ダミー変数化(ワンホットエンコーディング)で配列がぐちゃぐちゃになる
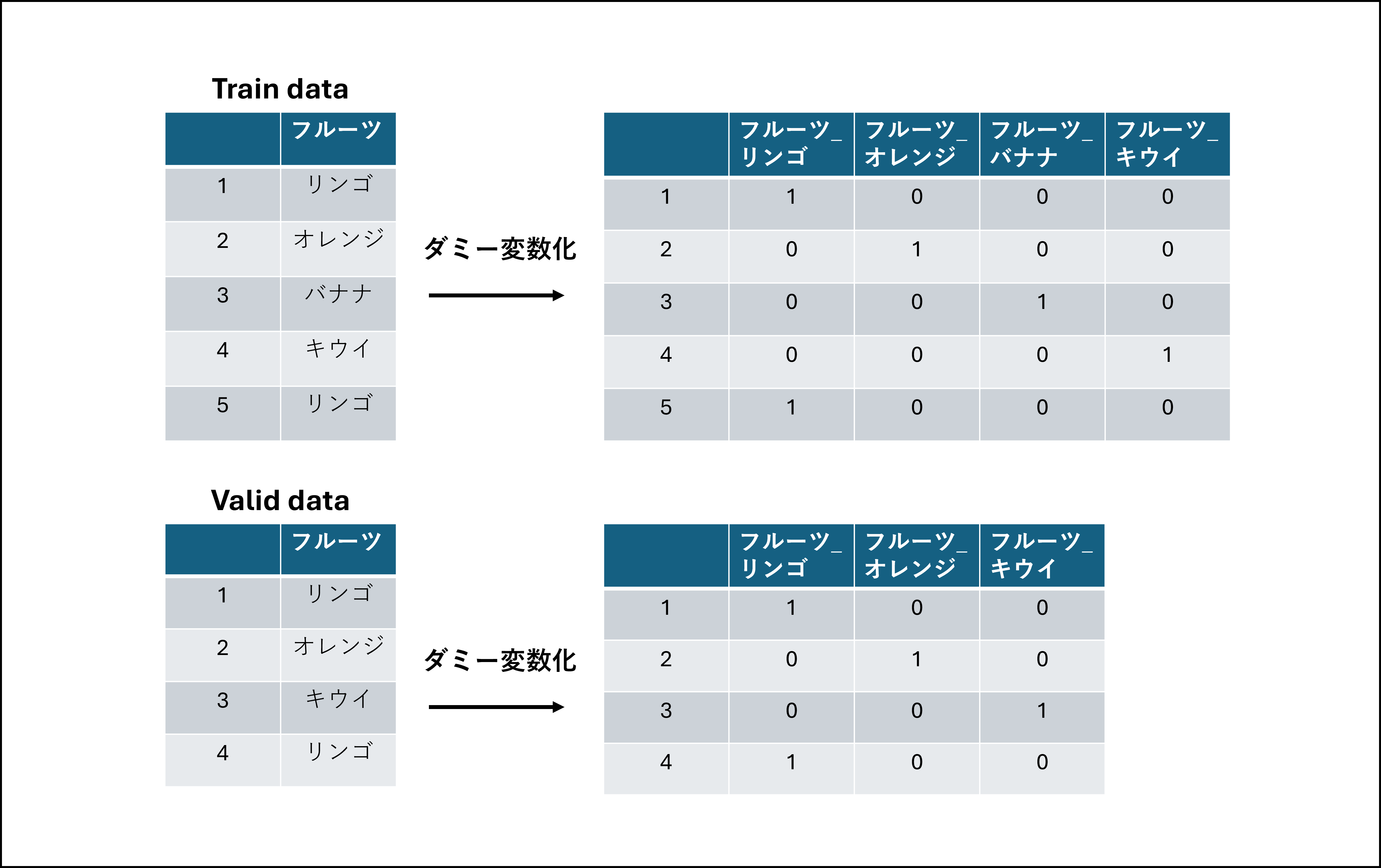
カテゴリ変数をダミー変数化すると、ユニークな値の数に応じて変数を増やすことができます。配列としては列数が増えることになります。
冒頭の図のように、教師データと検証データ、テストデータに対して個々にダミー変数化を行うと、ユニークな値が共通しない時に配列が揃いません。
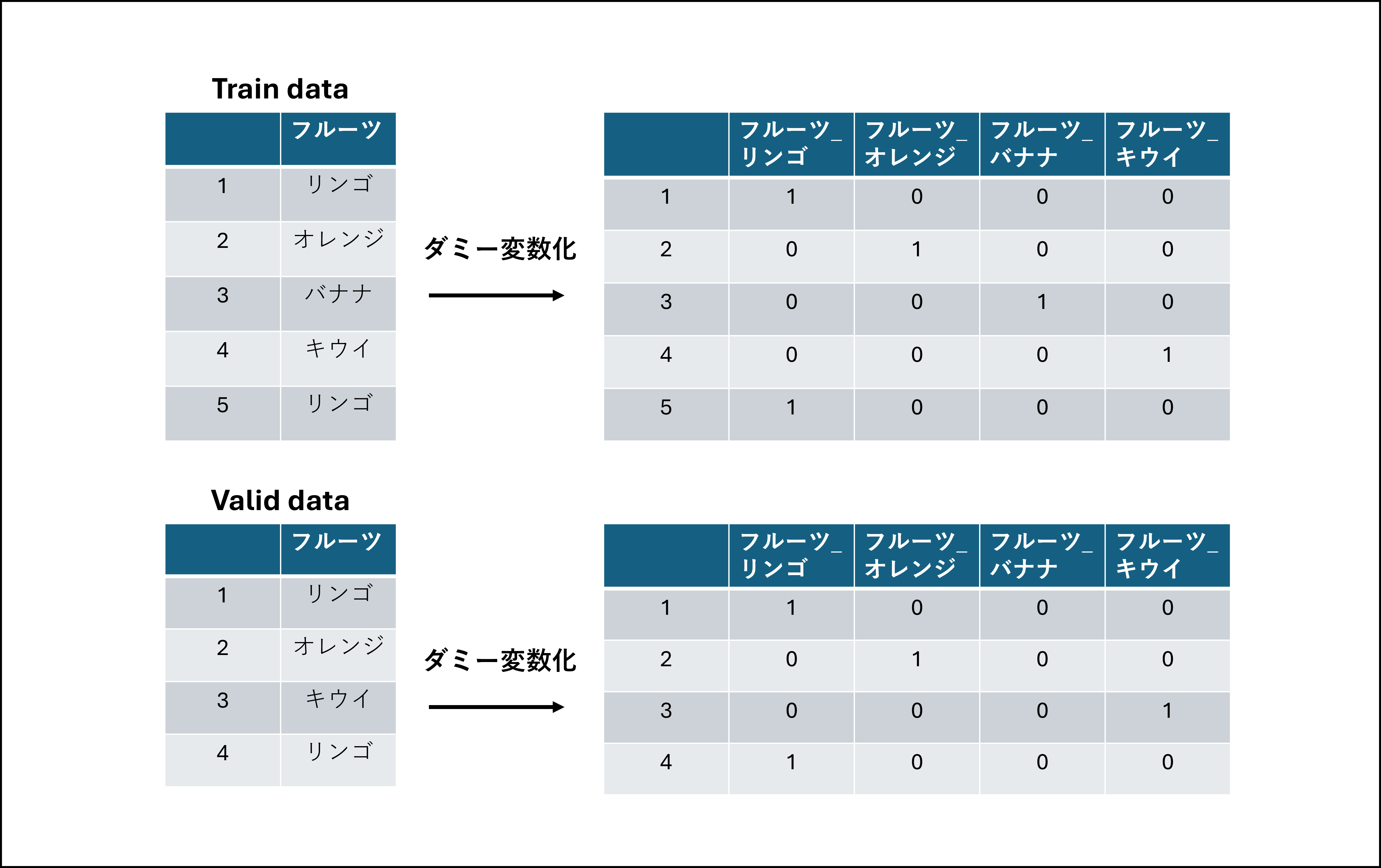
そこで、以下の図のように、ユニークな値が異なる場合でも、列の数と順番が合うような処理を解説します!
問題設定
題材として、Kaggleのこちらのコンペデータを使ってみます。ローンの返済能力の予測がテーマのコンペです。
本題までの細かい前処理はこちらにまとめました。
まず、教師データと検証データの列数は48個ずつで等しいです。
[in]
print(f"Train: {X_train.shape}")
print(f"Valid: {X_valid.shape}")
[out]
Train: (915995, 48)
Valid: (305332, 48)
教師データのカテゴリ変数は13個あります。
[in]
print(X_train.dtypes)
[out]
amtinstpaidbefduel24m_4187115A float64
annuity_780A float64
annuitynextmonth_57A float64
avginstallast24m_3658937A float64
avglnamtstart24m_4525187A float64
avgoutstandbalancel6m_4187114A float64
avgpmtlast12m_4525200A float64
credamount_770A float64
currdebt_22A float64
currdebtcredtyperange_828A float64
disbursedcredamount_1113A float64
downpmt_116A float64
inittransactionamount_650A float64
lastapprcommoditycat_1041M category
lastapprcommoditytypec_5251766M category
lastapprcredamount_781A float64
lastcancelreason_561M category
lastotherinc_902A float64
lastotherlnsexpense_631A float64
lastrejectcommoditycat_161M category
lastrejectcommodtypec_5251769M category
lastrejectcredamount_222A float64
lastrejectreason_759M category
lastrejectreasonclient_4145040M category
maininc_215A float64
maxannuity_159A float64
maxannuity_4075009A float64
maxdebt4_972A float64
maxinstallast24m_3658928A float64
maxlnamtstart6m_4525199A float64
maxoutstandbalancel12m_4187113A float64
maxpmtlast3m_4525190A float64
previouscontdistrict_112M category
price_1097A float64
sumoutstandtotal_3546847A float64
sumoutstandtotalest_4493215A float64
totaldebt_9A float64
totalsettled_863A float64
totinstallast1m_4525188A float64
description_5085714M category
education_1103M category
education_88M category
maritalst_385M category
maritalst_893M category
pmtaverage_3A float64
pmtaverage_4527227A float64
pmtaverage_4955615A float64
pmtssum_45A float64
dtype: object
検証データも同様でした。
[in]
print(X_valid.dtypes)
[out]
amtinstpaidbefduel24m_4187115A float64
annuity_780A float64
annuitynextmonth_57A float64
avginstallast24m_3658937A float64
avglnamtstart24m_4525187A float64
avgoutstandbalancel6m_4187114A float64
avgpmtlast12m_4525200A float64
credamount_770A float64
currdebt_22A float64
currdebtcredtyperange_828A float64
disbursedcredamount_1113A float64
downpmt_116A float64
inittransactionamount_650A float64
lastapprcommoditycat_1041M category
lastapprcommoditytypec_5251766M category
lastapprcredamount_781A float64
lastcancelreason_561M category
lastotherinc_902A float64
lastotherlnsexpense_631A float64
lastrejectcommoditycat_161M category
lastrejectcommodtypec_5251769M category
lastrejectcredamount_222A float64
lastrejectreason_759M category
lastrejectreasonclient_4145040M category
maininc_215A float64
maxannuity_159A float64
maxannuity_4075009A float64
maxdebt4_972A float64
maxinstallast24m_3658928A float64
maxlnamtstart6m_4525199A float64
maxoutstandbalancel12m_4187113A float64
maxpmtlast3m_4525190A float64
previouscontdistrict_112M category
price_1097A float64
sumoutstandtotal_3546847A float64
sumoutstandtotalest_4493215A float64
totaldebt_9A float64
totalsettled_863A float64
totinstallast1m_4525188A float64
description_5085714M category
education_1103M category
education_88M category
maritalst_385M category
maritalst_893M category
pmtaverage_3A float64
pmtaverage_4527227A float64
pmtaverage_4955615A float64
pmtssum_45A float64
dtype: object
一応、2つのデータフレームの列名に差分がないことも確かめました。
[in]
set(X_train.columns) ^ set(X_valid.columns)
[out]
set()
ダミー変数化をすると...
ここで、pandas.get_dummiesを使ってダミー変数化すると列数が揃わなくなります。
[in]
import pandas as pd
X_train = pd.get_dummies(X_train)
X_valid = pd.get_dummies(X_valid)
print(f"Train: {X_train.shape}")
print(f"Valid: {X_valid.shape}")
[out]
Train: (915995, 834)
Valid: (305332, 736)
教師データと検証データには、それぞれにない列名が存在します。
[in]
print("学習データにはあって検証データにはない列数:" )
print(len(set(X_train.columns) - set(X_valid.columns)))
print("検証データにはあって学習データにはない列数:" )
print(len(set(X_valid.columns) - set(X_train.columns)))
[out]
学習データにはあって検証データにはない列数:
133
検証データにはあって学習データにはない列数:
35
列数の差は、ダミー変数化前の各列のユニークな値の差となります。
解決方法
各データフレームに出現するユニークな値をカテゴリとして設定する必要があります!
そこで、ダミー変数化する前にpandas.CategoricalDtypeを使ってそれぞれのデータフレームのカテゴリ変数のユニークな値をcategoriesに付与します。
以下のステップで、列が揃ったデータフレームに加工していきます。
- データフレームからカテゴリ変数の列名を抽出
- 各変数の教師データと検証データのユニークな値を取得
- ユニークな値を
CategoricalDtypeの引数として渡す -
get_dummiesでダミー変数化
まずは対象となるカテゴリ変数を得ます。
# 1.カテゴリ変数の列名を抽出
[in]
# データ型がstrの列名を取得することでカテゴリ変数を得る
cat_cols = X_train.loc[:, X_train.iloc[0].map(type) == str].columns.unique()
print('Categorical columns:')
print(cat_cols)
[out]
Categorical columns:
Index(['lastapprcommoditycat_1041M', 'lastapprcommoditytypec_5251766M',
'lastcancelreason_561M', 'lastrejectcommoditycat_161M',
'lastrejectcommodtypec_5251769M', 'lastrejectreason_759M',
'lastrejectreasonclient_4145040M', 'previouscontdistrict_112M',
'description_5085714M', 'education_1103M', 'education_88M',
'maritalst_385M', 'maritalst_893M'],
dtype='object')
続いて、それぞれの変数に対してユニークな値をカテゴリとして付与します。わかりやすくfor文で実装します。
[in]
import pandas as pd
for col in cat_cols:
# 2.各変数の教師データと検証データのユニークな値を取得
cat_list = {*X_train[col], *X_valid[col]}
# 3.ユニークな値を`CategoricalDtype`の引数として渡す
X_train[col] = X_train[col].astype(pd.CategoricalDtype(cat_list))
X_valid[col] = X_valid[col].astype(pd.CategoricalDtype(cat_list))
ちなみに*を使うことでリストなどをアンパックできます。中身はこんなデータになっています。
[in]
print({*X_train[col], *X_valid[col]})
[out]
{'P105_126_172', 'P175_82_175', 'P49_162_170', 'P193_109_73', 'P76_145_175', 'P52_56_90', 'P143_21_170', 'P201_79_148', 'P21_123_87', 'P181_140_94', 'P21_79_33', 'P159_130_59', 'P137_157_60', 'P216_109_183', 'P65_94_74', 'P75_42_174', 'P12_6_178', 'P187_118_47', 'P148_110_5', 'a55475b1', 'P38_69_128', 'P156_122_160', 'P151_9_55', 'P98_19_172', 'P137_6_96', 'P121_6_80', 'P177_46_174', 'P117_143_46', 'P109_133_183', 'P48_73_87', 'P176_123_187', 'P160_128_10', 'P141_125_135', 'P184_3_97', 'P58_25_91', 'P33_29_177', 'P53_45_92', 'P128_43_169', 'P110_120_162', 'P201_108_190', 'P156_50_173', 'P100_96_175', 'P3_103_80'}
最後にダミー変数化を行います。
# 4.`get_dummies`でダミー変数化
[in]
X_train = pd.get_dummies(X_train)
X_valid = pd.get_dummies(X_valid)
print(f"Train: {X_train.shape}")
print(f"Valid: {X_valid.shape}")
[out]
Train: (915995, 856)
Valid: (305332, 856)
列数が揃いましたね。
2つのデータフレームの列名にも差分がありません。
[in]
set(X_train.columns) ^ set(X_valid.columns)
[out]
set()
まとめ
ダミー変数化は次元数が大きくなるので計算コストも意識しなくてはいけない場合があります。
Kaggleで扱うようなデータの規模であったり、外部の計算リソースを使う、という場面では小回りの利く前処理が必要になるので、この記事では丁寧に処理手順を分けています。
get_dummiesの場合はdrop_firstでさらに次元を削ることができます。