はじめに
今回の開発メモは深層学習でTTS(Text-To-Speech)用のモデル開発に当たってデータ収集のプロセスをまとめて行きたいと思います。TTSの開発にあったてなかなか「質の高いデータを入手するのが大変」って分けで、今回はYouTuberの音声データを使ったデータ収集方法をご紹介して行きます。
【なぜユーチューバー?】
今回はYouTuberと言うより、VTuber(ヴァーチャルユーチューバー)のデータを使って行くことにしました。これはいくつかのメリットがあるからです:
1. 簡単に(パイソンなどのライブラリを使って)音声をダウンロードできるから
2. ほとんどの場合、質の高い字幕データがついている(それも字幕表示時間もついてくる)
3. ユーチューバーはマイクのセットアップが良いため、音声の質がほぼ良い
4. 背景のノイズデータがほぼ少ないこと
・・・など、様々な理由でTTS用のデータとして適用できます。
今回使わせて頂く人物は、スーパーインテリジェントAIとして知られている「Kizuna AIちゃん」の声を今回モデル化してTTSモデルを作って行く設定でデータ収集をしていきます。

動画URLの収集
まず最初に、音声の元となる動画を探していく必要があります。
ここで自動化してチャンネルごとの動画を全部まとめてスクレーピングして行く考えでしたが、一歩目から色々な問題点に遭遇してしまいました。
その1:APIキーを使わずにスクレーピングができない
Googleからチャンネルごとの動画のURLを入手するのにはAPIキーが必要です。しかしそれを設定するのが面倒で、なんとかスクレーピング方法でデータを集めようかと考えました。しかしYouTubeのページがダイナミック式のページでスクロールするごとにあとの動画を表示されるため、そこまでしてデータを自動的にしてやる必要はないと判断しました。
なのでここは手動で一つーつ動画を拝見していって、テキストファイルにとにかく集めていく方法にしました。
その2:ノイズの多いコンテンツや音楽系などがある
手動で集める2つ目の理由とは、Kizuna AIちゃんの動画には「ゲーム実況」、「ゲストインタビュー」や「音楽・踊り系」などの動画などのアップロードがあるため、それを分けて行く作業が大変でした。しかしこの作業を行うことによって、よりノイズの少ない、質の高いデータセットを作成することができます。

その3:字幕データが存在しない可能性がある
今回は音声データと一緒に、字幕データの収集を行って行きます。そのため、元の動画に字幕データが存在するかどうかの検討作業を行う必要があるのです。特に、今回はデータの質に気をつけているため、手動でアノテートされた字幕データを中心として集めることに決めました。これは、手動で入力された字幕データが存在しない場合にはGoogleのSpeech-To-Textを使って字幕を振っているのですが、そもそも正確性が酷いため今回のデータセットには使わないことにします。

と上記の理由により、手動で動画を見ていく地味な作業に取り組みました。他のユーチューバーさんの場合には異なることがあるので、自動化する方法も大丈夫なチャンネルなどがあるかもしれません。もしここで効率の良い方法があれば、是非コメント欄で教えてください!
ダウンロードスクリプトの開発
次にデータセットの動画音声と字幕データのダウンロードスクリプトを作り上げて行きます。
ここではいくつかのライブラリーを使いました:
- youtube-dl: YouTubeから動画や音声などのダウンロードできるライブラリー
- youtube_transcript_api: 字幕とそのタイミングを入手できるようになっているライブラリー
from __future__ import print_function, unicode_literals
import os
import time
import json
import youtube_dl
from youtube_transcript_api import YouTubeTranscriptApi
# Parameters
DATA_DIR = 'data/'
AUDIO_DIR = DATA_DIR + 'audio/'
TRANS_DIR = DATA_DIR + 'trans/'
SLEEP = 3
# YouTube Audio Download Config
ydl_opts = {
'outtmpl': AUDIO_DIR + '%(id)s.%(ext)s',
'format': 'bestaudio/best',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'wav',
'preferredquality': '192'
}],
'postprocessor_args': [
'-ar', '16000'
],
'prefer_ffmpeg': True,
'keepvideo': False
}
def get_videoID(url):
return url[32:]
if __name__ == '__main__':
# Load Video URL List
url_list = open('data/video_url.txt', 'r').read().split('\n')[:-1]
# Initialize YouTube Downloader
ydl = youtube_dl.YoutubeDL(ydl_opts)
# Process Downloads
for url in url_list:
# Obtain URL ID
id = get_videoID(url)
print('> PROCESSING: ' + id)
# Download Audio File
ydl.download([url])
# Download & Persist Subtitle
sub = YouTubeTranscriptApi.get_transcript(id, languages=['ja'])
out = open(TRANS_DIR + '/' + id + '.json', 'w', encoding='utf8')
out.write(json.dumps(sub))
out.close()
# Control Break Timing
time.sleep(SLEEP)
print('')
print('> DONE')
上記のコードを実行するまえにいくつかのフォルダーの作成をする必要があります。(以下のように・・・)
|- build_dataset.py
|- data/
|- audio/
|- trans/
|- video_url.txt
そしてコードを実行すると、このようにダウンロードして行き・・・
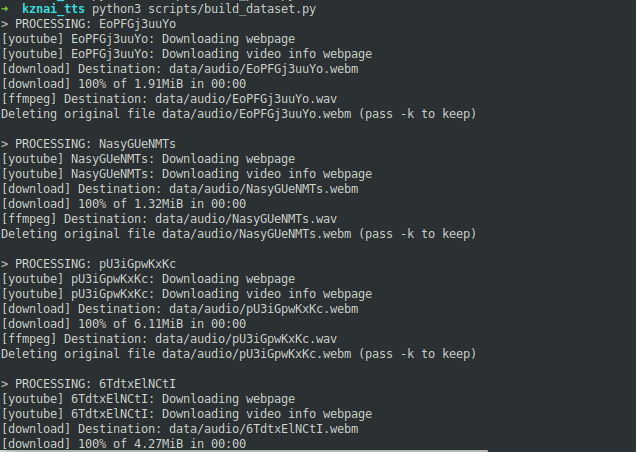
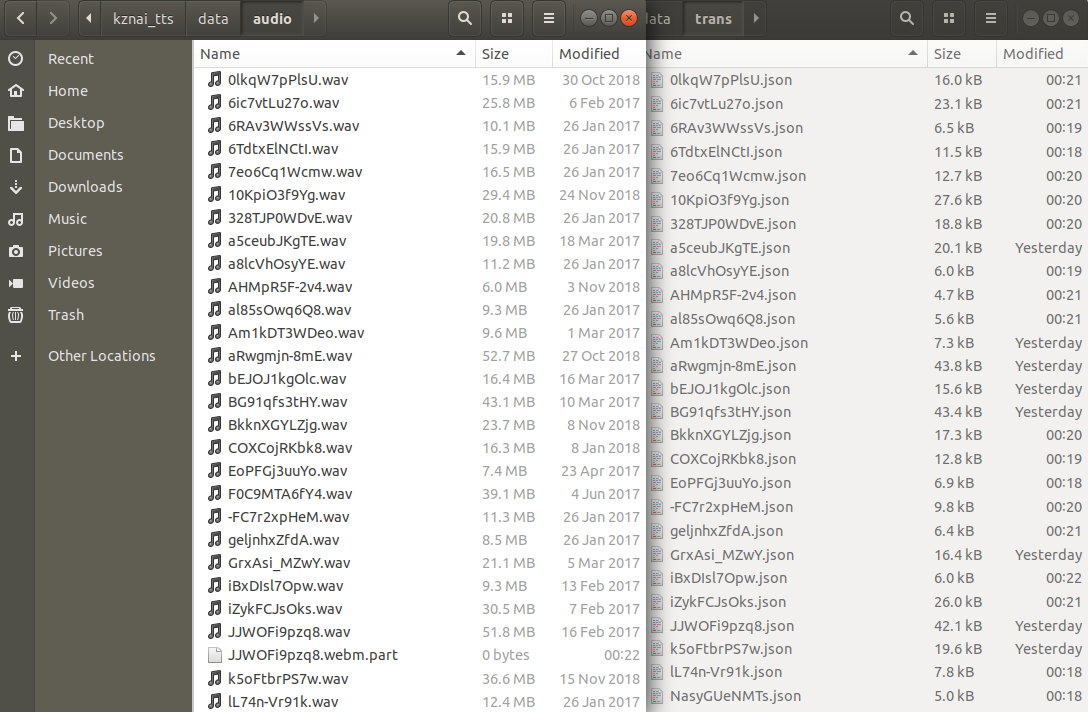
こんな感じで音声と字幕データが集まってきます!
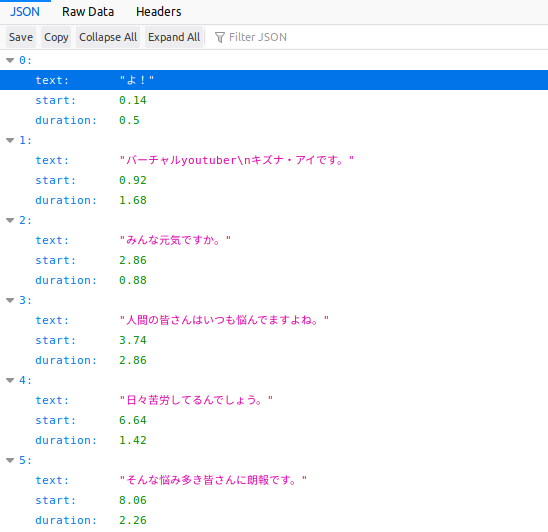
字幕データはすべてJSON式にになっており、覗いてみるとフレーズ、その始まり時間と期間が全て記載されています。
まとめ
今回は簡単にデータ収集方法とそのコツをお伝えました。次回はこちらのデータの前処理方法とデータ検証のプラットフォームでデータのアノテーションの編集やノイズの多いデータの除去作業が簡単にできるウェブアプリを作っていきます。