はじめに
本記事は、データベースのフィールド内にて、区切り文字で区切られているデータの扱いに苦戦した為、その解法についてまとめました。今回はカンマ区切りデータの下記2点の場合の処理方法を記載しました。
・フィールド内のカンマ区切りデータの部分削除
・フィールド内のカンマ区切りデータ要素別カウント
先に結論ですが、1つ目のフィールド内のカンマ区切りデータの部分削除は問題なく用いることができました。カンマ区切りデータの削除や置換を行いたい場合に有効です。
2つ目のフィールド内のカンマ区切りデータ要素別カウントについては、GROUP BYを用いていることにより、データ数が膨大な時にはかなりの処理時間を要してしまいました(チューニングをすることである程度の時間削減は可能)。カンマ区切りのデータが含まれている場合は、DB設計の見直しをしてください。どうしてもそのまま処理しないといけない場合は、SQL側で処理することをやめ、フロント側での処理を推奨します。
前提条件
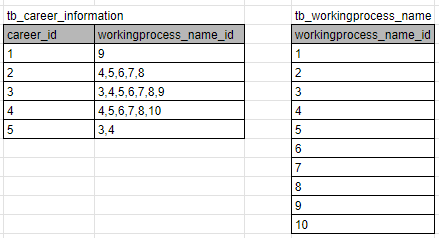
今回用いたテーブルは作業工程マスタ(tb_workingprocess_name)、経歴テーブル(tb_career_information)
作業工程マスタはマスタで、経歴情報登録時の一項目です。経歴登録するとトランザクションテーブルの経歴情報に保存されます。
作業工程は複数選択可能で、複数選択した場合は、経歴情報テーブルにはIDがカンマ区切りで格納されます。
フィールド内のカンマ区切りのデータの一部を削除したい場合
例:4の削除
本例では経歴情報テーブルのworkingprocess_name_idカラムから「4」のみを削除しています。

WHERE
正規表現 REGEXP を使って「4」と一致するレコードを絞ります。CONCATで「削除対象のID」と\bを連結し、正規表現文を構成します。
\bで囲うことにより、囲われた文字列と完全一致で検索することが可能です。
※\がエスケープ文字であるため、\\としています。
SET
REGEXP_REPLACEを使って正規表現を用いた置換を行います。
・対象の値を空白に置換
REGEXP_REPLACE(workingprocess_name_id,CONCAT('\\b',#{workingprocessNameId},'\\b'),'')
・対象の値が間にあった場合、',,'を','に置換
REGEXP_REPLACE(workingprocess_name_id,',,',',')
・対象の値が先頭に合った場合、正規表現(^)を用いて先頭の','を空白に置換
REGEXP_REPLACE(workingprocess_name_id,'^,','')
・対象の値が後尾にあった場合、正規表現($)を用いて後尾の','を空白に置換
REGEXP_REPLACE(workingprocess_name_id,',$','')
<update>
UPDATE
tb_career
SET
workingprosess_name_id = REGEXP_REPLACE(workingprocess_name_id,CONCAT('\\b',#{workingprocessNameId},'\\b'),'')
,workingprocess_name_id = REGEXP_REPLACE(workingprocess_name_id,',,',',')
,workingprocess_name_id = REGEXP_REPLACE(workingprocess_name_id,'^,','')
,workingprocess_name_id = REGEXP_REPLACE(workingprocess_name_id,',$','')
WHERE
workingprocess_name_id REGEXP CONCAT('\\b',#{workingprocessNameId},'\\b')
</update>
カンマ区切りの要素毎の数をカウントする
例:workingprocess_name_idのid別カウント
本例では、経歴情報テーブル(tb_career_information)にて作業工程名(workingprocess_name_id)がそれぞれどれだけ用いられているかをカウントしています。

・経歴情報テーブル(tb_career_information)と作業工程マスタ(tb_workingprocess_name)をLEFT JOINにて結合
・結合条件に正規表現REGEXP CONCAT('\\b'tb_workingprocessname.workingprocess_name_id,'\\b')を用いて、カンマ区切りの数値を各カラムに分割
・Group Byを用いて、workingprocess_name_idをグループ化、ID毎にカウント

<select>
SELECT
tb_workingprocess_name.workingprocess_name_id as workingprocess_name_id
,COUNT(tb_workingprocess_name.workingprocess_name_id) as num
FROM
tb_career_information
LEFT
tb_workingprocess_name
ON
tb_career_information.workingprocess_name_id REGEXP CONCAT('\\b'tb_workingprocessname.workingprocess_name_id,'\\b')
WHERE
tb_career_information.is_deleted = 0
GROUP BY
tb_workingprocess_name.workingprocess_name_id
</select>
まとめ
今回はフィールド内にてカンマで区切られているデータの正規表現を使った処理方法についてまとめました。
1つ目の、単一カラムのカンマ区切りの要素の削除や置換については、処理速度も遅くないため有効な手段の一つであると考えました。
2つ目の、要素数のカウント手法については、GROUP BYを用いている為、データ数が多くなるとかなり処理速度が遅くなる為、小規模なデータで実行するときには有効ですが、大規模なデータの実行は非推奨です(チューニングである程度は処理速度を上げることは可能)。DB設計の見直しを検討してください。
参考
https://www.megasoft.co.jp/mifes/seiki/index_s2.html
https://bashalog.c-brains.jp/15/09/29-100000.php