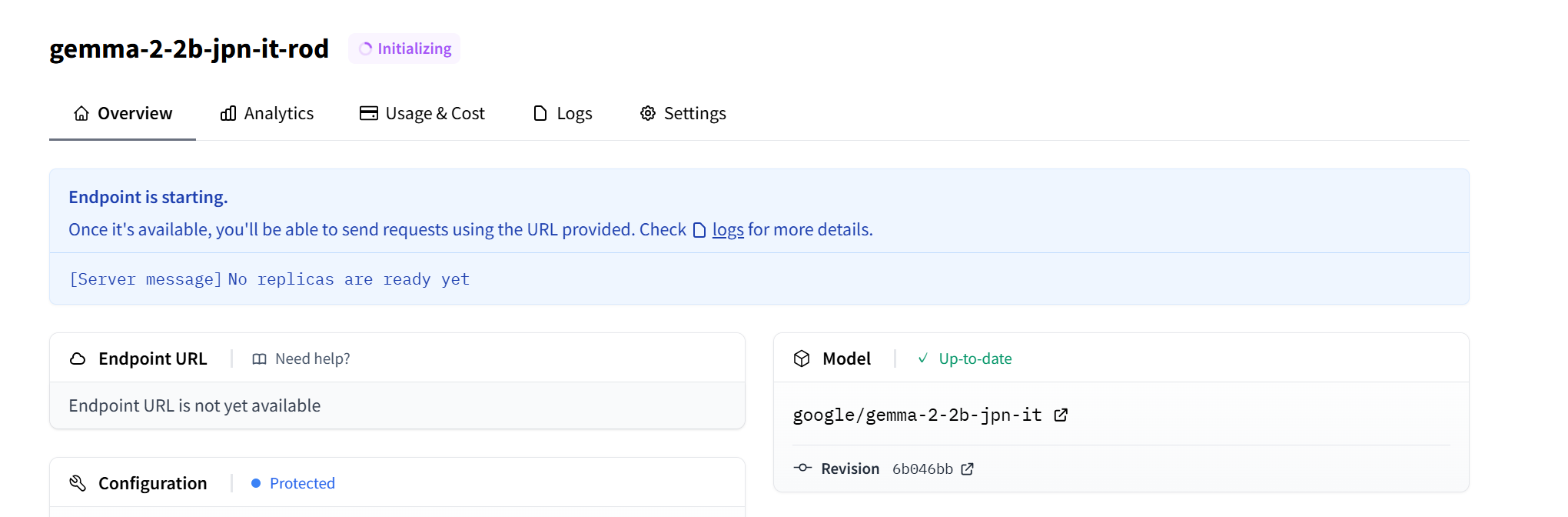
同ページにテストや API の実装例を参考にしコードに組み込みましょう。

以上で終わりです!
参考
Inference Endpoints から Gemma の日本語版モデルを使って食事管理アプリをつくった事例を紹介します!