はじめに
こんにちは、AI修行中のoreyutaroverです。
最近Kerasを使い始め、CNN単体やRNN単体のモデルはお手軽に構築させて頂いています。
次にどんなAIを勉強しようかなーとネットを眺めていたところ、CNNとRNNを組み合わせた面白い題材がありました。
それが、”画像キャプション生成”です!
画像キャプション生成とは、画像を入力として与えると、出力として画像の内容を説明する短い文章を生成することです。
CNNとRNNの両方を使用した複雑なモデルを構築することは非常に良い勉強になりますし、これを手作りするとどんな結果が得られるかも気になるところなので、取り敢えずチャレンジすることに決めました。
画像キャプション生成のサンプルコードを調べてみると、ほぼ全てが英語キャプションでした。
これをそのまま真似するだけではつまらないので、今回は画像の”日本語キャプション”を自動生成することを目標とします。
理論からプログラムまでできる限り丁寧にまとめましたので、是非ご覧下さい!
概要
まずはアルゴリズムを図示します。

簡単にアルゴリズムについて説明すると、
・学習済みCNNで画像の特徴量を抽出する。
・LSTMで文章の特徴量を抽出する。
・CNNとLSTMの特徴量を結合する。
・Softmax関数で次に来る単語を予測する。
というステップに分けられます。
上記ステップを繰り返すことで、画像の描写文を生成することができます。
例えば、
画像+start→女の子
画像+start女の子→と
画像+start女の子と→彼女
画像+start女の子と彼女→の
画像+start女の子と彼女の→馬
画像+start女の子と彼女の馬→は
画像+start女の子と彼女の馬は→火のそば
画像+start女の子と彼女の馬は火のそば→に
画像+start女の子と彼女の馬は火のそばに→立つ
画像+start女の子と彼女の馬は火のそばに立つ→end
といった具合で描写文を生成します。
ここでは、startが文章の最初の入力、endが推論された時に文章生成を終了する、というルールとしています。
今回使用したデータセットは、Flickr 8k Dataです。
Flickr 8k Dataは、画像とその英語描写文がセットになったデータセットです。
私は日本語描写文を使用したかったのですが、日本語キャプションのオープンデータがなかなか見つからなかったため、Google翻訳で英語を日本語に変換し、データセットを新たに作成することにしました。
※Flickr 8k Dataは下記URLからダウンロードできます。
https://forms.illinois.edu/sec/1713398
それでは、下記の目次に従って、画像キャプション生成AIのプログラムについて解説します。
| 目次 |
|---|
| 1.環境 |
| 2.メソッドをインポートする&ファイル名を宣言する |
| 3.学習済みCNNモデルを使って画像の特徴量を抽出する |
| 4.英語描写文を日本語翻訳&前処理する |
| 5.画像キャプション生成モデルを訓練する |
| 6.新たな画像を入力として描写文を推論する |
| 7.日本語による画像キャプションを自動生成する |
| 8.結果 |
1.環境
- Amazon EC2 P3 Instance
- Instance type : p3.2xlarge
- GPU : Tesla V100 ✕ 1
- Kernel : conda_tensorflow_p36
~/Home
├Flickr8k_Dataset
├667626_18933d713e.jpg
├12830823_87d2654e31.jpg
└・・・
├Flickr8k_text
└Flickr8k.token.txt
└ImageCaptioning.py
2.メソッドをインポートする&ファイル名を宣言する
# General
from os import listdir
from pickle import dump, load
from numpy import array, argmax
from tqdm import tqdm
# Keras
from keras.applications.vgg16 import VGG16, preprocess_input
from keras.models import Model, load_model
from keras.preprocessing.image import load_img, img_to_array
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.layers import Input, Dense, LSTM, Embedding, Dropout
from keras.layers.merge import add
# 日本語処理
from googletrans import Translator
import MeCab
# Flickrデータセット
DATASET_DIR = "Flickr8k_Dataset"
TOKEN_FILE = "Flickr8k_text/Flickr8k.token.txt"
# ファイル名
IMAGE_FEATURES = "image_features_dict.pkl"
IMAGE_TEXTS = "image_texts_dict.txt"
TOKENIZER = "tokenizer.pkl"
TRAINED_MODEL = "model_19.h5"
TEST_IMAGE = "test_doginwater.jpg"
3.学習済みCNNモデルを使って画像の特徴量を抽出する
学習済みのCNNモデルにはVGG16を使用します。
VGG16は本来1000クラスの多クラス分類モデルですが、ここでは最終層を取り除くことで、特徴量抽出器として使用します。
下記が画像から特徴量を抽出する概略図です。
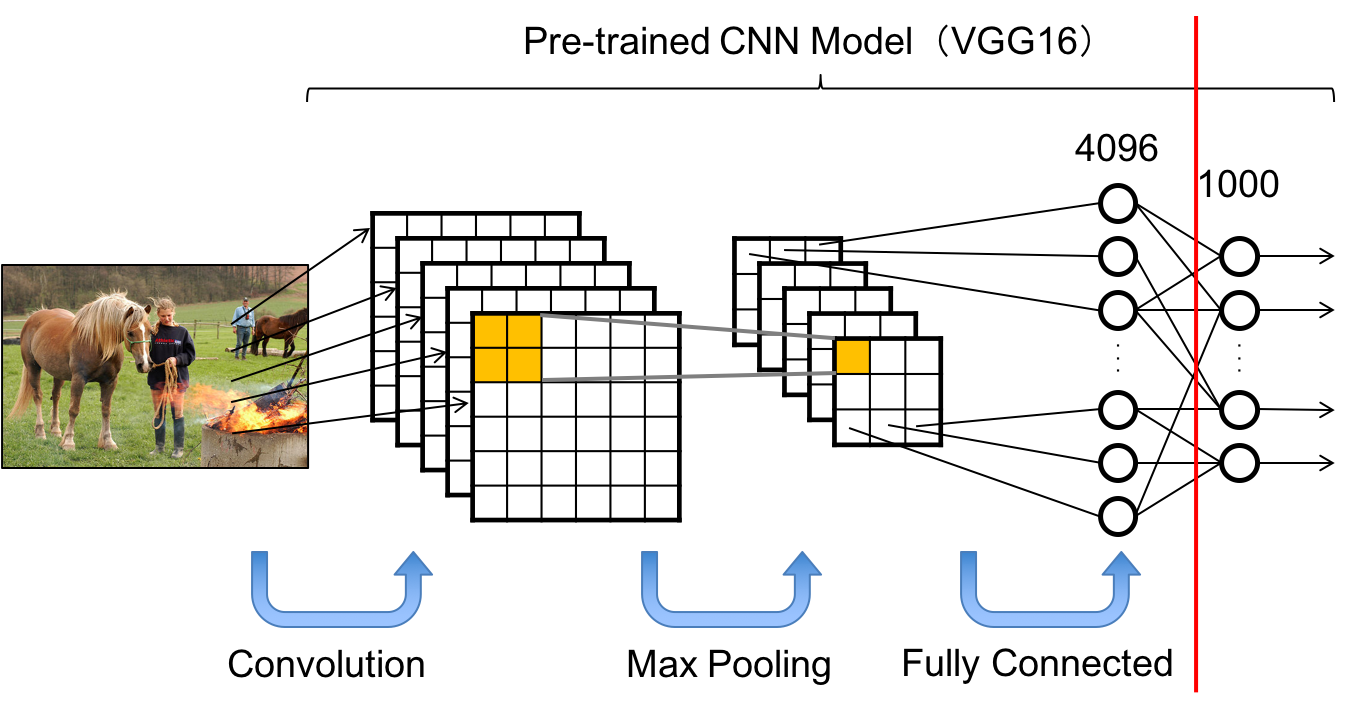
画像の特徴量を学習済みCNNモデルで抽出するクラスを下記に記載します。
class ImagePreprocessor():
"""
画像を訓練用に前処理する。
"""
dataset_dit = ""
def __init__(self, dataset_dir):
self.dataset_dir = dataset_dir
self.feature_extractor = self.GetFeatureExtractor()
self.image_features_dict = {}
return
def GetFeatureExtractor(self):
"""
・モデルをロードする。
・ソフトマックスの最終層を取り除く。
・モデルを再定義する。
"""
model = VGG16()
model.layers.pop()
model = Model(inputs=model.inputs, outputs=model.layers[-1].output)
return model
def GetImageFeature(self, filename, model):
"""
・特徴量抽出器をロードする。
・画像ファイルをロードする。
・PixcelをNumpy形式に変換する。
・学習用にモデルを変形する。
・VGGモデル用の前処理を行う。
・画像の特徴量を取得する。
"""
image = load_img(filename, target_size=(224, 224))
image = img_to_array(image)
image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
image = preprocess_input(image)
image_feature = model.predict(image, verbose=0)
return image_feature
def MakeFeaturesDict(self):
"""
・ファイルから画像特徴量を取得する。
・ファイルから画像IDを取得する。
・画像IDと画像特徴量を辞書に保存する。
"""
for name in tqdm(listdir(self.dataset_dir)):
filename = self.dataset_dir + '/' + name
image_feature = self.GetImageFeature(filename, self.feature_extractor)
image_id = name.split('.')[0]
self.image_features_dict[image_id] = image_feature#1×4096
return self.image_features_dict
def SaveDict(self, filename):
dump(self.image_features_dict, open(filename, 'wb'))
return
4.英語描写文を日本語翻訳&前処理する
冒頭にも話した通り、Flickr 8k Datasetの画像描写文は英語で記載されているため、まず日本語に変換する必要があります。
英語を日本語に変換するため、ここではPython用のGoogle Translate APIを使用します。
日本語の画像描写文ができた後、MeCabを用いて形態素変換を行います。
MeCabの辞書には、mecab-ipadic-NEologdを使用します。
形態素変換を行い、文章を単語毎に分割した後、スペース区切りで単語を並べます。
文章の最初にstart、最後にendを追加し、文章の前処理を完了とします。
以上の手順を、下記に記載します。

画像の描写文を前処理するクラスを下記に記載します。
class TextPreprocessor():
"""
テキストを訓練用に前処理する。
"""
def __init__(self, token_file):
self.tokens = self.LoadTexts(token_file)
self.image_texts_dict = {}
self.m = MeCab.Tagger ("mecabrc")
self.translator = Translator()
return
def LoadTexts(self, filename):
"""
・テキストを読み込む。
"""
with open(filename, "r") as file:
text = file.read()
return text
def __translate(self, text):
"""
・インスタンス化する(Google APIのリクエスト数に上限があり、事前にインスタンス化するとエラーが出るため)。
・テキストを日本語に変換する。
"""
text_ja = self.translator.translate(text, dest='ja').text
return text_ja
def __mecab(self, text_ja):
"""
・MeCabで形態素変換を行い、改行毎に区切る。
"""
text_mecab = self.m.parse(text_ja).split('\n')
return text_mecab
def Preprocess(self, text):
"""
・形態素変換後の単語のみを抽出し、リストに追加する。
・リスト内の単語を結合する。
・不要な単語(、。EOS)を削除する。
・文頭と文末に印となる単語を追加する。
"""
word_list = []
text_ja = self.__translate(text)
text_mecab = self.__mecab(text_ja)
for word in text_mecab:
word_list.append(word.split('\t')[0])
text_preprocess = ' '.join(word_list).replace(" 、", "").replace(" 。", "").replace(" EOS ", "")
text_final = 'startseq ' + text_preprocess + ' endseq'
return text_final
def GetIDAndText(self, token):
"""
・空白で分割する。
・最初のトークンをID、残りをテキストとして取得する。
・画像IDからファイル名だけ取り出す。
・テキスト内の単語が分割されているので、1つのテキストに結合する。
"""
token = token.split()
image_id, image_text = token[0], token[1:]
image_id = image_id.split('.')[0]
image_text = ' '.join(image_text)
return image_id, image_text
def MakeTextsDict(self):
"""
・トークンをロードする。
・画像IDと 画像描写文を取得する。
・画像描写文を日本語に変換する。
・辞書内に画像IDが無かった場合、画像IDを追加する。
・辞書の画像IDに対応するテキストを追加する。
"""
for token in tqdm(self.tokens.split('\n')):
image_id, image_text = self.GetIDAndText(token)
image_text = self.Preprocess(image_text)
if image_id not in self.image_texts_dict:
self.image_texts_dict[image_id] = []
self.image_texts_dict[image_id].append(image_text)
return self.image_texts_dict
def SaveDict(self, filename):
dump(self.image_texts_dict, open(filename, 'wb'))
return
5.画像キャプション生成モデルを訓練する
まずは、画像の描写文を基にトークナイザーを生成します。

続いて、本題の画像キャプション生成モデルを構築します。
画像のエンコーダーにCNN、テキストのエンコーダーにLSTMを用います。
デコーダーでは、画像とテキストの特徴量を結合し、次に登場する単語を予測します。
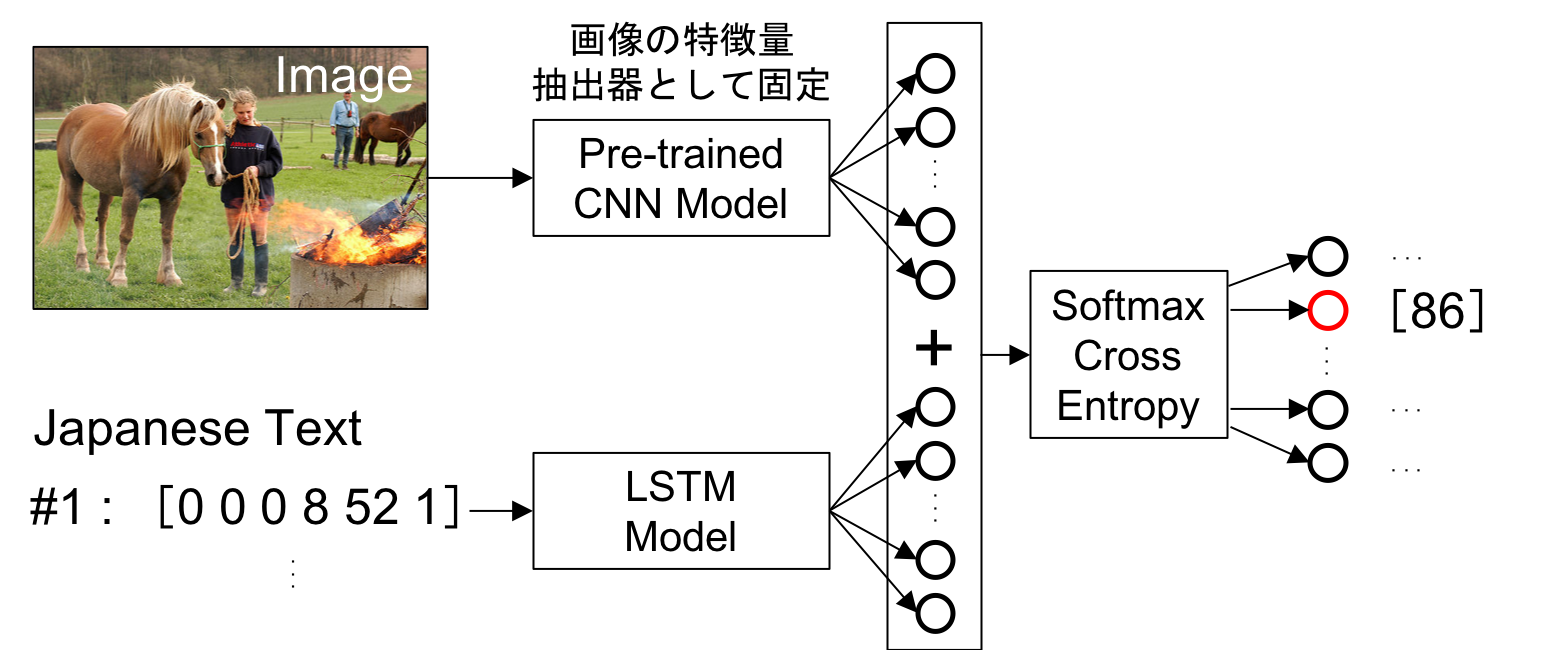
このモデルを訓練する上で最も重要な点は、実はモデルの構築部分ではなく、LSTMに入力するテキストと出力単語の組み合わせを作成する部分です。
[入力文章、出力単語] の組み合わせを下図のように作成し、画像キャプション生成モデルをトレーニングします。

画像キャプション生成モデルを訓練するクラスを下記に記載します。
class Trainer(TextPreprocessor):
"""
画像キャプション生成モデルを訓練する。
"""
def __init__(self, features_dict, texts_dict, epochs):
self.train_texts_dict = texts_dict
self.train_features_dict = features_dict
self.tokenizer = Tokenizer()
self.epochs = epochs
return
def __dictToList(self, texts_dict):
"""
・辞書型で保存された画像描写文をリストに変換する。
"""
texts_list = []
for key in texts_dict.keys():
[texts_list.append(d) for d in texts_dict[key]]
return texts_list
def MakeTokenizer(self):
"""
・テキストが保存されている辞書をリストに変換する。
・Tokenizerをインスタンス化する。
・テキスト内の単語にトークン番号を割り当てる。
・トークナイザーをファイルに保存する。
"""
train_texts_list = self.__dictToList(self.train_texts_dict)
self.tokenizer.fit_on_texts(train_texts_list)
dump(self.tokenizer, open('tokenizer.pkl', 'wb'))
return None
def GetVocabSize(self):
"""
・トークナイザーに登録されている単語の総数を取得する。
"""
self.vocab_size = len(self.tokenizer.word_index) + 1
print("Vocabulary Size of Texts: ", self.vocab_size)
return
def GetMaxLength(self):
"""
・訓練用の画像描写文の最大単語数を取得する。
"""
lists = self.__dictToList(self.train_texts_dict)
self.max_length = max(len(d.split()) for d in lists)
print("Max Length of Texts: ", self.max_length)
return self.max_length
def MakeCaptioningModel(self):
"""
・画像エンコーダーを作成する。
・テキストエンコーダーを作成する。
・デコーダーを作成する。
・入力を[画像, テキスト]、出力を[単語]とするモデルを作成する。
・損失関数に交差エントロピー、最適化関数にアダムを指定する。
・モデルの構成を可視化する。
"""
#画像エンコーダー
inputs1 = Input(shape=(4096,))
ie1 = Dropout(0.5)(inputs1)
ie2 = Dense(256, activation='relu')(ie1)
#テキストエンコーダー
inputs2 = Input(shape=(self.max_length,))
se1 = Embedding(self.vocab_size, 256, mask_zero=True)(inputs2)
se2 = Dropout(0.5)(se1)
se3 = LSTM(256)(se2)
#デコーダー
decoder1 = add([ie2, se3])
decoder2 = Dense(256, activation='relu')(decoder1)
outputs = Dense(self.vocab_size, activation='softmax')(decoder2)
#キャプショニングモデル
model = Model(inputs=[inputs1, inputs2], outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam')
#model.summary()
self.model = model
return
def MakeInputOutput(self, image_texts, image_feature):
"""
・1つの画像に対する描写文を1文ずつ取り出す。
・各単語にトークン番号を割り当てる。
・1つのシークエンスを複数のX, yペアに変換する。
・Xをパディングする。
・yをOne-Hot表現する。
・X1に画像特徴量、X2に入力文章、yに出力単語を追加する。
"""
X1, X2, y = [], [], []
for image_text in image_texts:
seq = self.tokenizer.texts_to_sequences([image_text])[0]
for i in range(1, len(seq)):
in_seq, out_seq = seq[:i], seq[i]
in_seq = pad_sequences([in_seq], maxlen=self.max_length)[0]
out_seq = to_categorical([out_seq], num_classes=self.vocab_size)[0]
X1.append(image_feature)
X2.append(in_seq)
y.append(out_seq)
return array(X1), array(X2), array(y)
def DataGenerator(self):
"""
・model.fit_generatorに読み込ませるデータジェネレータを作成する。
"""
while 1:
for key, image_texts in self.train_texts_dict.items():
image_feature = self.train_features_dict[key][0]
in_img, in_seq, out_word = self.MakeInputOutput(image_texts, image_feature)
yield [[in_img, in_seq], out_word]
def TrainModel(self):
"""
・モデルを訓練する。
"""
self.MakeTokenizer()
self.GetVocabSize()
self.GetMaxLength()
self.MakeCaptioningModel()
steps=len(self.train_texts_dict)
for i in range(self.epochs):
generator = self.DataGenerator()
self.model.fit_generator(generator, epochs=self.epochs, steps_per_epoch=steps, verbose=1)
self.model.save('model_' + str(i) + '.h5')
return None
6.新たな画像を入力として描写文を推論する
推論のポイントとして、まずはテキストの最初と最後をstartseqとendseqで判断します。
画像の特徴量とstartseqがモデルに入力されると、その後に続く単語が推論されていきます。
endseqが推論されると、そこで文章が終わりとなる合図であるため、キャプション自動生成はそこで終了します。
class Predictor(ImagePreprocessor):
"""
画像キャプションを生成する。
"""
def __init__(self, model_file, token_file, max_length):
self.model = load_model(model_file)
self.tokenizer = load(open(token_file, "rb"))
self.max_length= max_length
self.feature_extractor = self.GetFeatureExtractor()
return
def IDToWord(self, integer):
"""
・トークン番号を単語に変換する。
"""
for word, index in self.tokenizer.word_index.items():
if index == integer:
return word
return None
def GetFeatureExtractor(self):
"""
ImagePreproessorクラスを継承する。
"""
return super().GetFeatureExtractor()
def GetImageFeature(self, filename, model):
"""
ImagePreproessorクラスを継承する。
"""
return super().GetImageFeature(filename, model)
def Inference(self, test_image):
"""
・訓練済みモデルをロードする。
・トークナイザーをロードする。
・最初の単語をstartseqに設定する。
・単語をトークン番号で表す。
・max_lengthまでパディングする。
・画像特徴量とシークエンスを入力として出力単語を推定する。
・確信度の最も高い単語のトークン番号を取得する。
・トークン番号を単語に変換する。
・シークエンスに単語を追加する。
・endseqが出るまで繰り返す。
"""
image_feature = self.GetImageFeature(test_image, self.feature_extractor)
text = "startseq"
for i in range(self.max_length):
seq = self.tokenizer.texts_to_sequences([text])[0]
seq = pad_sequences([seq], maxlen=self.max_length)
yhat = self.model.predict([image_feature,seq], verbose=0)
yhat = argmax(yhat)
word = self.IDToWord(yhat)
if word is None:
break
text += " " + word
if word == "endseq":
break
return text
7.日本語による画像キャプションを自動生成する
これまでに定義してきたクラスを組み合わせて、日本語による画像キャプションの自動生成を行います。
# 画像の特徴量を抽出する
ip = ImagePreprocessor(dataset_dir=DATASET_DIR)
image_features_dict = ip.MakeFeaturesDict()
ip.SaveDict(filename=IMAGE_FEATURES)
# 画像の描写文を抽出する
tp = TextPreprocessor(token_file=TOKEN_FILE)
image_texts_dict = tp.MakeTextsDict()
tp.SaveDict(filename=IMAGE_TEXTS)
# 一時保存した特徴量と描写文をロードする
image_features_dict = load(open(IMAGE_FEATURES, 'rb'))
image_texts_dict = load(open(IMAGE_TEXTS, 'rb'))
# 画像キャプション生成モデルを訓練する
tr = Trainer(features_dict=image_features_dict, texts_dict=image_texts_dict, epochs=20)
tr.TrainModel()
# テスト画像のキャプション推論
pr = Predictor(model_file=TRAINED_MODEL, token_file=TOKENIZER, max_length=tr.GetMaxLength())
pr.Inference(TEST_IMAGE)
8.結果
気になるのはやはり結果です。
訓練データには含まれていない、完全に新しいテスト画像のキャプション生成を行った結果をご覧下さい。

実際には犬が水の中で走っていますが、そもそも静止画ですので、ある意味立っているとも捉えられるでしょうか。
割と当たっている感じもします。

これは正解のようですね。

これも正解か!と思いきや、よく見ると子供じゃない?ような気もします。人間が見ても判断が難しいのですから、当然AIにとっても難しいです。

これは完全に不正解ですね(笑)
あくまで個人的な見解ですが、白い滝を白い服を来た男、森を岩と認識していると思われます。
岩の顔とは何なのかという疑問は残りますが、AI独自の見方があることも確認できました。
おわりに
長くなりましたが、見ていただいた皆様、ありがとうございました!
今回のチャレンジを通して、CNNとRNNを組み合わせてモデルを構築するという、新しいAIスキルを習得することができたかなと思います。
非常に良い結果も、全然ダメな結果も得られ、まだまだ課題があることも認識できました。
この調子でAI修行に励み、いつかビジネスに活かせることができるような成果も上げてみたいですね。
こちらの記事が参考になった方は、是非「いいね」を頂ければ幸いです。
これからもよろしくお願いします!