動画生成などコンピュータービジョンに関するLLMの論文を2つ紹介します。
1. きめ細かなストーリーテリングビデオの生成「DreamRunner」
2. 拡散モデルを使用して4Dであらゆるものを作成する
きめ細かなストーリーテリングビデオの生成「DreamRunner」
DreamRunner: Fine-Grained Storytelling Video Generation with Retrieval-Augmented Motion Adaptation
入力されたテキストに沿ったビデオの生成、SVG(Story Telling Generation) をより質高く行うことができる生成手法「DreamRunner」が発表されました。
GitHubでサンプル動画を観ることができます。
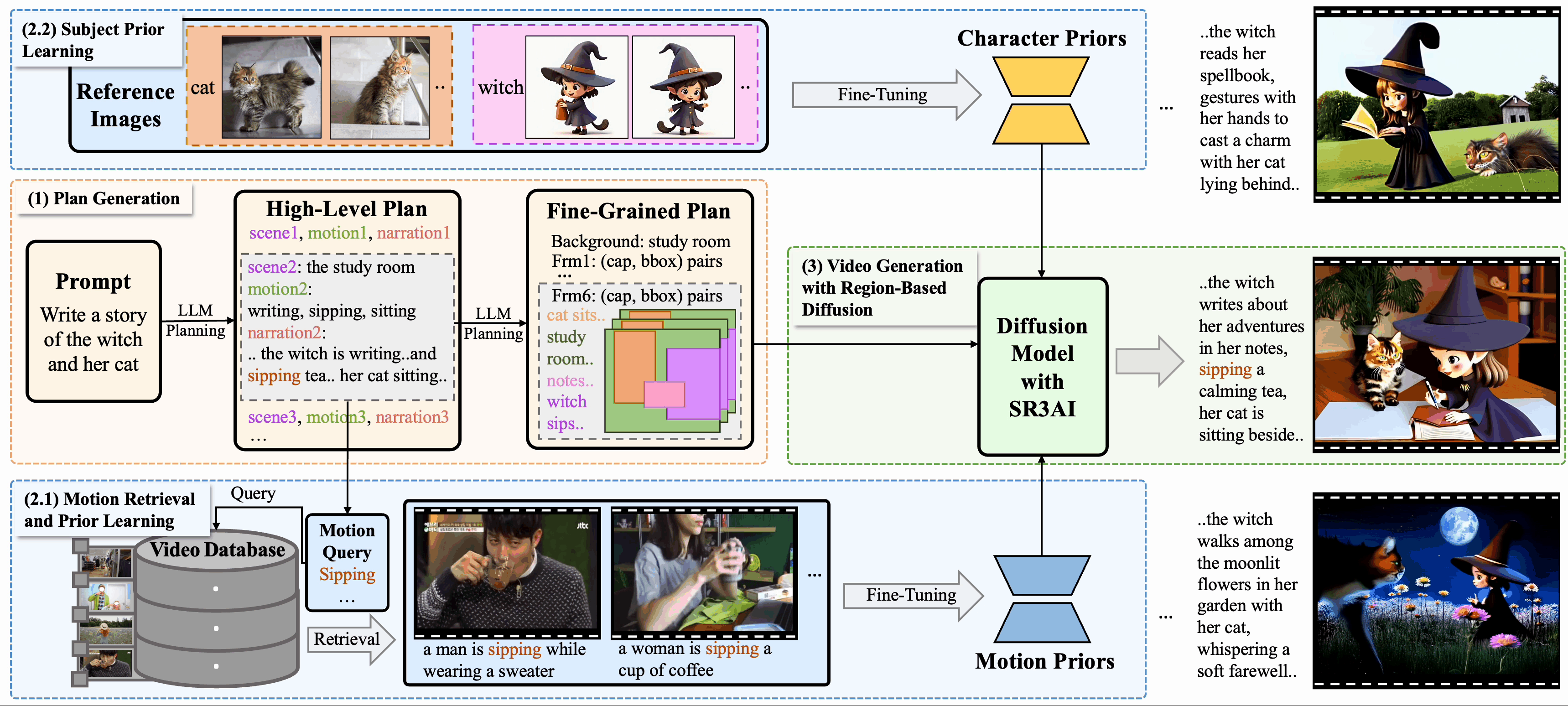
これまでのSVGには次のような課題がありました。
- 様々なオブジェクトがあり、その動きを再現しなければいけない
- 複数のオブジェクトが一貫してシーン内に存在する
- 被写体が一つのシーンで複数のモーションを必要とする
この課題に対して、大きく3つの工夫をしました。
- シーンのプランニングとモーションのプランニングの両方を実施するためのLLMを用意し入力するテキストを構成する
- 各シーンのモーションに対応するための検索(Retrieval Augmented)を行う
- 各シーンのオブジェクトをフレーム単位で認識するSR3AIをモジュールとして使う
オブジェクトやシーンに一貫性のある動画をつくることができます。
一番下がDreamRunnerです!


拡散モデルを使用して4Dであらゆるものを作成する
CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models
まずはここで動画を観るとわかりやすいです!1視点の動画をマルチビューにすることができます。
リンクはこちらです。
これはCAT4Dというモデルで、単眼の入力映像からダイナミックな3Dシーンをつくることができます。

2つのステップによってこのようなスムーズなマルチビューを実現しています。
- マルチビュー映像の拡散モデルを使い、マルチビュー映像に変換
- 3次元ガウス表現を最適化し、動的な3Dシーンに再構築
参考
各arXiv論文はこちらです。
- DreamRunner: Fine-Grained Storytelling Video Generation with Retrieval-Augmented Motion Adaptation
- CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models