この記事はRのdplyrパッケージの「Introduction to dplyr」というVignetteを訳したものです。原文はMITライセンスで公開されているパッケージに含まれ、著作権はRStudio社に帰属します。
あまり英語力に自信がないので、誤訳などあればご指摘ください。編集リクエスツ・アー・ウェルカム!(@uriさんありがとう!)
データを扱うときは必ず以下のようなステップを踏みます。
- 自分がこれから何をしたいのか理解する
- それをコンピュータープログラムという形で記述する
- そのプログラムを実行する
dplyrパッケージを使えば、このステップをすばやく簡単に行えるようになります。具体的には、
- 選択肢を制限することで、よくあるデータ操作をシンプルに考えられるようにします
- シンプルな「verb1」、つまり、よくあるデータ操作に対応する関数を提供します
- 効率的なデータストレージをバックエンドとして用います。これによって、コンピュータの処理が終わるのを待つ時間が少なくなります。
このドキュメントでは、dplyrの基本的なツールを紹介し、それをデータフレーム2に対してどのように使うかを説明します。dplyrは、dbplyrパッケージをインストールすればデータベースも扱うことができます。詳しくはdbplyrパッケージのビネット(vignette("dbplyr"))をご参照ください。
nycflights13: ニューヨークから出発した飛行機のデータ
データ操作に使うdplyrの基本的なverbを試してみるために、nycflights13::flightsというデータを使ってみます。このデータセットには2013年にニューヨークから出発した336776フライトすべてのデータが含まれます。このデータの提供元は米国Bureau of Transportation Statisticsで、詳しい説明は?nycflights13で読むことができます。
library(nycflights13)
dim(flights)
# > [1] 336776 19
flights
# > # A tibble: 336,776 x 19
# > year month day dep_time sched_dep_time dep_delay arr_time
# > <int> <int> <int> <int> <int> <dbl> <int>
# > 1 2013 1 1 517 515 2 830
# > 2 2013 1 1 533 529 4 850
# > 3 2013 1 1 542 540 2 923
# > 4 2013 1 1 544 545 -1 1004
# > # ... with 336,772 more rows, and 12 more variables: sched_arr_time <int>,
# > # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# > # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# > # minute <dbl>, time_hour <dttm>
nycflights13::flightsはtibbleというクラスになっています。tibbleは、data.frameをモダンに作り直したものです。大きなデータセットを扱う際には、tibbleだと初めの数行しか表示されないようになっているので便利です。tibbleについての詳細は http://tibble.tidyverse.org で読むことができますが、ここで一つだけ紹介しておくと、as_tibble()を使えばdata.frameをtibbleに変換できます。
単一テーブルのverb
dplyrには、基本的なデータ操作に対応する関数が用意されています。
-
filter()でレコードを値で絞り込む -
arrange()でレコードを並べ替える -
select()やrename()で列を名前で選択する -
mutate()とtransmute()で、既存の列を使った関数で表される新しい列として追加する -
summarise()で複数の値を単一の値に集約する -
sample_n()とsample_frac()でレコードを無作為に抽出する
もしplyrパッケージを使ったことがあるなら、これらの多くにすぐなじめるはずです。
filter()で行を絞り込む
filter()は、データフレームの行の絞り込みができます。これはすべての単一テーブルverbに共通することですが、第一引数にはtibble(またはdata.frame)を取ります。第二引数以降は、データフレーム内の行を使った表現式になっていて、これがTRUEになる行を取り出します。
たとえば、1月1日のフライトを絞り込むのはこうです:
filter(flights, month == 1, day == 1)
# > # A tibble: 842 x 19
# > year month day dep_time sched_dep_time dep_delay arr_time
# > <int> <int> <int> <int> <int> <dbl> <int>
# > 1 2013 1 1 517 515 2 830
# > 2 2013 1 1 533 529 4 850
# > 3 2013 1 1 542 540 2 923
# > 4 2013 1 1 544 545 -1 1004
# > # ... with 838 more rows, and 12 more variables: sched_arr_time <int>,
# > # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# > # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# > # minute <dbl>, time_hour <dttm>
これと同じことを素のRでしようと思うと、もっと冗長なコードになります:
flights[flights$month == 1 & flights$day == 1, ]
arrange()で行を並び替える
arrange()はfilter()と似たような動作しますが、違うのは行を絞り込んだり選択したりするのではなく、並べ替えることです。データフレームと、並べ替えに使う列名(あるいはもっと複雑な表現)を引数に取ります。一つ以上の列名を指定した時は、二つ目以降の列名は、その前の列名まででは並べ替え順位が同じだったものの順位を付けるのに使われます。
arrange(flights, year, month, day)
# > # A tibble: 336,776 x 19
# > year month day dep_time sched_dep_time dep_delay arr_time
# > <int> <int> <int> <int> <int> <dbl> <int>
# > 1 2013 1 1 517 515 2 830
# > 2 2013 1 1 533 529 4 850
# > 3 2013 1 1 542 540 2 923
# > 4 2013 1 1 544 545 -1 1004
# > # ... with 336,772 more rows, and 12 more variables: sched_arr_time <int>,
# > # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# > # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# > # minute <dbl>, time_hour <dttm>
列を降順に並べるにはdesc()を使いましょう。
arrange(flights, desc(arr_delay))
# > # A tibble: 336,776 x 19
# > year month day dep_time sched_dep_time dep_delay arr_time
# > <int> <int> <int> <int> <int> <dbl> <int>
# > 1 2013 1 9 641 900 1301 1242
# > 2 2013 6 15 1432 1935 1137 1607
# > 3 2013 1 10 1121 1635 1126 1239
# > 4 2013 9 20 1139 1845 1014 1457
# > # ... with 336,772 more rows, and 12 more variables: sched_arr_time <int>,
# > # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# > # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# > # minute <dbl>, time_hour <dttm>
select()で列を選択する
列がたくさんあるけれど実際に着目すべきはそのうちのいくつかだけ、という大きなデータセットを扱うことはしばしばあります。select()を使えば、役立ちそうなデータにすばやくズームインすることができます。これは、素のRでやろうとすると名前ではなく数字のインデックスで指定して行う操作です。
# Select columns by name
select(flights, year, month, day)
# > # A tibble: 336,776 x 3
# > year month day
# > <int> <int> <int>
# > 1 2013 1 1
# > 2 2013 1 1
# > 3 2013 1 1
# > 4 2013 1 1
# > # ... with 336,772 more rows
# Select all columns between year and day (inclusive)
select(flights, year:day)
# > # A tibble: 336,776 x 3
# > year month day
# > <int> <int> <int>
# > 1 2013 1 1
# > 2 2013 1 1
# > 3 2013 1 1
# > 4 2013 1 1
# > # ... with 336,772 more rows
# Select all columns except those from year to day (inclusive)
select(flights, -(year:day))
# > # A tibble: 336,776 x 16
# > dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay
# > <int> <int> <dbl> <int> <int> <dbl>
# > 1 517 515 2 830 819 11
# > 2 533 529 4 850 830 20
# > 3 542 540 2 923 850 33
# > 4 544 545 -1 1004 1022 -18
# > # ... with 336,772 more rows, and 10 more variables: carrier <chr>,
# > # flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
# > # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
select()は、中で補助的に使える関数がいくつかあります。たとえば、starts_with()、ends_with()、matches()やcontains()です。これらは、多くの変数名の中からある基準に合致するものだけをすばやく抜き出すことを可能にします。詳しくは?selectをご参照ください。
変数名を変えるには、名前付き引数をselect()に渡します。
select(flights, tail_num = tailnum)
# > # A tibble: 336,776 x 1
# > tail_num
# > <chr>
# > 1 N14228
# > 2 N24211
# > 3 N619AA
# > 4 N804JB
# > # ... with 336,772 more rows
しかし、select()は明示的に指定した変数以外はすべて除外してしまうので、あまり便利ではありません。代わりにrename()を使いましょう。
rename(flights, tail_num = tailnum)
# > # A tibble: 336,776 x 19
# > year month day dep_time sched_dep_time dep_delay arr_time
# > <int> <int> <int> <int> <int> <dbl> <int>
# > 1 2013 1 1 517 515 2 830
# > 2 2013 1 1 533 529 4 850
# > 3 2013 1 1 542 540 2 923
# > 4 2013 1 1 544 545 -1 1004
# > # ... with 336,772 more rows, and 12 more variables: sched_arr_time <int>,
# > # arr_delay <dbl>, carrier <chr>, flight <int>, tail_num <chr>,
# > # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# > # minute <dbl>, time_hour <dttm>
mutate()で新たな列を追加する
すでにある列を選択する他には、既存の列を使った関数で表される新しい列を追加するというのも便利な操作でしょう。これはmutate()の仕事です。
mutate(flights,
gain = arr_delay - dep_delay,
speed = distance / air_time * 60
)
# > # A tibble: 336,776 x 21
# > year month day dep_time sched_dep_time dep_delay arr_time
# > <int> <int> <int> <int> <int> <dbl> <int>
# > 1 2013 1 1 517 515 2 830
# > 2 2013 1 1 533 529 4 850
# > 3 2013 1 1 542 540 2 923
# > 4 2013 1 1 544 545 -1 1004
# > # ... with 336,772 more rows, and 14 more variables: sched_arr_time <int>,
# > # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# > # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# > # minute <dbl>, time_hour <dttm>, gain <dbl>, speed <dbl>
dplyr::mutate()はRの組み込み関数であるtransform()と似ていますが、mutate()なら今まさにつくった列を参照することもできます。
mutate(flights,
gain = arr_delay - dep_delay,
gain_per_hour = gain / (air_time / 60)
)
# > # A tibble: 336,776 x 21
# > year month day dep_time sched_dep_time dep_delay arr_time
# > <int> <int> <int> <int> <int> <dbl> <int>
# > 1 2013 1 1 517 515 2 830
# > 2 2013 1 1 533 529 4 850
# > 3 2013 1 1 542 540 2 923
# > 4 2013 1 1 544 545 -1 1004
# > # ... with 336,772 more rows, and 14 more variables: sched_arr_time <int>,
# > # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# > # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# > # minute <dbl>, time_hour <dttm>, gain <dbl>, gain_per_hour <dbl>
もし新しく作る変数だけが欲しい場合は、transmute()を使いましょう。
transmute(flights,
gain = arr_delay - dep_delay,
gain_per_hour = gain / (air_time / 60)
)
# > # A tibble: 336,776 x 2
# > gain gain_per_hour
# > <dbl> <dbl>
# > 1 9 2.378855
# > 2 16 4.229075
# > 3 31 11.625000
# > 4 -17 -5.573770
# > # ... with 336,772 more rows
summarise()で値を集約する
最後のverbはsummarise()です。これはデータフレームを一つの行にまとめます。
summarise(flights,
delay = mean(dep_delay, na.rm = TRUE)
)
# > # A tibble: 1 x 1
# > delay
# > <dbl>
# > 1 12.63907
後ほど、このverbがいかに有用かを目の当たりにするでしょう。
sample_n()とsample_frac()で無作為抽出する
sample_n()とsample_frac()は、行をランダムにサンプリングすることができます。サンプルの数を指定する場合はsample_n()、比率を指定する場合はsample_frac()を使いましょう。
sample_n(flights, 10)
# > # A tibble: 10 x 19
# > year month day dep_time sched_dep_time dep_delay arr_time
# > <int> <int> <int> <int> <int> <dbl> <int>
# > 1 2013 10 1 822 825 -3 932
# > 2 2013 8 2 712 715 -3 1015
# > 3 2013 5 10 1309 1315 -6 1502
# > 4 2013 10 28 2002 1930 32 2318
# > # ... with 6 more rows, and 12 more variables: sched_arr_time <int>,
# > # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# > # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# > # minute <dbl>, time_hour <dttm>
sample_frac(flights, 0.01)
# > # A tibble: 3,368 x 19
# > year month day dep_time sched_dep_time dep_delay arr_time
# > <int> <int> <int> <int> <int> <dbl> <int>
# > 1 2013 8 16 827 830 -3 928
# > 2 2013 11 4 1306 1300 6 1639
# > 3 2013 1 14 929 935 -6 1213
# > 4 2013 12 28 625 630 -5 916
# > # ... with 3,364 more rows, and 12 more variables: sched_arr_time <int>,
# > # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# > # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# > # minute <dbl>, time_hour <dttm>
ブートストラップ法によるサンプリングを行うにはreplace = TRUEを指定してください。必要なら、weigh引数で重み付けを指定することもできます。
関数間の共通性
もう気付いたかもしれませんが、これらのverb関数には以下の共通点があります:
- 第一引数はデータフレームです。
- 第二引数以降は、そのデータフレームをどうするかを記述します。その際、データフレーム中の列を
$を使わず直接参照することができます。 - 返り値は新しいデータフレームです。
これらの特性によって、複雑な結果を得るのに単純なステップをつなぎ合わせるということが容易になります。
これら5種類の関数は、「データ操作の言語(language of data manipulation)」の基礎をなすものです。基本として覚えておくべきtidyなデータフレーム3の操作方法はこの5つだけです。すなわち、行の並べ替え(arrange())、着目すべき観測と変数の抜き出し(filter()とselect())、既存の変数の関数であらわされる新しい変数の追加(mutate())、それに、複数の値の要約(summarise())です。「データ操作の言語」の残りの部分については、これら5種類の関数をさまざまなタイプのデータに適用していくと見えてくるでしょう。例として、グループ化されたデータに対してこれらの関数を使うとどのような挙動になるか見ていきましょう。
操作のパターン
dplyrのverbは、その操作の種類によって分類することができます。分類においては、セマンティクス、つまりその操作の意味についての議論をすることもあります。もっとも重要かつ有用な区分は、グループ化された操作かグループ化されていない操作か、というものです。この区分に加えて、selectとmutateの操作の違いについても詳しく理解しておくとよいでしょう。
グループに対する操作
dplyrのverbは単体でもとても有用ですが、データセット内の観測のグループごとに適用すれば更に強力になります。これを行うために、dplyrにはgroup_by()関数が用意されています。この関数は、データセットを指定したグループに分解します。そうして得られたオブジェクトに対して上に挙げたverbを適用すると、自動的にグループごとに操作が行われます。
グループ化は、verbの挙動に次のような影響があります。
- グループ化された
select()はグループ化されていないselect()と同じです。一つだけ違うのは、グループ変数(grouping variable)が常に保持されることです。 - グループ化された
arrange()はグループ化されていない時と同じです。ただし、.by_group = TRUEを指定した場合はグループ変数による並べ替えを先に行います。 -
mutate()とfilter()は、ウィンドウ関数(rank()、min(x) == xなど)と組み合わせると特に便利です。この詳細についてはvignette("window-functions")に記載されています。 -
sample_n()とsample_frac()は、グループごとに指定された数の行をサンプリングします。 -
summarise()は、グループごとに集約処理を行います。
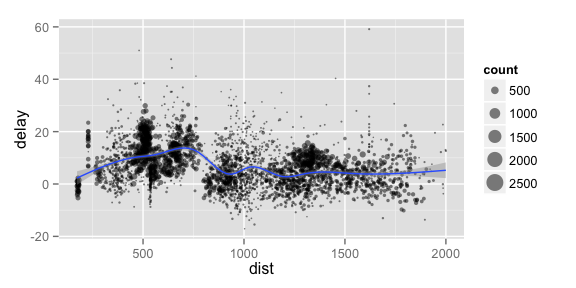
これから示す例では、データセット全体を個々の機体ごとのものに分割し、それぞれの機体について、機体数を数え(count = n())、飛行距離と遅延の平均を計算し(dist = mean(Distance, na.rm = TRUE)、delay = mean(ArrDelay, na.rm = TRUE))て要約します。そして、ggplot2を使って結果を出力します。
by_tailnum <- group_by(flights, tailnum)
delay <- summarise(by_tailnum,
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE))
delay <- filter(delay, count > 20, dist < 2000)
# Interestingly, the average delay is only slightly related to the
# average distance flown by a plane.
ggplot(delay, aes(dist, delay)) +
geom_point(aes(size = count), alpha = 1/2) +
geom_smooth() +
scale_size_area()
summarise()は、集計関数と組み合わせて使います。集約関数は、ベクトルを引数に取って単一の値を返します。たとえば、Rの組み込み関数にも、min()、max()、mean()、sum()、sd()、median()、IQRといったものがあります。dplyrには他にもいくつかの関数が用意されています。
-
n(): そのグループの観測点数 -
n_distinct(x):xが持つユニークな値の数 -
first(x)、last(x)、nth(x, n): これらは、x[1]、x[length(x)]、x[n]と同じような動作をしますが、値が欠損しているときの結果のコントロールに優れています。
たとえば、これらの関数を使って機体数と各行き先へのフライト数を出すことができます。
destinations <- group_by(flights, dest)
summarise(destinations,
planes = n_distinct(tailnum),
flights = n()
)
# > # A tibble: 105 x 3
# > dest planes flights
# > <chr> <int> <int>
# > 1 ABQ 108 254
# > 2 ACK 58 265
# > 3 ALB 172 439
# > 4 ANC 6 8
# > # ... with 101 more rows
複数の変数でgroup byしたとき、summarise()はグルーピングをひとつずつ解除していきます。これによって、データを徐々に集計していくことが容易になります。
daily <- group_by(flights, year, month, day)
(per_day <- summarise(daily, flights = n()))
# > # A tibble: 365 x 4
# > # Groups: year, month [?]
# > year month day flights
# > <int> <int> <int> <int>
# > 1 2013 1 1 842
# > 2 2013 1 2 943
# > 3 2013 1 3 914
# > 4 2013 1 4 915
# > # ... with 361 more rows
(per_month <- summarise(per_day, flights = sum(flights)))
# > # A tibble: 12 x 3
# > # Groups: year [?]
# > year month flights
# > <int> <int> <int>
# > 1 2013 1 27004
# > 2 2013 2 24951
# > 3 2013 3 28834
# > 4 2013 4 28330
# > # ... with 8 more rows
(per_year <- summarise(per_month, flights = sum(flights)))
# > # A tibble: 1 x 2
# > year flights
# > <int> <int>
# > 1 2013 336776
しかし、このように徐々にsummariseしていくのは注意が必要です。合計やデータ数を計算する場合は大丈夫ですが、平均や分散の場合は重み付けを考える必要があります。(中央値は正確には計算することができません)
select操作(Selecting operations)
dplyrの魅力的な機能のひとつは、tibble中の列をあたかも普通の変数かのようにして参照できることです。しかし、列名をそのまま参照する場合の文法は同じなので気付きにくいですが、verbごとにセマンティクスの違いがあります。同じ列名のシンボルであっても、select()に渡されたときとmutate()に渡されたときでは意味が異なります。
select操作は、列の名前か位置インデックスを想定しています。このため、列名をselect()に渡したとき、実際にそれらが表しているのはそのtibble内での位置です。以下の2つのコードはdplyrから見れば完全に等価です。
# `year` represents the integer 1
select(flights, year)
# > # A tibble: 336,776 x 1
# > year
# > <int>
# > 1 2013
# > 2 2013
# > 3 2013
# > 4 2013
# > # ... with 336,772 more rows
select(flights, 1)
# > # A tibble: 336,776 x 1
# > year
# > <int>
# > 1 2013
# > 2 2013
# > 3 2013
# > 4 2013
# > # ... with 336,772 more rows
つまりこれは、周辺の環境にある変数は、名前が列名のいずれかと被っていれば参照できないということです。次の例ではyearに5を代入しているが、select()の中ではyearはやはり1を表します。
year <- 5
select(flights, year)
ひとつ覚えておくといつか役立つかもしれないのは、このルールが適用されるのは素の名前か、c(year, month, day)やyear:dayといったselect用の呼び出しだけだということです。それ以外の場合はデータフレームの列はスコープに置かれません。これによって、selectのヘルパ関数の中で変数を参照することが可能になります。
year <- "dep"
select(flights, starts_with(year))
# > # A tibble: 336,776 x 2
# > dep_time dep_delay
# > <int> <dbl>
# > 1 517 2
# > 2 533 4
# > 3 542 2
# > 4 544 -1
# > # ... with 336,772 more rows
このセマンティクスはだいたい直観的ですが、以下の例のように分かりづらい差があることもあります。
year <- 5
select(flights, year, identity(year))
# > # A tibble: 336,776 x 2
# > year sched_dep_time
# > <int> <int>
# > 1 2013 515
# > 2 2013 529
# > 3 2013 540
# > 4 2013 545
# > # ... with 336,772 more rows
先に指定している引数yearはそのまま位置1を表します。後のyearは周辺の文脈で評価され、5つ目の列を表します。
長らくselect()が扱えるのは列の位置のみでした。しかし、dplyr 0.7以降では列の名前も扱えるようになっています。これによって、select()をプログラミングに使いやすくなりました。
vars <- c("year", "month")
select(flights, vars, "day")
# > # A tibble: 336,776 x 3
# > year month day
# > <int> <int> <int>
# > 1 2013 1 1
# > 2 2013 1 1
# > 3 2013 1 1
# > 4 2013 1 1
# > # ... with 336,772 more rows
注意してください、上のコードはあまり安全とは言えません。varsという列をこのtibbleに追加するかもしれないし、同じコードをvarsという列を持つ別のデータフレームに適用するかもしれないからです。こうした問題を避けるためには、変数をidentity()でラップして列名として解釈されないようにすることもできます。しかし、dplyrのすべてのverbで使える、より明示的で一般的なやり方があります。それは、!!演算子を使ってunquoteすることです。この演算子を使えば、dplyrはそのデータフレームの中は探さず、文脈の中に変数を探すようになります。
# Let's create a new `vars` column:
flights$vars <- flights$year
# The new column won't be an issue if you evaluate `vars` in the
# context with the `!!` operator:
vars <- c("year", "month", "day")
select(flights, !! vars)
# > # A tibble: 336,776 x 3
# > year month day
# > <int> <int> <int>
# > 1 2013 1 1
# > 2 2013 1 1
# > 3 2013 1 1
# > 4 2013 1 1
# > # ... with 336,772 more rows
この演算子はdplyrを自作の関数の中で使うときにとても役立ちます。より詳細についてはvignette("programming")を読めばわかるでしょう。しかし、unquoteを使おうとしているverbのセマンティクス、つまり、その関数がどのような値を受け付けるかを理解しておくことは重要です。ちょうど先ほど見たように、select()は列の名前と位置をサポートしています。しかし、mutate()などの他のverbはまた別のセマンティクスを持っています。
mutate操作(Mutating operations)
mutateのセマンティクスはselectのセマンティクスとは大きく違います。select()は列の名前か位置を想定していましたが、mutate()は列のベクトルを想定しています。説明のために少し小さなtibbleを作ってみましょう。
df <- select(flights, year:dep_time)
select()では、素の列名はtibble内での位置を表していました。一方、mutate()では、列のシンボルはそのtibbleのその列に格納されている実際のベクトルを表します。もし文字列や数字をmutate()に渡すと、以下のようになります。
mutate(df, "year", 2)
# > # A tibble: 336,776 x 6
# > year month day dep_time `"year"` `2`
# > <int> <int> <int> <int> <chr> <dbl>
# > 1 2013 1 1 517 year 2
# > 2 2013 1 1 533 year 2
# > 3 2013 1 1 542 year 2
# > 4 2013 1 1 544 year 2
# > # ... with 336,772 more rows
mutate()は長さ1のベクトルを受け取り、それをデータフレームの新たな列として解釈します。これらのベクトルはデータフレームの行数と一致する長さになるまで引き延ばされ(recycle)ます。これを踏まえると、"year" + 10といった表現式をmutate()に指定するのは意味がないとわかるでしょう。これでは文字列に10を足し合わせることになってしまいます! 正しい表現式は以下です。
mutate(df, year + 10)
# > # A tibble: 336,776 x 5
# > year month day dep_time `year + 10`
# > <int> <int> <int> <int> <dbl>
# > 1 2013 1 1 517 2023
# > 2 2013 1 1 533 2023
# > 3 2013 1 1 542 2023
# > 4 2013 1 1 544 2023
# > # ... with 336,772 more rows
同様に、正しい列を表している値を持つ変数ならunquoteしてコンテキストからその値を持ってくることができます。この値の長さは、1か(この場合はベクトルが引き延ばされます)、行数と同じである必要があります。次の例では、新しいベクトルを作成し、それをデータフレームの列として追加しています。
var <- seq(1, nrow(df))
mutate(df, new = var)
# > # A tibble: 336,776 x 5
# > year month day dep_time new
# > <int> <int> <int> <int> <int>
# > 1 2013 1 1 517 1
# > 2 2013 1 1 533 2
# > 3 2013 1 1 542 3
# > 4 2013 1 1 544 4
# > # ... with 336,772 more rows
group_by()は良い例です。group_by()はselectのセマンティクスだと思われるかもしれませんが、実際にはmutateのセマンティクスを持っています。これは変更を加えた列でグループ化したいときにとても便利です。
group_by(df, month)
# > # A tibble: 336,776 x 4
# > # Groups: month [12]
# > year month day dep_time
# > <int> <int> <int> <int>
# > 1 2013 1 1 517
# > 2 2013 1 1 533
# > 3 2013 1 1 542
# > 4 2013 1 1 544
# > # ... with 336,772 more rows
group_by(df, month = as.factor(month))
# > # A tibble: 336,776 x 4
# > # Groups: month [12]
# > year month day dep_time
# > <int> <fctr> <int> <int>
# > 1 2013 1 1 517
# > 2 2013 1 1 533
# > 3 2013 1 1 542
# > 4 2013 1 1 544
# > # ... with 336,772 more rows
group_by(df, day_binned = cut(day, 3))
# > # A tibble: 336,776 x 5
# > # Groups: day_binned [3]
# > year month day dep_time day_binned
# > <int> <int> <int> <int> <fctr>
# > 1 2013 1 1 517 (0.97,11]
# > 2 2013 1 1 533 (0.97,11]
# > 3 2013 1 1 542 (0.97,11]
# > 4 2013 1 1 544 (0.97,11]
# > # ... with 336,772 more rows
これは、group_by()に列名を渡すことができない理由です。もしやると、行数の長さまで引き延ばされた文字列ベクトルを保持する新しい列ができることになります。
group_by(df, "month")
# > # A tibble: 336,776 x 5
# > # Groups: "month" [1]
# > year month day dep_time `"month"`
# > <int> <int> <int> <int> <chr>
# > 1 2013 1 1 517 month
# > 2 2013 1 1 533 month
# > 3 2013 1 1 542 month
# > 4 2013 1 1 544 month
# > # ... with 336,772 more rows
selectのセマンティクスでグループ化するのも便利なこともあるので、group_by_at()という別バージョンのgroup_by()が用意されています。dplyrでは、_at()というサフィックスが後ろについてバージョンの関数は二番目の引数にselectのセマンティクスを持っています。必要なのはvars()でラップすることだけです。
group_by_at(df, vars(year:day))
# > # A tibble: 336,776 x 4
# > # Groups: year, month, day [365]
# > year month day dep_time
# > <int> <int> <int> <int>
# > 1 2013 1 1 517
# > 2 2013 1 1 533
# > 3 2013 1 1 542
# > 4 2013 1 1 544
# > # ... with 336,772 more rows
_at()や_if()などの別バージョンの関数については?scopedのヘルプページをご参照ください。
パイプ
dplyrのAPIは、関数呼び出しに副作用がないという意味で関数型です。毎回、返ってくる結果を変数に保存しなくてはいけません。このため、すっきりしたコードが書きづらく、とりわけ一度にいくつものデータ操作をしたいときには難しいです。やるのであれば、以下のように段階的に処理を行うか、
a1 <- group_by(flights, year, month, day)
a2 <- select(a1, arr_delay, dep_delay)
a3 <- summarise(a2,
arr = mean(arr_delay, na.rm = TRUE),
dep = mean(dep_delay, na.rm = TRUE))
a4 <- filter(a3, arr > 30 | dep > 30)
中間結果を保存しない場合には、関数をそれぞれの内側に入れ込んでしまう必要があります。
filter(
summarise(
select(
group_by(flights, year, month, day),
arr_delay, dep_delay
),
arr = mean(arr_delay, na.rm = TRUE),
dep = mean(dep_delay, na.rm = TRUE)
),
arr > 30 | dep > 30
)
# > Source: local data frame [49 x 5]
# > Groups: year, month [11]
# >
# > year month day arr dep
# > (int) (int) (int) (dbl) (dbl)
# > 1 2013 1 16 34.24736 24.61287
# > 2 2013 1 31 32.60285 28.65836
# > 3 2013 2 11 36.29009 39.07360
# > 4 2013 2 27 31.25249 37.76327
# > .. ... ... ... ... ...
これは、処理の順序が内側から外側に向かっているため読みづらくなっています。引数が関数から遠く離れてしまっています。この問題に対処するために、dplyrには%>%という演算子があります。x %>% f(y)はf(x, y)になります。これで、複数のデータ操作を左から右・上から下に読めるように書きなおすことができます。
flights %>%
group_by(year, month, day) %>%
select(arr_delay, dep_delay) %>%
summarise(
arr = mean(arr_delay, na.rm = TRUE),
dep = mean(dep_delay, na.rm = TRUE)
) %>%
filter(arr > 30 | dep > 30)
その他のデータ形式を扱う
データフレームと同じように、dplyrは他の形式で保存されているデータも扱うことができます。たとえば、data.tableや、データベース、多次元配列です。
data.tableクラスオブジェクト
dplyrは、すべてのverbについてdata.tableのメソッドが使えます。data.tableをすでに使っているなら、dplyrの文法でデータ操作をしつつ、他のすべての操作はdata.tableで行う、といったことが可能です。
複数の操作を行うなら、data.tableは一般に複数のverbを同時に使うことができるので、より高速でしょう。たとえば、data.tableならmutateとselectを一度に行うことができます。data.tableは賢いので、これから捨て去ろうとしている行について新しい変数を計算しても無駄だとわかっています。
dplyrをdata.tableとともに使う利点は、
- 共通のデータ処理作業については、data.tableのreference semanticsから離れることができ、誤ってデータを書き換えてしまうことを防ぎます
- ひとつの複雑な方法を
[を使ってやる代わりに、単純な方法が使えます
データベースとの連携
dplyrはデータベースに対しても同じverbを使うことができます。SQLの生成はdplyrが面倒を見てくれるので、言語間を定期的に行ったり来たりするという認知論的挑戦を避けることができます。この機能を使いたければ、dbplyrパッケージをインストールし、詳細について説明しているvignette("dbplyr")を読んでください。
多次元配列・キューブ
tbl_cube()は、多次元配列やdata cubeへの実験的なインターフェースを提供します。もしあなたがこの形式のデータをRで扱っているなら、あなたのニーズについてもっと理解したいのでぜひ連絡をください。
他のツールとの比較
あらゆる既存の選択肢と比較して、dplyrは、
- data.frameでもdata.tableでもリモートのデータベースでも同じ関数群で扱えるように、データがどのように保存されているかを抽象化します。これによって、データストレージの面倒を見ることではなく、達成したいことをやるのに集中することができます。
- 何ページものデータを自動的にスクリーンに出力したりしない、気の利いたデフォルトの
print()があります。(これはdata.tableの出力にインスパイアされました)
baseの関数と比較して、
- dplyrには一貫性があります。関数は同じインタフェースを持っています。このため、一度ひとつの関数を覚えてしまえば、他の関数も簡単に使えるようになります。
- baseの関数はベクトルを中心に考えている傾向があります。dplyrはデータフレームを中心に考えています。
plyrと比較して, dplyrは、
- ずっとずっと速いです。
- より考え抜かれたjoin関数群があります。
- データフレームを扱うためのツールしか提供していません。(例:多くのdplyrの関数は
ddply()+様々な関数と同等で、do()はdlply()と同等です)
仮想データフレーム使う方法と比べて、
- 仮想データフレームは、手元にデータフレームがあるかのように使うことはできません。lmなどを実行するときは、やはり手動でデータを持ってくる必要があります。
- 仮想データフレームにはRの集計関数がありません。