米国国勢調査のデータを使って、データの並べ替えをしてみました。
nst-est2019-01
環境
Python version:3.9.7
OS: windows 10.0
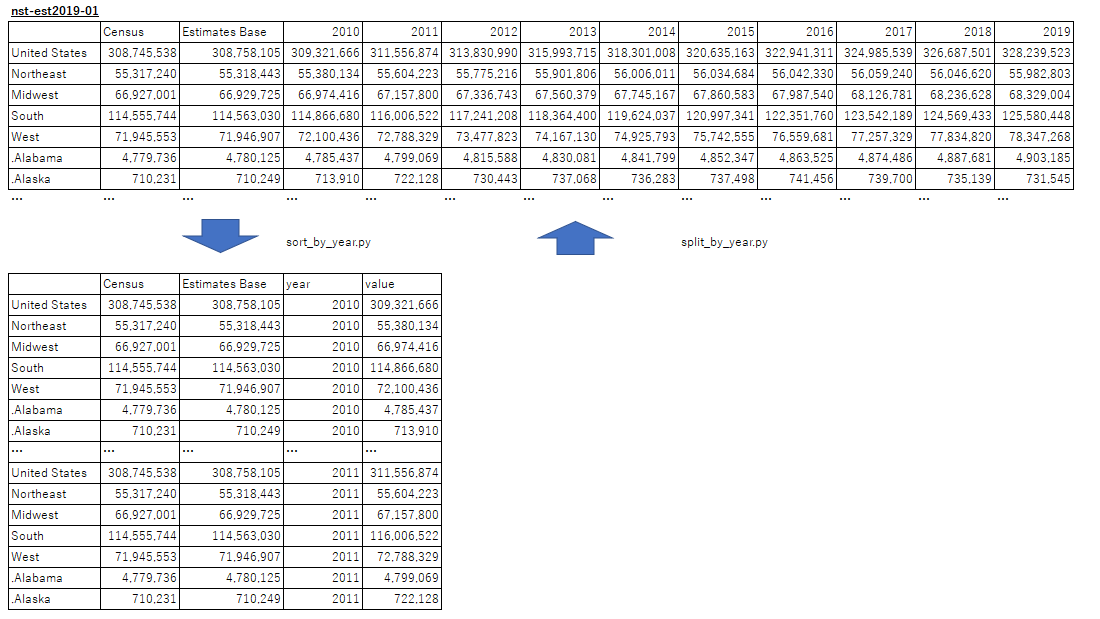
イメージ
下記用に年ごとに並べられたデータを年ごとに下に追加していくようにデータを並び替えをします。また、並び替えをしたデータをもとの形に戻します。
プログラム
まず、上記csvファイルをダウンロードして、実行させるプログラムを同じディレクトリに配置します。
行っていることは、単純で並べたいデータフレームを各年毎に作って、それをconcatでどんどん下へ結合しているだけの操作になります。
データフレームの年毎とそれ以外の情報は、columnのheaderの部分で分けることができるので、listを作って分割し、yearの情報をforで回していくようにしています。
最後に、columnのyearの位置を並べ替えています。
sort_by_year.py
import csv
import pandas as pd
import numpy as np
debug = False
# get csv data
df = pd.read_csv('nst-est2019-01.csv')
# print index and columns for debug
if (debug):
print(df.index.to_numpy()) # print index
print(df.columns.to_numpy()) # print column
print(len(df.columns)) # print column length
# change from numpy.array to list.
df_column_s = df.columns.to_numpy()
df_column_list = df_column_s.tolist()
# split to label and year.
label_list = df_column_list[:3]
year_list = df_column_list[3:]
for flag, year_num in enumerate(yaer_list,0):
if flag == 0:
df_base = df[[label_list[0],label_list[1],label_list[2],year_num]]
df_base = df_base.rename(columns={year_num: 'value'})
df_base['year'] = year_num
else:
df_new = df[[label_list[0],label_list[1],label_list[2],year_num]]
df_new = df_new.rename(columns={year_num: 'value'})
df_new['year'] = year_num
df_base = pd.concat([df_base, df_new], axis=0, ignore_index=True)
# move year order.
value_move_last_column = df_base.pop('year')
df_base.insert(3,'year',value_move_last_column)
df_base.to_csv("nst-est2019-02.csv", index = False)
次に、sortした情報を元に戻します。最初にyear以外の情報をラベルにして、そのラベルと同じ情報がある行へyearの情報を追加してしています。
追加した後は、ラベルの隣にyearの情報が出てくるので、最後の列に移動しています。最後に、不要になったlabelの情報を消して、元に戻しています。
split_by_year.py
import csv
import pandas as pd
import numpy as np
debug = False
flag = 0
# get csv data
df = pd.read_csv('nst-est2019-02.csv')
# make the label
# df.insert(loc, column, value, allow_duplicates=False)[source])
df.insert(0, 'label', df['Unnamed: 0']+ df['Census']+df['Estimates Base'])
# print index and columns for debug
if (debug):
print(df) # data frame
print(df.index.to_numpy()) # print index
print(df.columns.to_numpy()) # print column
print(f['year'].nunique()) # Get the number of elements information for year series
# Get the type of elements information for year series
year_unique_list = df["year"].unique()
for col_year_val in year_unique_list:
# make data frame par year.
if flag == 0:
# Get the value for per year
df_base = df[df['year'] == col_year_val]
# Rename the value for per year (from vlaue to per year)
df_base = df_base.rename(columns={'value': col_year_val})
# Remove value for per year not to use it.
df_base = df_base.drop('year',axis='columns')
flag = flag + 1
else:
# make new df.
# 1.Get the next year value from main df.
df_append = df[df['year'] == col_year_val]
# 2.Extract label and next year label.
df_append = df_append[["label","value"]]
# 3.Rename the value to next year .
df_append = df_append.rename(columns={'value': col_year_val})
# 4.merge df_base and df_append at label.
df_base =pd.merge(df_append, df_base, how="outer", on = "label")
# 5.move to next year last column.
value_move_last_column = df_base.pop(col_year_val)
# df.insert(last_column_number, column_name, column_value,)
df_base.insert(len(df_base.columns),col_year_val,value_move_last_column)
df_base = df_base.drop('label',axis='columns')
df_base.to_csv("nst-est2019-01_a.csv", index = False)