はじめに
はじめまして。
株式会社アドベンチャーのへっぽこサーバーサイドエンジニア、須藤と申します。
歳をとるにつれ、色々とやるやる詐欺が多くなってきてる中、今回、会社としてAdventカレンダーをやろうということで、
- 発信側として技術ブログを書いてみる
- AIに触れてみる
というやるやる詐欺リスト消化のため、そして、来たるクリスマス、誰も選んでくれないので、表題のプログラムを作成して癒されたいと思います。
(直前で他のメンバーとお題が被って焦りましたが、私の方はより初級なのできっと大丈夫。ヘーキヘーキ。区別できてる![]() )
)
少々長いし文字も多いのですが、ご容赦ください![]()
ちなみに他のリストは
・Railsさわる
・Vue.jsさわる
・部屋掃除する
などです。
AIについて
ここ数年で一気に広まりましたね。「そろそろうちも導入するか」とお偉方から言われてる企業もあるかと思います。
かつてのクラウドと同じように、細かいことはわからないが、とりあえず導入しとけば全て解決、みたいに思われてる節も見受けられますが。。
比較的最近から賑わったAIですが、実は随分昔、幼少期に身近なところで触れていました。
そう、国民的RPG、ドラゴンクエストの4作目、ドラクエ4(FC版)です。
総勢8人の中で、コマンド選択できるのは勇者ただ1人で、仲間は学習型AIだったのです。
例えば、クリフトは初見の敵に対して、効かないにもかかわらず勝手にザラキを唱えますが、
二度目はそれを学習して別行動を取っていたようです。へぇぇ。(記憶にない)
そうとは知らず、クリフト使えねぇ、やっぱミネアに、って人多いかとおm(略)
ドラクエ4は今から28年前に発売なので、そう思うとゲーム業界のエンジニアって、やはりすごいなぁと感じます。
まずはPython触ってみる
AIに最適な言語だとPythonが出てきますが、以前会社の人に「なんでPythonなの?」と
聞かれ、調べたことがあります。ざっくり言うと
- とある人がちょっと計算に便利なライブラリを作った
- とある企業がとても計算に強いパッケージを作った
- オープンソースなので開発コミュニティが賑わった
PythonはPHPと同じスクリプト言語で、元々計算向けに作ったわけじゃないそうなので
1.の人の好きな言語がたまたまPythonだったから、というのは過言ではないと思います。
言語の流行り廃りと一緒ですね。風前の灯火だったRubyがRailsで爆発的に伸びたとか、
JavascriptがGoogle Mapで一気に使える子認識されたとか。
そのときすごい技術力を持った人の好み、ゴリ押し、など、背景を調べるとちょっとおもしろいです。
Pythonの機械学習ライブラリで有名なところは以下があります。(下のほうが新し目)
・NumPy
・SciPy
・matplotlib
・pandas
・scikit-learn
とりあえず、上記の中から「scikit-learn」を使って何か簡単なものを作ってみます。
(サイキット・ラーンです。寿司キットではないです。)
Python学習のど定番ライブラリということなので、入門に良いですね。
開発環境にはエディター・実行環境を1つにまとめた便利ツール「Jupyter Notebook」を使います。
そして上記のライブラリ群と、Python本体をまとめた「Anaconda」をインストールしときます。
※ インストール工程は割愛。毎度のことながら、すんなりとはいきませんでした![]()
※ すんなりいかなかったので、Python本体、ライブラリを個別に入れました、、
お題はそうですね。させるほどではないけど、AND演算子の動きを機械学習させてみます。
AND演算子はビット演算の1つで 全部1のときだけ1が返る、あれです。
まず手始めに誤った学習データを与えてみます。
Pythonで記述。セミコロンがないと、、なんか、、そわそわします。
# ライブラリのインポート
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
## 学習データ用意
# パターン
learn_data = [[0,0], [0,0]]
# 覚えてほしい結果(カンマごとに上の一次元目の配列に対応)
learn_result = [0, 1]
# 使用アルゴリズム(今回はLinearSVC)
# SVMアルゴリズムは2クラス分類(0,1など)用だそうです。
clf = LinearSVC()
# パターンと覚えてほしい結果を食べさせて学習させてみる
clf.fit(learn_data, learn_result)
# テストデータを与えてみる(全パターン)
test_data = [[0,0], [1,0], [0,1], [1,1]]
test_result = clf.predict(test_data)
# 結果出力
print(test_data, "の結果:", test_result)
# 正解もわかるので正解率も出してみる
expect_result = [0, 0, 0, 1]
print("正解率 = ", accuracy_score(expect_result, test_result) * 100, "%")
AIが出した答え: [1 1 1 1]
正解率 = 25.0 %
はい。見事にアホな子に育ちました。
そもそも[0,0]のときに、0にもなる、1にもなるという学習をさせてるので
回答が不安定です。何回か実行すると、たまに0を返すので正解率75%にもなります。
次は学習データをきちんとさせてみます。
## 学習データ用意
# パターン
learn_data = [[0,0], [1,0], [0,1], [1,1]]
# 覚えてほしい結果
learn_result = [0, 0, 0, 1]
学習データだけ変えてみました。他のコードは全く一緒です。
結果は、、
AIが出した答え: [0 0 0 1]
正解率 = 100.0 %
ほぼカンニングみたいですが、当然何回やっても100%です。
このように、今はライブラリや環境が充実しているので、手軽に試せます。
本題
ではいよいよワイン選びをしてみます。
書籍と睨めっこしてなんとなくわかったのが、機械学習で重要なのは主に以下4点でしょうか。
1.学習データの用意
2.テストデータの用意
3.1と2の答えの用意
4.アルゴリズムの選定
1は言わずともわかりますね。
2は学習がうまくいっているか確認するためのデータです。自信があるならいらないです。
3は1と2が何をもって正しいとするか、の値です。機械学習ではこれを「ラベル」と呼びます。
4は正解率に大きく作用します。ワイン選びに前回の2クラス分類は使いづらそうですね。
3について、正解は人によって様々です。
ワインデータで言えば 「フランスのシャトー・マルゴー 2005年は98点」というデータの場合、
仮に点数をラベルとするなら、「フランスのシャトー・マルゴー 2005年」がデータで「98点」がラベル、ということになります。
上記を学習させて、同じようなテストデータを与えたら、98点!と算出してくれたら優秀な子ということになります。
テストデータにもラベルが必要な理由は、AIが出した点数と、ラベルで定義している点数を比較して
正解率を出すためです。これによって信頼できるAIかどうかが判断できるわけですね。
90%超えてたら世に公開してもいいんじゃないでしょうか。
そんなわけでまずは学習データとテストデータを用意します。
初めは神の雫に出てきたワインと、そのときのキャラクターのお、、おぉぉ、、な表現を点数化してリストにしようと思いましたが、いまいち点数化しづらいのでやめました。

理想としては銘柄、産地、ヴィンテージ(年代)、パーカーポイント(※)がリストになっていると
非常にありがたかったのですが、散々探してみましたが、全然見当たらず、どこかの英語サイトで
$100払ってやっと見れそうな感じでしたので、過程でみつけたamazonを使うことにします。
※ロバート・パーカーJrというワイン評論家のポイント。めっちゃ市場価格に影響がでる
amazonでワインを検索したら左側にスコア絞り込みがあることに気づきました。
これを5段階評価として、各評価別に5本ずつぐらい抜粋していきます。
80-84 → 1、85-89 → 2 という具合で、1が一番低いということにします。

このリストの各詳細ページを見ると

こんな欄がありますので、これの必要な部分をExcelに転記していきます。
。。。これ、地味に大変です。
たまに産地とかヴィンテージ(年代)がなかったりするので、
なかったらamazon取扱開始年を入れちゃいました。
んで、できたのがこちら
| name | year | country | area | color | price | star | point |
|---|---|---|---|---|---|---|---|
| イエローテイル | 2012 | オーストラリア | その他 | 赤 | 916 | 4 | 1 |
| デリカート | 2015 | アメリカ | カリフォルニア | 赤 | 2208 | 0 | 1 |
| クロード・デュガ | 2014 | フランス | ブルゴーニュ | 赤 | 6159 | 0 | 1 |
| シャトー・クーフラン | 2006 | フランス | ボルドー | 赤 | 4860 | 0 | 1 |
| イエローテイル・シラーズ | 2009 | オーストラリア | その他 | 赤 | 916 | 4.5 | 2 |
| ベリンジャー・ファウンダース・エステート | 2015 | アメリカ | カリフォルニア | 赤 | 2450 | 5 | 2 |
| モンテス・アルファ | 2012 | チリ | その他 | 赤 | 2138 | 3.5 | 2 |
| コロンビア・クレスト・グランド・エステーツ | 2014 | アメリカ | ワシントン | 赤 | 2830 | 0 | 2 |
| エヴォディア | 2012 | スペイン | カラタユー | 赤 | 1287 | 4 | 3 |
| マルケス・デ・リスカル・ティント・レセルバ | 2012 | スペイン | リオハ | 赤 | 2242 | 3.5 | 3 |
| ラ・キュベ・ミティーク | 2009 | フランス | フランス | 赤 | 1399 | 3.5 | 3 |
| ルーチェ・デッラ・ヴィーテ・ルチェンテ | 2013 | イタリア | トスカーナ | 赤 | 4268 | 0 | 3 |
| ヌマンシア | 2010 | スペイン | トロ | 赤 | 5810 | 5 | 4 |
| レイク・ブリーズ | 2013 | オーストラリア | ラングホーン・クリーク | 赤 | 3456 | 0 | 4 |
| ドッグ・リッジ | 2013 | オーストラリア | マクラーレン・ヴェイル | 赤 | 5832 | 0 | 4 |
| バッカ ロッサ | 2012 | イタリア | ラツィオ | 赤 | 4133 | 5 | 4 |
| ペンフォールズ g3 | 2018 | オーストラリア | その他 | 赤 | 324000 | 0 | 5 |
| ギガル・コート・ロティ・ ラ・ランドンヌ | 2015 | フランス | その他 | 赤 | 44094 | 0 | 5 |
| シャプティエ・エルミタージュ・ル・メアル・ルージュ | 2009 | フランス | その他 | 赤 | 39774 | 0 | 5 |
| ペンフォールズ・グランジ | 2015 | オーストラリア | その他 | 赤 | 108000 | 0 | 5 |
一番重要なのは一番右のpointです。これをラベルに使います。
あとstartは★の数です。とりあえずいれときました。
んん、、全然知らんワインばっかり、、もっと素人でもわかる有名どころも欲しかったなぁ、、
しかもいきなり評価1が4本しかなかったので、各評価左上から4本ずつ転記してみました。
なんか確実に評価5の価格が全てをぶち壊している気がします、、
そもそも学習データにするには数が少なすぎますが、この際良しとします。
コードを書いていきます。
# 色んなライブラリ読み込み
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
import pandas as pd
# データ読み込み
wine = pd.read_csv("ワインリスト.csv", sep=",", encoding="utf-8")
# データをラベルとデータに分離
y = wine["point"]
x = wine.drop("point", axis=1)
# 文字列は学習できないっぽいので数値に
x["name"], _ = pd.Series(x["name"]).factorize()
x["country"], _ = pd.Series(x["country"]).factorize()
x["area"], _ = pd.Series(x["area"]).factorize()
x["color"], _ = pd.Series(x["color"]).factorize()
# 学習用とテスト用に分割(便利関数!)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# モグモグさせる
model = RandomForestClassifier()
model.fit(x_train, y_train)
# テストデータを評価してみる
y_pred = model.predict(x_test)
# 正解率を見てみる
print("正解率=", accuracy_score(y_test, y_pred))
便利関数で20個の学習データのうち、2割(4個)をテストデータとして切り離します。
そして、今回は「ランダムフォレスト」というアルゴリズムを使っていきます。
二分木みたいなツリー構造をいっぱい作って、多数決で決めるらしいです。
中身はよくわかりませんが、精度は良いみたいです。
最初CSVをそのまま分類器にかけたら型が違うみたいなエラーが出たので
途中で全部数値化してます。文字列ダメみたいです。
では正解率を見てみます。
正解率= 50.0 %
。。。ちょっと学習データが足りなすぎたのか、一か八かな子が出来上がりました。
何度か実行すると25%〜100%まで変動し、体感で平均50%ぐらいだったので50%とします。
本来AIとしてはダメダメですが、アホな子でも可愛い我が子なので、この子に判定してもらいます。
どうせならりんなみたいに名前でもつけてみようかな。
クリスマス由来にしようかと思いましたが、思いつかなかったので、正月由来で「おもち」にします。
どこの中から選んでもらうかなと色々検索してみましたが、楽天にしてみました。
学習データがamazonで、探すデータが楽天というのもまたオツです。
★評価があるのも都合がよいです。
意図せず学習データが赤ワインだらけになってしまったので、楽天の赤ワインランキングから選んでもらおうと思います。 数が多いので1位〜50位ぐらいまでにしときます。
セットものや、銘柄・年代が被っているものは飛ばします。
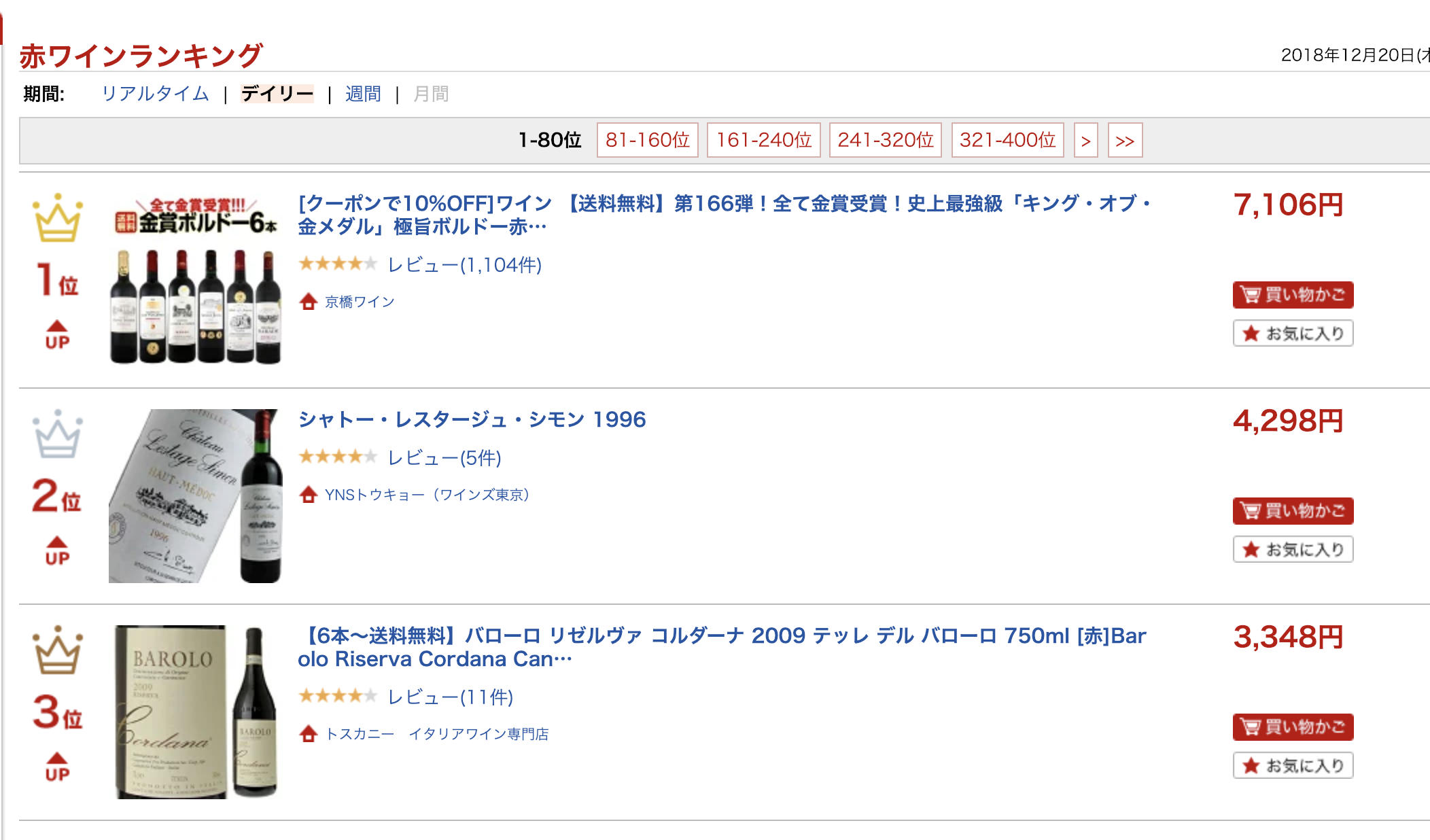
また転記作業をはじめます。スクレイピングでやれよ、とかはご勘弁ください。
| name | year | country | area | color | price | star |
|---|---|---|---|---|---|---|
| シャトー・レスタージュ・シモン | 1996 | フランス | ボルドー | 赤 | 4298 | 4 |
| バローロ・リゼルヴァ・コルダーナ | 2009 | イタリア | ピエモンテ | 赤 | 3348 | 4 |
| バローロ・リゼルヴァ・コルダーナ | 2010 | イタリア | ピエモンテ | 赤 | 3488 | 0 |
| ルモワスネ・ニュイ・サン・ジョルジュ | 1979 | フランス | ブルゴーニュ | 赤 | 21500 | 0 |
| ラ・ヴィ | 2016 | ルーマニア | ムンテニア | 赤 | 1096 | 0 |
| バローロ・テルツェット | 2014 | イタリア | ピエモンテ | 赤 | 2041 | 0 |
| シャトー・ラ・クロワ・サン・ジョルジュ | 2014 | フランス | ボルドー | 赤 | 8046 | 0 |
| ボデガス・アルト・モンカヨ | 2016 | スペイン | その他 | 赤 | 6458 | 0 |
| プリミティーヴォ・ディ・マンドゥーリア | 2017 | イタリア | モンテポルツィオ・カトーネ | 赤 | 1231 | 4 |
| ブルゴーニュ・ルージュ・クーヴァン・デ・ジャコバン | 2015 | フランス | ブルゴーニュ | 赤 | 2030 | 0 |
| オーパス・ワン | 2014 | アメリカ | カリフォルニア | 赤 | 43800 | 0 |
| シャノン・ヴィンヤード・マウント・バレット・メルロー | 2013 | 南アフリカ | エルギン | 赤 | 6026 | 5 |
| ランゲ・ネッビオーロ・カーサ・ヴィニコラ・ニコレッロ | 2002 | イタリア | ピエモンテ | 赤 | 1760 | 4 |
| アナベラ・プラチナム・オークヴィル・ナパ・ヴァレー・カベルネ・ソーヴィニヨン | 2015 | アメリカ | カリフォルニア | 赤 | 4147 | 0 |
| サンタ・ヘレナ・アルパカ・カベルネ・メルロー | 2015 | チリ | セントラル・ヴァレー | 赤 | 6098 | 4 |
| アンティノリ・ティニャネロ | 2015 | イタリア | トスカーナ | 赤 | 8964 | 0 |
| シャトー・ラ・トゥール・フィジャック | 2014 | フランス | ボルドー | 赤 | 7430 | 0 |
| シャトー・ディッサン | 2013 | フランス | ボルドー | 赤 | 5918 | 0 |
| ドメーヌ・ド・ベレーヌ・ヴォルネイ・レ・グラン・ポワゾ | 2016 | フランス | ブルゴーニュ | 赤 | 9590 | 0 |
| バルコ・ヴィエホ・カベルネ・ソーヴィニヨン | 2017 | チリ | コルチャグア・ヴァレー | 赤 | 532 | 4 |
| ワイ・バイ・ヨシキ・カベルネ・ソーヴィニヨン・カリフォルニア | 2016 | アメリカ | カリフォルニア | 赤 | 5940 | 4.5 |
| コレッツィオーネ・チンクアンタ・+2・NV・サン・マルツァーノ | 2016 | イタリア | プーリア | 赤 | 2646 | 4.5 |
| ナパ・ハイランズ・カベルネ・ソーヴィニヨン・ナパ・ヴァレー | 2015 | アメリカ | カリフォルニア | 赤 | 4838 | 3.5 |
| シックス・エイト・ナインナパ・ヴァレー・レッド | 2016 | アメリカ | カリフォルニア | 赤 | 2350 | 5 |
| テッレ・デル・バローロ・バローロ | 2012 | イタリア | ピエモンテ | 赤 | 3650 | 2.5 |
| バスタルド | 2008 | スペイン | モンテレイ | 赤 | 10800 | 0 |
| フランシスカン・ナパヴァレー・カベルネソーヴィニヨン | 2015 | アメリカ | カリフォルニア | 赤 | 2862 | 4.5 |
| ドメーヌ・ヴァンサン・ルグー・ブルゴーニュ・オート・コート・ド・ニュイ・ルージュ レ・ボー・モン・リュソ | 2014 | フランス | ブルゴーニュ | 赤 | 4838 | 4 |
| メルキュレ・プルミエ・クリュ・クロ・デ ミグラン | 2016 | フランス | ブルゴーニュ | 赤 | 3866 | 4 |
| ロベール・シュヴィヨン ニュイ・サン・ジョルジュ・1er・レ・プリュリエ | 2016 | フランス | ブルゴーニュ | 赤 | 12744 | 0 |
| タトール・プリミティーヴォ・サレント | 2017 | イタリア | プーリア | 赤 | 2214 | 4.5 |
| ロッソ・トスカーナ・NV・テヌーテ・ロセッティ | 2017 | イタリア | トスカーナ | 赤 | 1144 | 4.5 |
| シャトー・モンペラ・ルージュ | 2015 | フランス | ボルドー | 赤 | 1980 | 5 |
| シャルム・シャンベルタン | 2016 | フランス | ブルゴーニュ | 赤 | 53460 | 0 |
| ビオンディ・サンティ ブルネッロ・ディ・モンタルチーノ・アンナータ | 2007 | イタリア | トスカーナ | 赤 | 18252 | 5 |
| イ・ムリ・ネグロアマーロ | 2017 | イタリア | プーリア | 赤 | 1328 | 4.5 |
| スターク・コンデ・スリー・パインズ・カベルネ・ソーヴィニヨン | 2015 | 南アフリカ | ヨンカースフッ ク・ヴァ レー | 赤 | 4395 | 5 |
| コスタセラ・アマローネ・デッラ・ヴァルポリチェッラ・クラシコ | 2012 | イタリア | ヴェネト | 赤 | 5994 | 4 |
| シャトー・ラフィット | 2015 | フランス | ボルドー | 赤 | 3542 | 3.5 |
| シャトー・ラグランジュ | 2014 | フランス | ボルドー | 赤 | 4700 | 0 |
40個で力尽きました、、
でも!素晴らしい!素晴らしすぎるよ楽天ランキング!!
年代、産地、値段がすばらしくバラついていて、まさに実験にうってつけです。
スコアさえあれば、こちらを学習データにしたかったぐらいです。
ではこれを先程のプログラムに組み込みます。
ちなみにラベルを1〜5の5段階で渡しているので、結果も5段階で評価されます。
最初の1回目は5のものを全て選び、再度それを評価、点数の最も高いものをリスト化、、、
を最後の1つになるまで繰り返して選出します。
ラベルを100点満点形式で出せば一発で選出できたかもしれませんが、まあ仕方ないです。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
import pandas as pd
# 学習用データ読み込みます
wine = pd.read_csv("ワインリスト.csv", sep=",", encoding="utf-8")
# データをラベルとデータに分離
label = wine["point"]
data = wine.drop("point", axis=1)
# 文字列は学習できないっぽいので数値に
data["name"], _ = pd.Series(data["name"]).factorize()
data["country"], _ = pd.Series(data["country"]).factorize()
data["area"], _ = pd.Series(data["area"]).factorize()
data["color"], _ = pd.Series(data["color"]).factorize()
# 今回は学習とテストには分割せず、全てを学習にまわします
# x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# おもちにモグモグさせる
model = RandomForestClassifier()
model.fit(data, label)
# 選抜用のデータを読み込んで文字列を数値に
senbatu = pd.read_csv("楽天ランキング.csv", sep=",", encoding="utf-8")
senbatu["name"], _ = pd.Series(senbatu["name"]).factorize()
senbatu["country"], _ = pd.Series(senbatu["country"]).factorize()
senbatu["area"], _ = pd.Series(senbatu["area"]).factorize()
senbatu["color"], _ = pd.Series(senbatu["color"]).factorize()
# 評価してもらう
pred = model.predict(senbatu)
print(pred)
このような結果が出ました。
[1 1 1 1 1 1 2 2 2 2 3 3 2 3 4 4 4 5 2 3 5 2 5 3 2 4 2 2 2 2 2 2 2 5 4 2 4 4 2 2]
これは表の上からAIが5段階で出した点数です。なので40個数字が並んでます。
実は参考にした書籍には1つを選出するようなものがなく、色々悩んで、関数探したり、dumpしたりして、上記に気付きました。
これをExcelに貼り付けてスコア5を抜き出してみます。
| name | year | country | area | color | price | star |
|---|---|---|---|---|---|---|
| シャトー・ディッサン | 2013 | フランス | ボルドー | 赤 | 5918 | 0 |
| ワイ・バイ・ヨシキ・カベルネ・ソーヴィニヨン・カリフォルニア | 2016 | アメリカ | カリフォルニア | 赤 | 5940 | 4.5 |
| ナパ・ハイランズ・カベルネ・ソーヴィニヨン・ナパ・ヴァレー | 2015 | アメリカ | カリフォルニア | 赤 | 4838 | 3.5 |
| シャルム・シャンベルタン | 2016 | フランス | ブルゴーニュ | 赤 | 53460 | 0 |
意外にも4つまで絞られました。
平均的に価格が高めですね。1個ずば抜けてるし、、
たぶんこれは学習データのスコア5の値段が全部高額だったからでしょう。
それでも1万超えがいくつかあった中でこのラインは、なかなか良心的です。
オーパス・ワンはおもちの好みではなかったようです。
ではこの4つをさらに振るいにかけて最後の1つを決定させましょう。
栄えある第一位は、、!!
ワイ・バイ・ヨシキ・カベルネ・ソーヴィニヨン・カリフォルニア
2016 アメリカ カリフォルニア
ヨシキ、アメリカ、カリフォルニアでピンときた人もいるかもしれません。
そうです。これ、X-JAPANのYOSHIKIコラボワインです。
(楽天ランキング28位)

リスト作ってるときに、「なんだこれ、こんな色物入れるのどうしようかな。まあ選ばれないだろうし、いいか」と思って入れたんですが、まさかこれになるとは、、
せっかくなので購入してみようと思いましたが、

なんと、、確かに知り合いにもファンがいるし、最早出せば売れるんだろうなぁ、、
ちなみに4つのスコアは上から順に「1 2 1 1」でした。。
それで良いのか、、おもちよ、、
とまあ良い具合にオチがついたところで今回はこれで終わりにしたいと思います。
とはいえ機械学習にはまだニューラルネットワークを使った深層学習、すなわちディープラーニングをはじめ、色々なアルゴリズムが存在していますし、勉強しないといけないことは山程ありますから先は長いですね。
当初、膨大な航空券売上情報を使って何かできないかなーと考えたりもしたのですが、
ラベルに相当する「何を持って正解とするか」というものが思いつきませんでした。
AIは魔法ではないので、技術だけじゃなく、学習データそのものもよく考えないと思うような結果は出ないことを、よく心に刻んておきましょう!
長々とお読みいただき、ありがとうございました![]()