この記事の目的
タイタニック号のデータを例に、データの特徴を確認するために初めに行うことをメモしておきます。
普通は pandas-profiling の方がもっと細かい情報がわかるのでいいかもしれません。
ライブラリ読み込み
import numpy as np
import pandas as pd
pd.set_option('display.max_columns', 100)
import warnings
warnings.filterwarnings('ignore')
import collections
データの準備
!wget https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv
データ読み込み&少し加工
filename = "/content/titanic.csv"
df = pd.read_csv(filename, encoding='utf-8')
# 適当にNaN作る
df["Name"] = [di if np.random.rand()>0.1 else float("nan") for di in df["Name"]]
df["Sex"] = [di if np.random.rand()>0.01 else float("nan") for di in df["Sex"]]
df["Age"] = [di if np.random.rand()>0.05 else float("nan") for di in df["Age"]]
# family name
df["f_Name"] = [str(di).split(" ")[-1] if len(str(di).split(" "))>1 else float("nan") for di in df["Name"]]
このようなデータフレームができます。
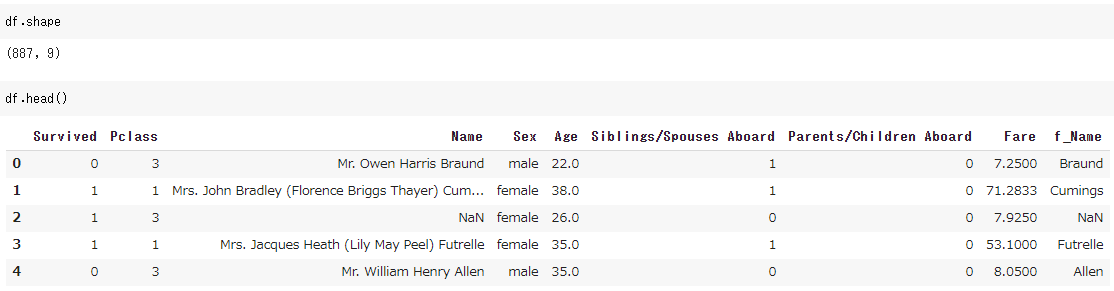
後で collections.Counter を使うのですが、NaNの値が float("nan") だとうまく集計されないので np.nan に置換しておきます。詳しくはこちらなど参照
df = df.replace(float("nan"), np.nan)
データの型を1つ1つ定義しておきます。
target = "Survived"
cate_list = ["Pclass", "Name", "f_Name", "Sex", "Siblings/Spouses Aboard", "Parents/Children Aboard"]
num_list = ["Age", "Fare"]
all_list = cate_list+num_list
以下がメインの処理です。
n = df.shape[0]
max_n_unique = 10
n_unique_list=[]
min_data_list=[]
max_data_list=[]
major_data_rate_list=[]
# categoryだけ
for colname in all_list:
if colname in cate_list: #cate
n_unique = len(df[colname].unique())
min_data = np.nan
max_data = np.nan
if n_unique>max_n_unique: #カテゴリ数多かったら
c = collections.Counter(df[colname])
c_dict = dict(c.most_common(max_n_unique-1))
#k_list = [k for k,v in c_dict.items()]
v_list = [v/n for k,v in c_dict.items()]
major_data_rate = np.sum(v_list)
else:
major_data_rate = np.nan
else: #num
n_unique = np.nan
major_data_rate = np.nan
min_data = df[colname].min()
max_data = df[colname].max()
n_unique_list.append(n_unique)
major_data_rate_list.append(major_data_rate)
min_data_list.append(min_data)
max_data_list.append(max_data)
have_nan = df.loc[:,all_list].isnull().any(axis=0)
nan_rate = df.loc[:,all_list].isnull().sum(axis=0)/n
summary_df = pd.DataFrame({"colname":all_list,
"have_nan":have_nan.values,
"nan_rate":nan_rate.values,
"n_unique":n_unique_list,
"major_data_rate":major_data_rate_list,
"min_data":min_data_list,
"max_data":max_data_list
})
こんな変数の特徴をまとめたデータフレームができます。
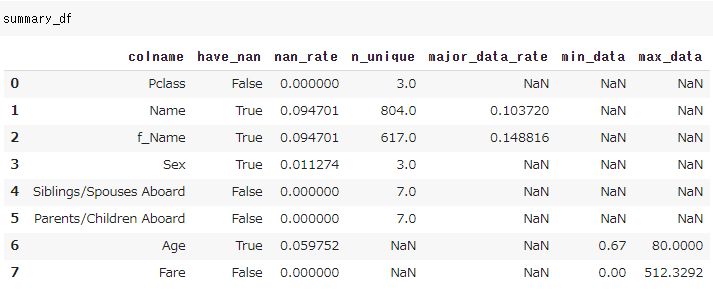
major_data_rate は max_n_unique で指定した数、例えば10なら頻出Top10のデータをmajorとみなしそのデータの割合を計算しています。(後の処理でTop10以外を others などでまとめることを想定しています。)
参考
stack overflow:Why does collections.Counter treat numpy.nan as equal?
CS109:A Titanic Probability
GitHub:pandas-profiling