🧮FLOPs とは?
Floating Point Operations Per Second の略で「1秒あたりの浮動小数点演算の最大回数」を指します。
簡単に言うと、3.1415 などの小数点を含む数値の演算を 1 秒間にどれだけ実行できるか、といった指標です。この用語は、大学の情報工学系のカリキュラムなどで取り扱うことがあると思います。
この記事では FLOPs に関する以下の内容を紹介します。
- LLM (大規模言語モデル) のパフォーマンスとどのように関わるか
- GPU が LLM をトレーニングするにはどれくらいの時間がかかるか
🧠LLM のパフォーマンスとどのように関わるか
当然と言えば当然のようですが、重み、入力、勾配など LLM の内部で行われる演算には小数を扱うため、FLOPs は LLM の性能に影響します。

重み付けなどに代表されるパラメータ数は、GPT などの賢いモデルで数千億や数百兆などの単位です。とにかくとてつもない数の小数が出てきます。
シンプルですが、さらに深く、なぜ重みなどこれらの値は小数(実数)なのかをこちらに補足しました。
🔍 気になる方は読んでください
パラメーターは連続値であり、学習で微細に調整されます。
どのようにパラメータを調整するかと言えば、誤差の関数の勾配(微分)を利用して誤差が最も小さい場所を探します。実際には以下のような曲線全体が見えているわけではないため、コンピューター目線では暗闇の中を手探りで坂を下っていくように移動します。

また、連続的な関数が多用されます。
例えば、ソフトマックス関数のように指数関数や割り算は当然小数の計算になります。
softmax(x_i)=exp(x_i)/Σexp(x_j)
例えば、こちらの記事によるとNvidia の Geforce RTX 4090 の FP32 (32ビット浮動小数点形式) での理論性能は 82.6 TFLOPsです。Geforce RTX 3090 は 35.6 TFLOPs なので2倍強差があることになります。
TFLOPs の「T」はテラです。

TFLOPs は1秒間辺り数兆回の演算回数です。この単位は現代のゲームや AI 用 GPU の標準です。
PFLOPs (ペタ FLOPs ) ともなればスーパーコンピュータや大規模 GPU クラスターの規模となります。
FLOPs は浮動小数点の取り方でも変わる
演算の精度( bit 数)が高くなるほど、1回の演算に必要な回路リソースや処理時間が増えるため、同じ GPU や CPU でも FP32 より FP64 では FLOPs は下がることがほとんどです。
以下は Nvidia H100 のスペックシートです。

🧐ただし実際の計算速度や実効性能を完全に反映するわけではない
FLOPs はあくまでも理論的な小数点演算の最大回数です。実行速度には以下の観点も関わってきます。
| 観点 | 内容 |
|---|---|
| 実行効率(MFU) | 実際のアプリケーションでは全ての演算ユニットがフル稼働しない |
| メモリ帯域 | メモリ速度(帯域幅) |
| 実アプリ依存 | 実際のタスクによる演算密度やメモリアクセス |
| 他の処理との競合 | キャッシュ処理、分岐処理、IOなど |
⏱️GPU が LLM をトレーニングするにはどれくらいの時間がかかるか
計算式
OpenAI などの研究で特定の LLM をトレーニングするために必要な FLOPs の総数を推定するための経験則が公表されています。
Total
Training FLOPs ≈ 6 × N × D
意外と簡単な式ですね!
N : モデル内のパラメータの数。例えば、GPT-4 には100兆個、GPT-3 には 1750 億個のパラメータがあります
D : トレーニングデータセット内のトークン (単語またはサブワード) の数
✅補足:定数の内訳
学習には順伝搬と逆伝搬という2つの主要なプロセスがあります。順伝搬は入力値を使って予測値を算出し、逆伝搬では予測値との誤差を使って重みを調整します。
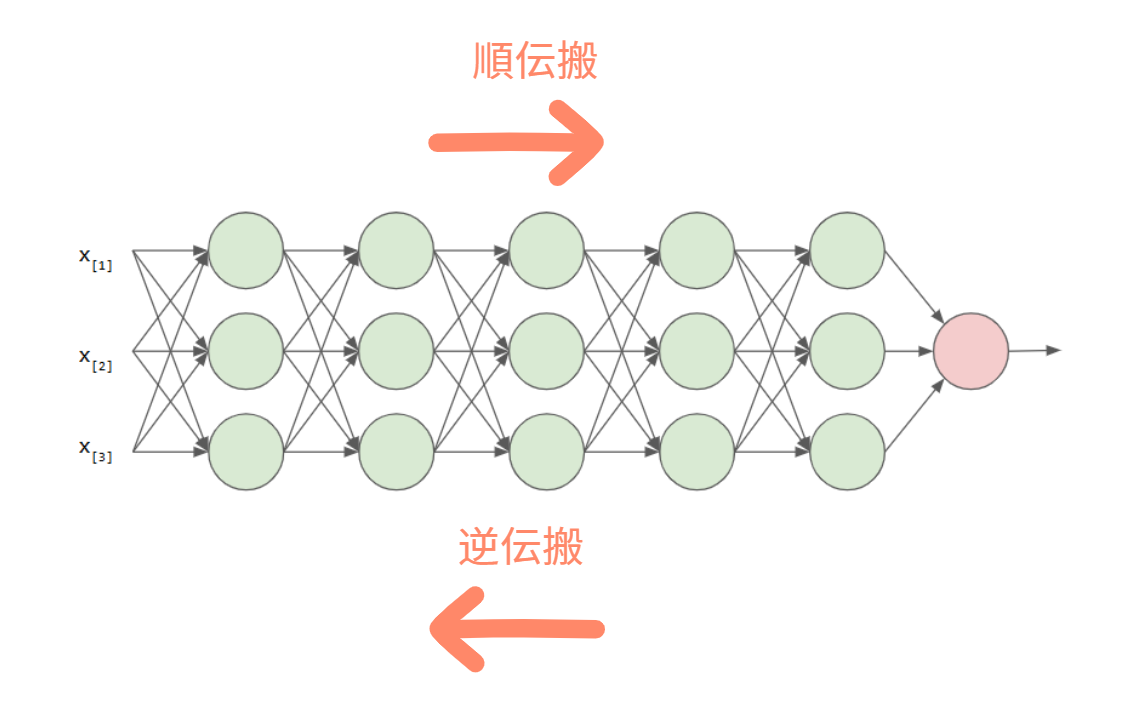
- 順伝搬 (出力の計算) 中に処理されるトークンごと、およそ2 × N 回の演算 (パラメーターごとに 1 回の乗算と 1 回の加算) が必要
- 逆伝搬(誤差と勾配の計算)は計算負荷が高く、経験則的におよそ順伝搬の 2 倍の演算が必要
| ステップ | FLOPs 概算 |
|---|---|
| 勾配の逆伝播 | 1 N |
| パラメータの勾配計算 | 2 N |
| 活性化関数の逆伝播 | 1 N |
- 合計でトークンあたり2N + 4N = 6N 回の演算
GPT-4 のトレーニング時間
GPT-4 の FLOPs
Epoch AI の記事によると以下の通りと言われています。
総 FLOPs = 2.15 × 10^{25}
※ 21.5 YottaFLOPsと言うようです。
1つの GPU を使用した時にトレーニングにかかる時間
LLM のトレーニングでは、特化した Tensor コアが担う混合精度のパフォーマンスが重要です。
先述した H100 の場合、以下となります。
1,979 TFLOPs(1.979 × 10¹⁵ FLOPS)
したがって理論値では以下のようになります。
(2.15 × 10^{25}) / (1.979 x 10^{15}) ≈ 1.09× 10^{10} 秒 ≈ 346年
さらに、H100 でのトレーニングの実行効率 (MFU, Model FLOPs Utilization) を考慮します。20~45% という報告があったため、控えめに45%で計算した場合は以下のようになります。
346年/0.45≈ 809年
これが、企業が大量の GPU を並列に実行してスーパーコンピュータを構築する根本的な理由ですね。つまり、何百年かかるプロジェクトを数か月で完了させるためです。
🔗参考
- GPT-4 のトレーニングコスト
- 混合精度について
- MFU について
- ニューラルネットワークの図示