生成 AI モデル大きすぎ、重すぎ問題
現在、Hugging Face Transformers などには高性能なモデルが数多く存在するため、すぐに推論を試したくなるかもしれません。しかし、これらのモデルを実際に導入したことがある人ならわかる通り、落とし穴があります。
最先端のモデルは、多くの場合、大量のメモリ、処理能力、そして時間を必要とします。特にリアルタイム応答が求められるアプリケーションや、モバイル端末やエッジデバイスなど、リソースが限られたデバイスで実行する必要があるアプリケーションにとっては、大きな制約となります。
例えば、Hugging Face Transformers のモデルをそのままfrom_pretrained()で動かすと、
「GPU 積んでるのに重くないか...?」
と思うことがあります。

from_pretrained()とは?
Hugging Face の Transformers ライブラリ における超重要なメソッドの1つです。事前学習済みモデルを1行で読み込むことができる便利な関数です。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
そのような悩みに対して Hugging Face が「Optimum」という高速化フレームワークを用意しています。
この記事では、Optimum に関連する以下のことを紹介します。
- どれくらい推論を軽量・高速化できるのか?
- グラフ最適化・量子化とは何か?
🏎️どれくらい推論を軽量・高速化できるのか?
結論
DistilBERT モデルの最適化に関するベンチマークのレポートによると精度を維持したまま2.3倍の高速化を達成していました。

また、Hugging Face 自体も様々な事例を紹介しています。(リンク記事の趣旨はこんなこともできます!という紹介です)
roberta-base-squad2 を最適化した事例では、同様に2倍程度高速化していました。
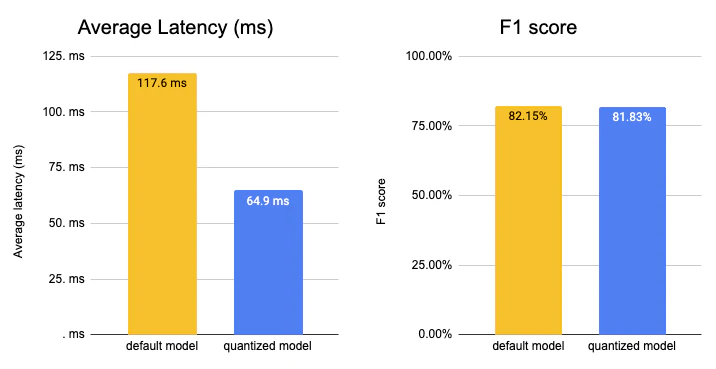
当然、モデルや条件によってもどれだけ高速化できるかは変わりますが、十分実行する価値がありますね。
実行手順
Optimum の中で提供されているオープンソースフレームワークの中の ONNX Runtime を使用します。

ONNX Runtime は、ONNX 形式の AI モデルを速く・効率よく実行するためのエンジンです。演算子融合 (operator fusion) や定数畳み込み (constant folding) といったモデルを最適化する機能があります。
ONNX とは?
ONNX (Open Neural Network Exchange)は、機械学習モデルを異なるフレームワーク間で交換・利用可能にするためのオープンなフォーマットです。例えば、PyTorch でトレーニングしたモデルを ONNX 形式にエクスポートし、TensorFlow にインポートすることができます。演算子融合について
複数の演算処理を1つの演算にまとめることで、コードの効率化や最適化を図る技術です。
このようなONNXグラフがあったとします。
x → [Mul] → y → [Add] → z
演算子融合をすると次のようになります。
x → [FusedMulAdd] → z
1つの計算ユニット(カーネルやノード)にまとめ、実行効率を上げます。
定数畳み込みについて
実行時に変わらない「定数の計算」は、あらかじめコンパイル時などに先に計算しておく最適化手法です。
以下のような計算があったとします。
int x = 10;
int y = x + 3 + 5;
3 や 5 は定数なので毎回加算する必要がないため以下のようにします。
int x = 10;
int y = x + 8;
使用環境の準備
ドキュメントはこちらです。ONNX Runtimeを指定します。
pip install optimum[onnxruntime] onnx
依存関係も含めたい場合はこちらを実行します。
pip install --upgrade --upgrade-strategy eager optimum[onnxruntime] onnx
モデルのエクスポートと最適化
Transformers モデルを ONNX 形式に変換します。ここでは Hugging Face Hub から事前学習済みの DistilBERT を読み込みます。
from optimum.exporters.onnx import main_export
main_export(
model_name_or_path="distilbert-base-uncased",
output="./onnx_model",
task="sequence-classification",
optimize="O2"
)
optimizeのオプションは ONNX Runtime によるグラフ最適化レベルを指定します(O1〜O3で高いほど積極的に最適化)
推論用モデルの量子化
量子化については後半で説明します
ONNX モデルを量子化(int8化)します。quantization-approachは量子化手法を指定し(詳しくは後述します)、他の部分はディレクトリの指定のみです。
optimum-cli onnxruntime quantize \
--model ./onnx_model \
--quantization-approach dynamic \
--output ./onnx_model_quantized
コード自体はシンプルです。
推論コード
ORTModelForSequenceClassification は ONNX Runtime 用の分類モデルクラスです。また、.from_pretrainedでモデルやトークナイザーを使用します。
計算が終了するまでの時間を表示するためのサンプルコードを紹介します。
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import AutoTokenizer
import time
model = ORTModelForSequenceClassification.from_pretrained("./onnx_model_quantized")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
inputs = tokenizer("This is a test sentence.", return_tensors="np")
start = time.time()
outputs = model(**inputs)
print("Latency:", time.time() - start)
このような手順でモデルを試すことができます!ぜひ Hugging Face で探してみてください🤗
🧪グラフ最適化・量子化とは何か?
なぜ、Hugging Face Optimum や ONNX Runtime を使って計算が高速化されるのは、このグラフ最適化や量子化といった処理が使われているためです。
グラフ最適化
グラフとは?
何のグラフ?と思うかもしれませんが、これは、ノードとエッジで表現した計算グラフのことで、モデル内部の演算処理(例:MatMul、Add、ReLUなど)はこのように表現されます。
これを効率化することで、不要な演算を減らし、キャッシュヒット率や並列処理効率を高めることができます。
ひとつ前のセクションで紹介した演算子融合や定数畳み込みに加え以下のような手法がよく使われます。
| 最適化手法 | 説明 |
|---|---|
| デッドノードの除去(Dead Code Elimination) | 出力に使われないノードを削除 |
| 形状推論(Shape Inference) | 実行前にテンソルの形状を確定して実行効率を向上 |
| Layout変換(NHWC ⇄ NCHW) | GPU向けに適したデータレイアウトに変換 |
量子化
量子とは?
量子と聞くと量子力学の量子(エネルギーや物質の最小単位)を想像するかもしれませんが、実は別物です。
コンセプトは似ているのですが、工学的にいうと「連続な値をある幅(量子単位)ごとに区切る」ことを量子化と言います。
どんな処理なのか?
AI 分野においては、モデルが持つ重みやアクティベーション(中間出力) の数値表現のビット数を減らすことで、軽量化と高速化を実現します。
通常のモデルは float32(32 bit 浮動小数点) で演算しますが、量子化により int8(8 bit 整数) や float16(16 bit 半精度浮動小数点) に変換し、推論速度やバッチ処理性能を向上させます。
この浮動小数点と計算時間に関しても記事を書いたので、気になる方は最後にリンクを載せていますので是非ご覧ください!
数学的には、スケール、オフセットを使って整数に写像することで量子化できます。
q=offset+round(x/scale)
ここで、scale は float32 の範囲と int8 の範囲を合わせる係数、オフセットは整数表現でのゼロの位置です。
代表的な量子化手法は以下の通りです。Dynamic Quantizationは上述したサンプルコードで実施している量子化手法です。
| 手法名 | タイミング | 特徴 |
|---|---|---|
| Dynamic Quantization | 推論時に動的変換 | 精度は良く手軽に導入可 |
| Static Quantization | 推論前に事前変換 | キャリブレーションデータが必要だが高速 |
| Quantization Aware Training (QAT) | 学習時から量子化を考慮 | 高精度を維持しやすいが再学習が必要 |
| GPTQ / AWQ / GGML | 4bit 量子化手法(LLM専用) | LLaMA、Qwen、Mistralなどで活用 |
🔗参考
- Hugging Face Optimum
- ONNX Runtime
- ONNX Runtime の高速化
- 浮動小数点と計算時間