ABEJA Advent Calendar
- 本記事はABEJA Advent Calendarの21日目の記事になります。
- ABEJAのWebSite
はじめに
昨年末にABEJA Advent Calenderで「AIをシステムに実装する方法」というタイトルでシステムエンジニアの方向けにQiitaで書いたところそれなりに反響があったので、今回はAIのモデルをオンライン環境で評価する方法の部分についてより詳しい内容を書きたいと思います。ここで言うオンライン環境とは製品のProduction環境、特にオンラインで実行できる環境という形で読んでいただけると良いと思います。
今後ありとあらゆる産業課題に対してAIが浸透することは確実であると言えます。AIの民主化を本当に推し進める上では、今までAIを活用していなかったシステムエンジニアの方々が一番のキーパーソンであると断言できます。よって本エントリを特に読んで欲しい方を下記としています。
- ITのシステムエンジニアの方(データサインティスト、MLエンジニアではない)
- AIのモデルをどのように評価すればよいか経験が無く困っている方
AIのモデルを評価する理由
そもそもAIのモデルを評価しなければならない理由について記載をします。AIを活用するユーザーとしての期待はAIのモデルに対して新しいデータを入力した時に、AIが正しい結果を予測値として出力してくれることにあります。このデータ入力 => 予測値出力という処理の中でシステムパフォーマンスとしての性能評価と予測値の出力結果の精度評価の2つの項目を必ずチェックする必要があります。
-
①システム性能評価
- AIに対してデータを入力、予測値が出力されるまでの処理時間が機能要件として満たされているかどうか
- 性能評価をやるのは、このAIモデルをサービスの中に組み込んだ際にこの処理能力でサービスが成り立つレベルかどうかの確認が必要なため
-
②モデルの精度評価
- AIから出力される結果の答え合わせをした際に、期待されている以上の一致率であるかどうか
- 精度評価をやるのは、このAIモデルをサービスの中に組み込んだ際にこの精度で十分にサービスが成り立つレベルかどうかの確認が必要なため
ここから後の話はモデルの精度評価をどのように行うかの事例について説明をしていきます。
過去に機械学習の精度評価方法についてBlogにエントリしたことがあるので、詳細の精度評価基準を知りたい方は下記を参考にしてください。
AIのモデルの精度評価を行うタイミング
AIのモデルの精度評価ってどのタイミングで行うかについて記載します。上のURLはGoogle CloudのMLOps(AIのモデル構築や運用に必要なプロセス)について記載されているものですが、MLOpsの中でModel evaluation, validationという項目が精度評価を行うタイミングとして定義されています。
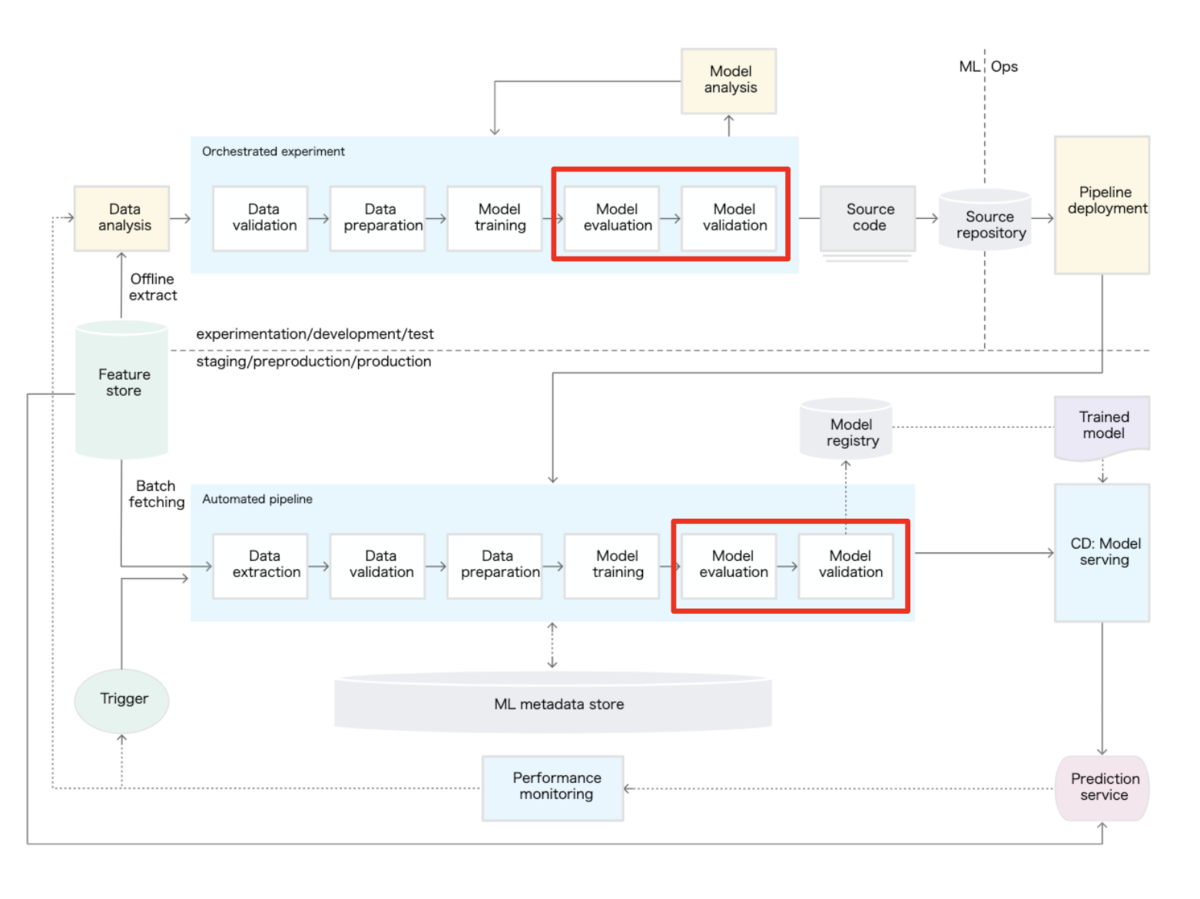
Model evaluation, validationの項目が2箇所に存在していますが、これは下記の2つのポイントがあると理解するのが良いと思います。
- オフライン環境での精度評価(Development環境での精度評価)
- オンライン環境での精度評価(Production環境での精度評価)
In addition to offline model validation, a newly deployed model undergoes online model validation—in a canary deployment or an A/B testing setup—before it serves prediction for the online traffic.
Development環境下においては理想は学習などの各stepの実行が自動化されることとしながらも、簡易にモデルの精度評価ができるようにし、システムエンジニアも各評価指標に合わせて評価指標の値が比較対象となる値より上回っていることを確認します。当然にこのDevelopmentでのpipeline構築は、同様な状態としてProduction環境のpipelineとしてDeployされる必要があります。Production環境にDeployされた後に再度MLOpsのpipelineを実行。Production環境では自動化された状態で実行され、製品サービスとしてのモデルを構築します。Production環境で構築された新しいモデルについて、最初から全てのユーザーに対して適用してしまうと影響範囲が大きいので、全適用のリリースをする前にカナリアリリースやA/Bテストを重ねた上で問題ないことを確認し、適用範囲を広げていきます。
オンライン環境(Production環境)でのAIモデルの精度評価例
オンライン環境(Production環境)を重視
オフライン環境(Development環境)ではオンライン環境と異なりサービスINした状態でのテストではなく、過去のログデータなどを基に精度を評価するため、オフライン環境での精度評価はオンライン環境(Production環境)への導入を効率よく行うための準備テストとして考えてもらうと良いと思います。重視すべきなのはあくまでオンライン環境(Production環境)であり、そこで明確な評価指標を基に新しいモデルの優劣を決めて、適用範囲を広げるかもしくは新しいモデルを取り下げるなどの判断が必要になります。
オンライン環境(Production環境)でのテストの具体例
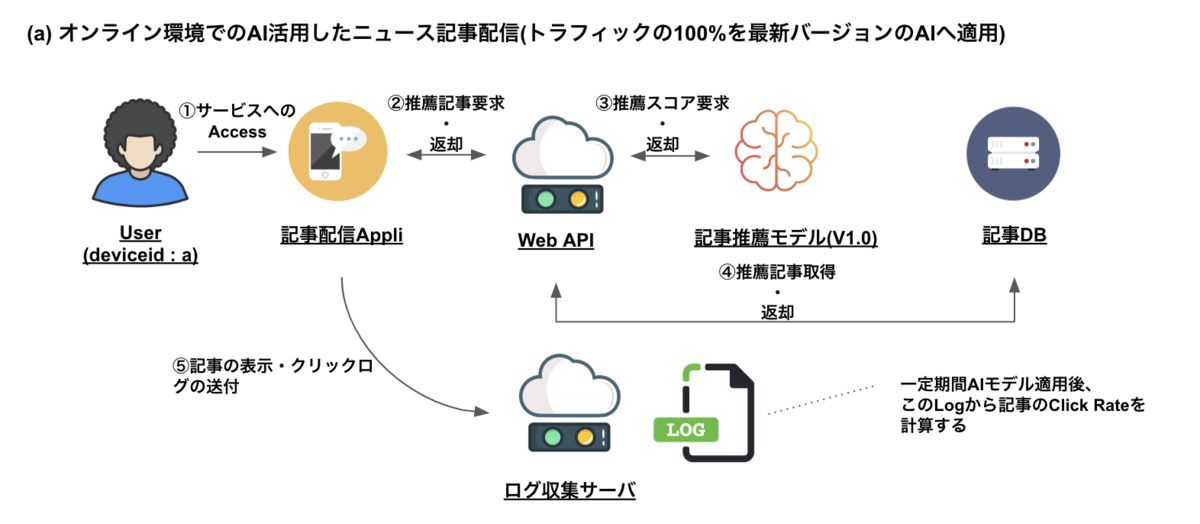
オンライン環境での評価をわかりやすく説明するための例として、ニュースアプリに推薦記事を配信することをAIを用い、ニュースの一覧から詳細ページへのClick Rateを改善することを行うことを挙げます。上図のような形で本番環境運用中のstable AIモデルに対して100%のトラフィックが割り当てられている状態から下記に記載された条件によるA/Bテストを行う状態を作ります。ちなみに下記で出ているトラフィックの70%と30%の分割の数値はあくまで目安です。いきなりテスト用のトラフィックを増やしすぎるとサービスへの影響を考えてこの数値を用いています。
- 解く課題 : 新しく構築したAIモデルによりニュース記事のパーソナライズ配信を行い、ユーザー全体のClick Rateを改善させる
- 評価方法 : 複数のAIモデルをオンライン環境のトラフィックを利用し、A/Bテストを行う
- 評価指標 : 過去にプロダクション環境に投入したAIモデルと比較して、Click Rateが改善するか。一定期間のアクセスログを回収し、モデルの毎に比較
- 比較検証 : ①プロダクション環境に投入し現在サービスとして運用中のstableのAIモデルのバージョン(例 : V1.0) と ②新しく作成した最新のテストAIモデルバージョン(例 : V1.1)
- 適用範囲 : 全ユーザートラフィックの30%を活用し、15%をstableのAIモデルバージョン(例 : V1.0)、15%を最新のテストAIモデルバージョン(例 : V1.1)に当てはめる(残りの70%についはstableのAIモデルバージョンが適用されている
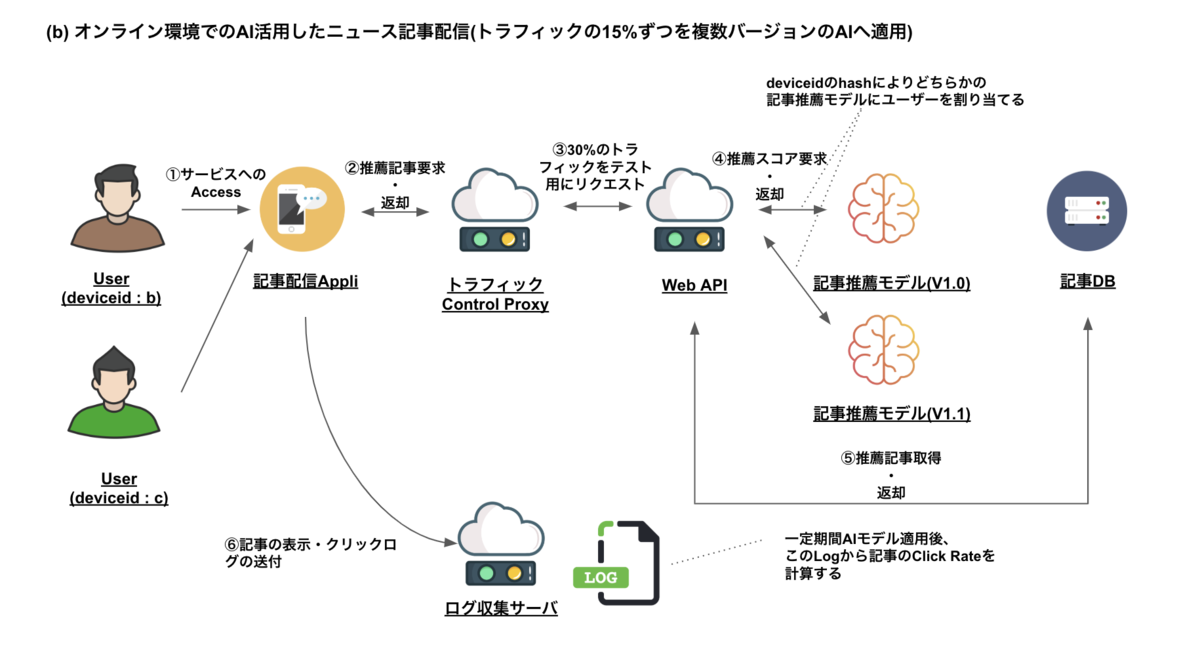
A/Bテストを実施する環境をオンラインで構築すると上記のような構成になると思います。上記の例としてはテスト対象のユーザーを全体の30%定め、そのうちユーザーをdeviceidのhashによりstableとテストのバージョンにそれぞれを割り当てるため理論的には15%ずつのトラフィックを流すことになります。ここでの例では70%の本番、30%のテストトラフィックはproxy側でcontrolする状態を作り、web api側はあくまでもユーザの振り分け・スコアのリクエスト・記事の取得のみの役回りに留めてあります。また15%ずつトラフィックを区切らず、70%と30%で評価すれば良いのではという意見もあがりそうですが、stableとテスト用のAIモデルの表示回数を同一にした検証を行いたいので、あえて30%の中を2分割しています。
ここでの例ではユーザーをdeviceidによりhash化し、その結果によりどちらかのAIモデルに適用するかをのA/Bテストとして実施していますが、どちらかのユーザー郡にClickしやすい傾向の人が偏ってしまう可能性もあるので、ユーザーベースではなく表示ベースで適用するモデルを選択し、Click Rateを評価する方法もあります。(後者の場合、一人のユーザーに対してどちらのモデルも適用される形になります)
Click Rateの集計は図に記載されているログ収集サーバーに記録されたアクセスログとクリックログの情報を基に算出します。A/Bテストの期間はトラフィックの量にも依存しますが、どんなに短くても1週間ぐらいの期間を設定したほうが良いと思います。
評価対象のメッシュ
上記のA/Bテストはあくまで全体のユーザーに対しての評価でしたが、更に細かく評価対象のメッシュを細かくしていく事もできます。例えば利用しているユーザー属性(年齢、性別、興味カテゴリ)がサービス特性上既に分かっている場合、同一の属性内でに各モデルのClick Rateを評価することも可能です。ただし、最初から細かすぎるメッシュで比較し、それぞれAIモデルの勝ち負け表を記載するよりは、最初は大雑把な状態で比較、それで詳細を見たい時にメッシュを細かくするような流れで考えると良いでしょう。当然システムとしては細かいメッシュで評価可能なように、例えばログ収集サーバー上で属性ごとにClick Rateが集計可能なログフォーマットなどは予め考慮しておく必要があります。
最後に
ABEJAは今後もがんがんAIテクノロジー領域を攻めていきます。
新しい仲間も絶賛大募集中です!興味がある方はぜひお声がけください。