AWSサービスのみを利用してサーバーレスなRAGアプリケーションを作成しました。
アーキテクチャの説明
アーキテクチャ図で表現すると、以下のような図になります。
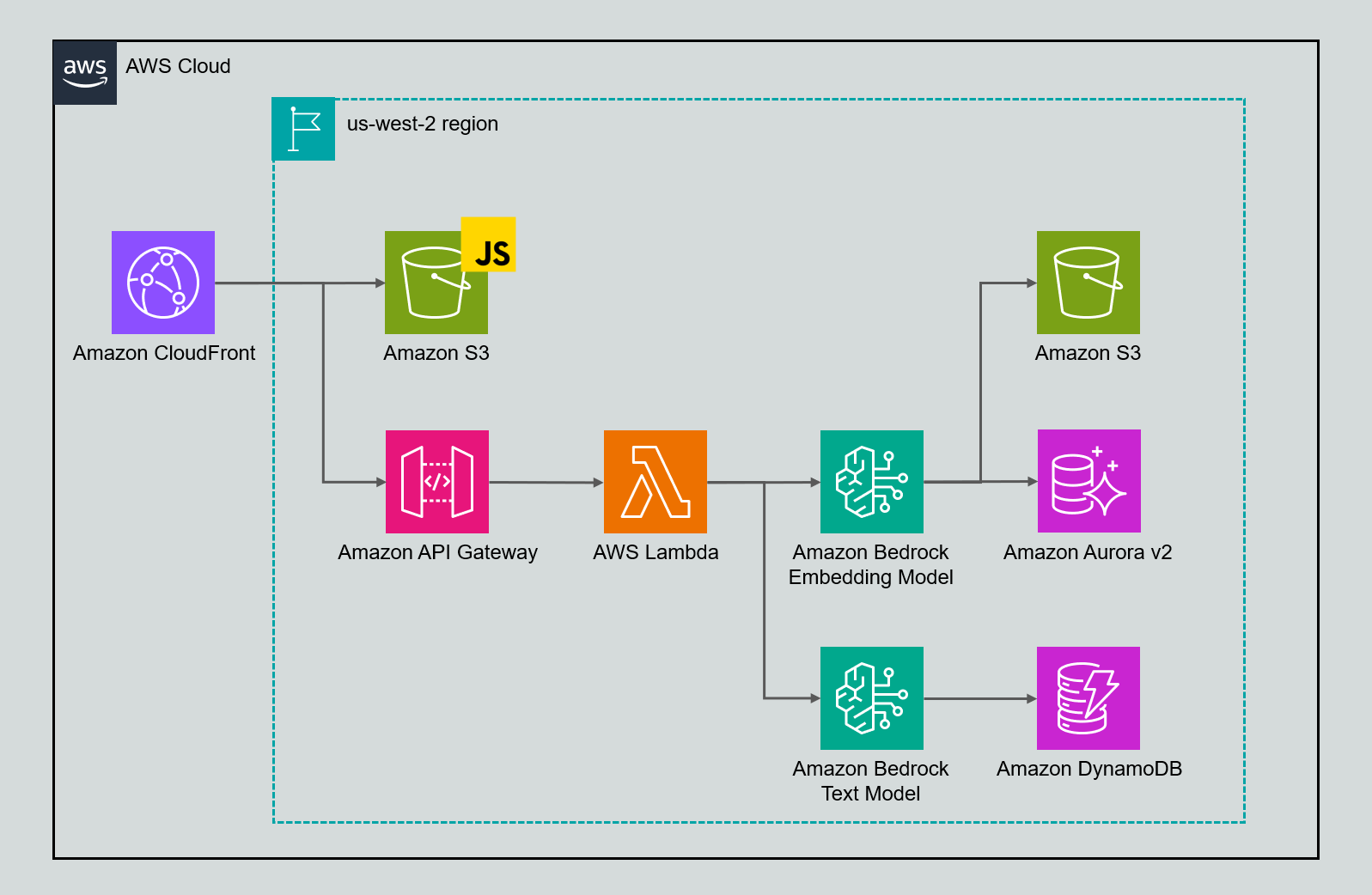
インフラの説明
インフラとしては、以下の様に実装しています。
- CloudFront と S3 を利用して、HTML、CSS、JavaScriptなどの静的ファイルをホスト(最近では、Amplify Hostingを利用することも多くなってきましたが、どちらでも構いません)
- Bedrock の Knowledge Base と Amazon Aurora for PostgreSQL Serverless v2(以後、Aurora)を利用して、RAGを構築
- DynamoDB を利用して、会話履歴を保存するためのデータベースを構築
- API Gateway と Lambda を利用して、チャットと会話履歴関連の処理を実装。Lambda は Bedrock と DynamoDB の API を呼び起こす
フロントエンドの説明
フロントエンドとしては、以下のように実装しています。
- HTML、CSS、Javascript を利用して、チャットアプリケーションの画面を作成。
- Javascript に API Gateway の呼び出し用URLを記載し、チャットの送信や、会話履歴の保存、削除などを処理。
バックエンドの説明
バックエンドのクエリ処理の流れとしては、以下のように実装しています。
API Gateway から Lambda 関数の実行
- API Gateway 経由で lambda が呼び出される
- 大きく分けるとクエリ処理 / 履歴取得 / 履歴削除の処理がある
- HTTP メソッドが
POSTで、パスが/queryの場合、handle_query()関数が実行される
handle_query() 関数の処理
- リクエストから クエリテキスト と 会話ID を取得
- 会話IDがない場合は、新しい UUID を生成
query_with_langchain() 関数の処理
1. Knowledge Base検索
-
AmazonKnowledgeBasesRetrieverを使用して、クエリに関連する文書を検索 - 最大 4件の関連文書を取得
2. コンテキストの作成
- 取得した関連文書から、コンテキスト文字列を作成
- 文書の内容を結合し、プロンプトの背景情報として使用
3. 会話履歴の管理
-
DynamoDB から会話履歴を読み込む
-
DynamoDBChatMessageHistoryを使用し、会話IDに紐づく過去のメッセージを取得
-
4. 会話チェーンの作成
-
ConversationBufferMemoryを初期化- 会話履歴をメモリに読み込み
-
ConversationChainを作成- ChatBedrockConverse (LLM) を使用
- メモリとチェーンを設定
5. プロンプトの生成
- 関連文書のコンテキストとユーザーの質問を組み合わせる
6. LLM に問い合わせ
-
chain.invoke()メソッドで応答を生成 - コンテキストと質問に基づいて回答を作成
7. 応答の準備
- 生成された回答テキストを取得
-
参照元のソース(文書)情報を作成
- ファイル名や URI を抽出
8. レスポンスの返却
200 (OK)ステータスコードで応答- JSON 形式で以下を返す
- 回答テキスト
- 参照元ソース
- 会話ID
LangChainを使う理由
LangChainとは
LangChainは、大規模言語モデル(LLM)を使用したアプリケーション開発を簡素化するPythonライブラリです。異なるLLMプロバイダ、データソース、メモリ管理などを統一的なインターフェースで提供し、AIベースのアプリケーションの構築を効率的にサポートします。
LangChainを使う理由・メリット
LangChainを使う理由・メリットとしては、他のライブラリでもそうであるように、生産性を向上させることにあります。複雑な機能を抽象化し、再利用可能なコンポーネントを提供することで、AIアプリケーションの開発をサポートします。
今回のコードでは、以下のようなメリットが挙げられます。
動的なコンテキスト統合
下記コードにより、これらが可能です。
- Knowledge Baseから動的に関連文書を取得
- クエリごとに最適な背景情報を自動的に選択
- 関連文書を簡単に統合
retrieved_docs = retriever.get_relevant_documents(query_text)
context = "\n\n".join([doc.page_content for doc in retrieved_docs])
会話履歴の永続的な管理
下記コードにより、これらが可能です。
- DynamoDBと統合し、会話履歴を簡単に保存・復元
- 複数セッション間での文脈の継続
- メモリ管理の複雑さを抽象化
history = create_dynamodb_history(conversation_id)
memory = ConversationBufferMemory(
chat_memory=history,
return_messages=True
)
柔軟な会話チェーン構築
下記コードにより、これらが可能です。
- LLMとメモリを簡単に組み合わせ
- 追加のカスタマイズや拡張が容易
chain = ConversationChain(
llm=chat,
memory=memory,
verbose=True
)
前提・注意
- AWSのリージョンは
us-west-2(オレゴン)を利用します - Lambdaパッケージの作成は
CloudShellを利用します - Lambdaランタイムは
Python 3.12を利用します - AWSの各サービスや、LangChaingなどのモジュールの内容は変わっている可能性があるため、最新のドキュメントの内容を正とします
ソースコード
今回作成したアプリケーションのファイルは以下Githubからダウンロード可能です。
構築手順(インフラ)
Aurora Serverless v2(Compatible with PostgreSQL)関連リソースの作成
infrastructure/cloudformation/01-aurora-serverless-v2.yamlを利用して、CloudFormationで、以下リソースを作成していきます。
このCloudFormationは、少し変更をしていますが、以下リンクのブログを参考にしています。
【コピペでRAG構築】Knowledge Base for Amazon Bedrock(Aurora Serverless v2 for PostgreSQL)
作成リソース:
- VPC
- Subnet
- ルートテーブル、ルート
- Auroraのシークレット(Secret Manager)
- DBサブネットグループ
- Auroraクラスター
- Auroraインスタンス
これらのリソースを作成するにあたってポイントは以下です。
- Aurora v2 でアイドル時の ACU を 0 にする
- マスターユーザーのパスワードを自動作成し、Secret Manager に保存する
-
Data APIを有効化しているため、Security Groupが不要で、API 経由による直接 SQL を実行可能(Knowledge Base for Amazon Bedrock で Auroraを利用するためには、Data API が必要)
Aurora のセットアップ
Auroraのクエリエディタを利用し、マスターユーザーでSQLを実行していきます。
クエリエディタは、ユーザー名・パスワードを利用し、コンソール上から直接DBにSQLを実行出来る機能です。
pgvector 拡張機能のインストール
pgvector は、PostgreSQL にベクトル検索機能を追加する拡張機能です。
以下のコマンドを実行し、ベクトルを利用できるように DB に拡張機能をインストールします。
CREATE EXTENSION IF NOT EXISTS vector;
pgvector 拡張機能のバージョン確認
pgvector が正常にインストールされたことを確認するため、以下のコマンドを実行します。
SELECT extversion FROM pg_extension WHERE extname='vector';
スキーマの作成
データを整理し、適切に管理できるように新しいスキーマを作成します。
CREATE SCHEMA bedrock_integration;
新しいロールの作成
データベースへのアクセスを制御するため、新しいロール bedrock_user を作成します。
この時のパスワードは、CloudFormationで作成したシークレットです。
CREATE ROLE bedrock_user WITH PASSWORD 'Knosn##!civ134&5%nsips!D' LOGIN;
権限設定
作成した bedrock_user に対して、スキーマおよびテーブルへのアクセス権限を付与します。
GRANT ALL ON SCHEMA bedrock_integration TO bedrock_user;
GRANT ALL ON TABLE bedrock_integration.bedrock_kb TO bedrock_user;
テーブル作成
ベクトル検索を活用するために、以下のテーブル bedrock_kb を作成します。
CREATE TABLE bedrock_integration.bedrock_kb (
id uuid PRIMARY KEY,
embedding vector(1024),
chunks text,
metadata json
);
インデックスの作成
ベクトル検索の高速化のため、HNSW(Hierarchical Navigable Small World)インデックスを作成します。
CREATE INDEX ON bedrock_integration.bedrock_kb USING hnsw (embedding vector_cosine_ops);
Bedrock関連リソースの作成
infrastructure/cloudformation/02-kb-bedrock.yamlを利用して、CloudFormationで、以下リソースを作成していきます。
CloudFormationのパラメーターで、以下を指定するようにしてください。
- 01で構築したAuroraClusterのARN
- 01で構築したシークレットのARN
このCloudFormationも、少し変更をしていますが、以下リンクのブログを参考にしています。
【コピペでRAG構築】Knowledge Base for Amazon Bedrock(Aurora Serverless v2 for PostgreSQL)
作成リソース:
- S3ゲートウェイエンドポイント
- Knowledge Baseのデータソース用S3
- Knowledge BaseのIAMロール
このIAMロールは、Bedrockに対し、BedrockのKnowledge BaseからAurora、S3、Secrets Manager、Foundation Modelを利用できるようにするためのものです。
また、今回は埋め込みモデルとして、Amazon Titan Text Embedding V2を利用するため、ポリシーにも記載しています。
なんでもよいですが、今回はKnowledge Baseに同期するデータとして、確定申告書作成ガイド.pdfをS3にアップロードします。
Knowledge Base for Bedrockの作成
Knowledge Base は CloudFormation では作成できないため、CLI で作成・設定していきます。
Bedrock Modelの確認
Bedrock で利用可能な Foundation Model を確認します。
aws bedrock list-foundation-models --region us-west-2 | grep titan-embed-text
aws bedrock list-foundation-models --region us-west-2 | grep claude-3-5-sonnet
Knowledge Base for Amazon Bedrockの構築
新しいKnowledge Baseを作成し、ベクトル検索を使用するように設定します。
-
embeddingModelArnに調べた 埋め込み用のFoundation Modelを記載する -
resourceArnに作成した Aurora Cluster の ARN を記載する -
credentialsSecretArnに作成した Secret の ARNを 記載する -
--role-arnに作成した IAM ロールのARN を記載する
aws bedrock-agent create-knowledge-base \
--name my-knowledge-base \
--knowledge-base-configuration '{
"type": "VECTOR",
"vectorKnowledgeBaseConfiguration": {
"embeddingModelArn": "arn:aws:bedrock:us-west-2::foundation-model/amazon.titan-embed-text-v2:0"
}
}' \
--storage-configuration '{
"type": "RDS",
"rdsConfiguration": {
"resourceArn": "arn:aws:rds:us-west-2:622632352793:cluster:kb-bedrock-aurora-postgresql-serverl-auroracluster-o60leeieb7ug",
"credentialsSecretArn": "arn:aws:secretsmanager:us-west-2:622632352793:secret:database-user-for-bedrock-secret-zimtNJ",
"databaseName": "rag",
"tableName": "bedrock_integration.bedrock_kb",
"fieldMapping": {
"primaryKeyField": "id",
"vectorField": "embedding",
"textField": "chunks",
"metadataField": "metadata"
}
}
}' \
--role-arn "arn:aws:iam::622632352793:role/AmazonBedrockExecutionRoleForKnowledgeBase_kb-bedrock-rag-chat" \
--region us-west-2
データソースの追加
作成したKnowledge BaseにS3バケットをデータソースとして追加します。
-
knowledge-base-idに作成した nowledge base の ID を記載する -
bucketArnに作成した S3 Bucet の ARN を記載する
aws bedrock-agent create-data-source \
--knowledge-base-id FCMT0YSU3F \
--name my-knowledge-base-data-source \
--data-source-configuration '{
"type": "S3",
"s3Configuration": {
"bucketArn": "arn:aws:s3:::kb-bedrock-rag-chat-eed289c0-f670-11ef-aefd-026c5ae1d90b"
}
}' \
--region us-west-2
データソース ID を控える。
データの同期
S3バケットのデータをKnowledge Baseに取り込むため、データの同期を開始します。
-
knowledge-base-idに作成した nowledge base の ID を記載する -
data-source-idに作成した データソース ID を記載する
aws bedrock-agent start-ingestion-job \
--knowledge-base-id FCMT0YSU3F \
--data-source-id 2WIVB4SDX5 \
--region us-west-2
インジェスチョン ID を控え、同期のステータスを確認します。
-
knowledge-base-idに作成した nowledge base の ID を記載する -
data-source-idに作成した データソース ID を記載する -
ingestion-job-idに控えたインジェスチョン ID を記載する
aws bedrock-agent get-ingestion-job \
--knowledge-base-id FCMT0YSU3F \
--data-source-id 2WIVB4SDX5 \
--ingestion-job-id G4RXLFFAOC \
--region us-west-2
動作確認
作成したKnowledge Baseを利用して、RAGによる回答生成を実行します。
-
knowledge-base-idに作成した nowledge base の ID を記載する -
modelArnに調べた テキスト用のFoundation Modelを記載する
aws bedrock-agent-runtime retrieve-and-generate \
--region us-west-2 \
--retrieve-and-generate-configuration '{
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "FCMT0YSU3F",
"modelArn": "arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-3-5-sonnet-20241022-v2:0"
}
}' \
--input '{
"text": "確定申告のやり方を簡単に教えて?"
}'
CloudFront, S3
infrastructure/cloudformation/03-cloudfront-s3.yamlを利用して、CloudFormationで、以下リソースを作成していきます。
このCloudFormationも、少し変更をしていますが、以下リンクのブログを参考にしています。
【コピペでRAG構築】Knowledge Base for Amazon Bedrock(Aurora Serverless v2 for PostgreSQL)
作成リソース:
- フロントエンドを配信するCloudFrontディストリビューション
- CloudFrontのオリジンであるS3バケット
コメントアウトしている部分は、Lambda@edgeの実装に関するものです。
Lambda@edgeが必要な場合は、us-west-1にLambdaを作成し、上記コメントアウトを外し、パラメーターにLambdaのARNを記載してください。
後ほど、このS3バケットにフロントエンドのファイルを格納します。
DynamoDBの作成
infrastructure/cloudformation/04-dynamodb.yamlを利用して、CloudFormationで、以下リソースを作成していきます。
作成リソース:
- セッションIDとして会話IDを保存するDynamoDBテーブル
リソースを作成するにあたってポイントは以下です。
- 支払いタイプをオンデマンドにすることで、DynamoDBへの読み書き時のみコストが発生する
- DynamoDBテーブルの主キー(Primary Key)を
SessionIdとしているが、これはバックエンドで構築する LangChain のDynamoDBChatMessageHistoryがデフォルトで主キーをSessionIdとするため
Lambdaコード格納用のS3の作成
infrastructure/cloudformation/05-lambda-s3.yamlを利用して、CloudFormationで、以下リソースを作成していきます。
作成リソース:
- Lambdaコードを保存するS3バケット
Lambdaを作成するCloudFormationでは、LambdaコードをS3からアップロードする仕組みになっているため、その準備として作成します。
以下のテストのためのコードをfunction.pyとして保存し、function.zipという名前でZip化した後、作成したS3バケットのルートディレクトリにアップロードしてください。
import json
def lambda_handler(event, context):
return {
"statusCode": 200,
"body": json.dumps("Hello, World!")
}
※次のCloudFormationでは、Lambdaを作成しますが、Lambdaハンドラーは**「ファイル名.ハンドラー関数」**となる必要があります。
※CloudFormationテンプレートには、function.lambda_handlerと記載しているため、ファイル名は必ずfunction.pyとしてください。
Lambda, API Gatewayの作成
infrastructure/cloudformation/06-lambda-api.yamlを利用して、CloudFormationで、以下リソースを作成していきます。
CloudFormationのパラメーターで、以下を指定するようにしてください。
- Knowledge BaseのID
- DynamoDBのテーブル名
- Lambdaのコードを保存したS3バケット名
作成リソース:
- Lambda実行ロール
- Lambda関数
- Lambdaパーミッション
- API Gateway実行ロール
- CloudWatchロググループ
- API Gateway関連リソース
- API Gateway本体
- APIリソース(エンドポイント)
- /query エンドポイント
- /history エンドポイント
- APIメソッド(リクエスト処理)
- QueryMethod (POST /query)
- GetHistoryMethod (GET /history)
- DeleteHistoryMethod (DELETE /history)
- QueryOptions (OPTIONS /query)
- HistoryOptions (OPTIONS /history)
- APIデプロイメント
- APIステージ
これらのリソースの作成が難しい且つ、今後のアプリケーションのエラーにつながってくるため、いくつか解説します。
- LambdaのコードはS3バケットから取得します。その際はルートディレクトリのfunction.zipを取得し、Lambdaにデプロイされる
- APIリソース(エンドポイント)では、
- 各APIメソッドでは、Lambdaプロキシ統合を利用しLambda関数と統合されている
- プロキシ統合を利用したAPIメソッドの場合、統合レスポンスを返さないため、バックエンドが必要なヘッダーを返す必要がある[1]
- Optionsメソッドでは、モック統合を利用し、プリフライトリクエストを処理するために、必要なヘッダーを返す
- APIデプロイメントでは、APIをデプロイし、エンドポイントを有効化する
- APIステージでは、
prodステージを作成し、ログを有効化する
構築手順(バックエンド)
以下を実施し、Lambdaに実際のコードをデプロイしていきます。
CloudShellを開く。
以下コマンドを実行し、開発環境に必要なモジュールをインストールします。
mkdir -p lambda_package
cd lambda_package
pip install -U langchain-aws langchain-community -t . --python-version 3.12 --only-binary=:all:
function.pyの内容をコピーしてから、以下コマンドを実行します。
nano function
function.pyをペーストし、ファイルの変更をセーブします。(ペースト後にCtrl + X、Shift + Y、Enterを順番に押します。)
以下コマンドを実行し、Lambdaパッケージを作成します。
zip -r function.zip .
作成したLambdaパッケージをS3にコピーします。
aws s3 cp function.zip s3://kb-bedrock-rag-chat-code-3988efb0-0137-11f0-b220-06b5622a0cbf/function.zip
Lambdaをデプロイし直します。
aws lambda update-function-code \
--function-name kb-bedrock-rag-chat-function \
--s3-bucket kb-bedrock-rag-chat-code-3988efb0-0137-11f0-b220-06b5622a0cbf \
--s3-key function.zip
今回は、CI/CDは用意していません。
Lambdaコードの説明
Lambdaコードについて大事な部分を説明します。
1. 主要ライブラリのインポート
from langchain_aws import AmazonKnowledgeBasesRetriever
from langchain_aws import ChatBedrockConverse
from langchain_core.messages import HumanMessage, AIMessage
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import DynamoDBChatMessageHistory
import os
import json
import uuid
import decimal
-
langchain_awsを使用して Bedrock のリトリーバー (AmazonKnowledgeBasesRetriever) とチャットモデル (ChatBedrockConverse) を設定 -
langchain.chains.ConversationChainを用いて会話の流れを管理 -
uuidでユニークな会話 ID を生成
2. 環境変数の取得
KB_ID = os.environ.get('KB_ID')
MODEL_ID = os.environ.get('MODEL_ID', 'anthropic.claude-3-5-sonnet-20241022-v2:0')
HISTORY_TABLE_NAME = os.environ.get('HISTORY_TABLE_NAME', 'ChatMessageHistory')
-
Knowledge Base ID (
KB_ID): Bedrock のリトリーバーのための知識ベース -
モデル ID (
MODEL_ID): デフォルトでClaude 3.5 Sonnetを使用 -
DynamoDB テーブル (
HISTORY_TABLE_NAME): 会話履歴の保存場所
3. JSON シリアライザ
def decimal_serializer(obj):
if isinstance(obj, decimal.Decimal):
return float(obj)
raise TypeError("Type not serializable")
- DynamoDB は
decimal.Decimal型を使用するため、JSON に変換する関数 を定義
4. Retriever と Chat モデルの設定
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id=KB_ID,
retrieval_config={
"vectorSearchConfiguration": {
"numberOfResults": 4
}
}
)
chat = ChatBedrockConverse(
model_id=MODEL_ID,
temperature=0.5,
max_tokens=1000
)
-
retriever:Bedrock の 知識ベース から関連ドキュメントを検索 -
chat:LLM を用いて会話を処理
5. DynamoDB の会話履歴管理
def create_dynamodb_history(conversation_id):
return DynamoDBChatMessageHistory(
table_name=HISTORY_TABLE_NAME,
session_id=conversation_id,
primary_key_name="SessionId"
)
- DynamoDB に保存する 会話履歴オブジェクト を作成
6. Lambda のエントリーポイント
def lambda_handler(event, context):
http_method = event.get('httpMethod', '')
path = event.get('path', '')
if http_method == 'POST' and path.endswith('/query'):
return handle_query(event)
elif http_method == 'GET' and path.endswith('/history'):
return handle_get_history(event)
elif http_method == 'DELETE' and path.endswith('/history'):
return handle_delete_history(event)
else:
return {
'statusCode': 400,
'headers': {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
},
'body': json.dumps({'error': '無効なリクエスト'})
}
- API Gateway のエンドポイントに応じて、クエリ処理 / 履歴取得 / 履歴削除 の関数を呼び出す
7. クエリの処理
def handle_query(event):
try:
body = json.loads(event.get('body', '{}'))
query = body.get('query', '')
conversation_id = body.get('conversationId', str(uuid.uuid4()))
if not query:
return create_response(400, {'error': 'クエリが必要です'})
result = query_with_langchain(conversation_id, query)
response_text = result.get('response', '')
sources = result.get('sources', [])
return create_response(200, {
'response': response_text,
'sources': sources,
'conversationId': conversation_id
})
except Exception as e:
return create_response(500, {'error': f'サーバー内部エラー: {str(e)}'})
- クエリを LangChain を使って処理し、レスポンスを作成
8. LangChain を使用したクエリ処理
def query_with_langchain(conversation_id, query_text):
history = create_dynamodb_history(conversation_id)
memory = ConversationBufferMemory(chat_memory=history, return_messages=True)
chain = ConversationChain(llm=chat, memory=memory, verbose=True)
retrieved_docs = retriever.get_relevant_documents(query_text)
sources = []
for doc in retrieved_docs:
file_name = doc.metadata.get('source_uri', 'Unknown')
sources.append({'title': file_name, 'url': doc.metadata.get('source_uri', '#' )})
prompt = f"""以下の情報を参考にして質問に回答してください:
{retrieved_docs}
質問: {query_text}
"""
result = chain.invoke(query_text)
return {
'response': result.get("response", ""),
'sources': sources
}
-
retrieverで 関連ドキュメントを取得 -
ConversationChainを利用して 会話履歴を維持しながら LLM で回答を生成
構築手順(フロントエンド)
Frontendフォルダのファイルを全てを03で作成したS3にアップロードします。
念のためCloudFrontのキャッシュを削除します。
CloudFtontのディストリビューションIDをコピーし、ブラウザに貼り付ける。
以下のような画面のアプリケーションが表示されます。
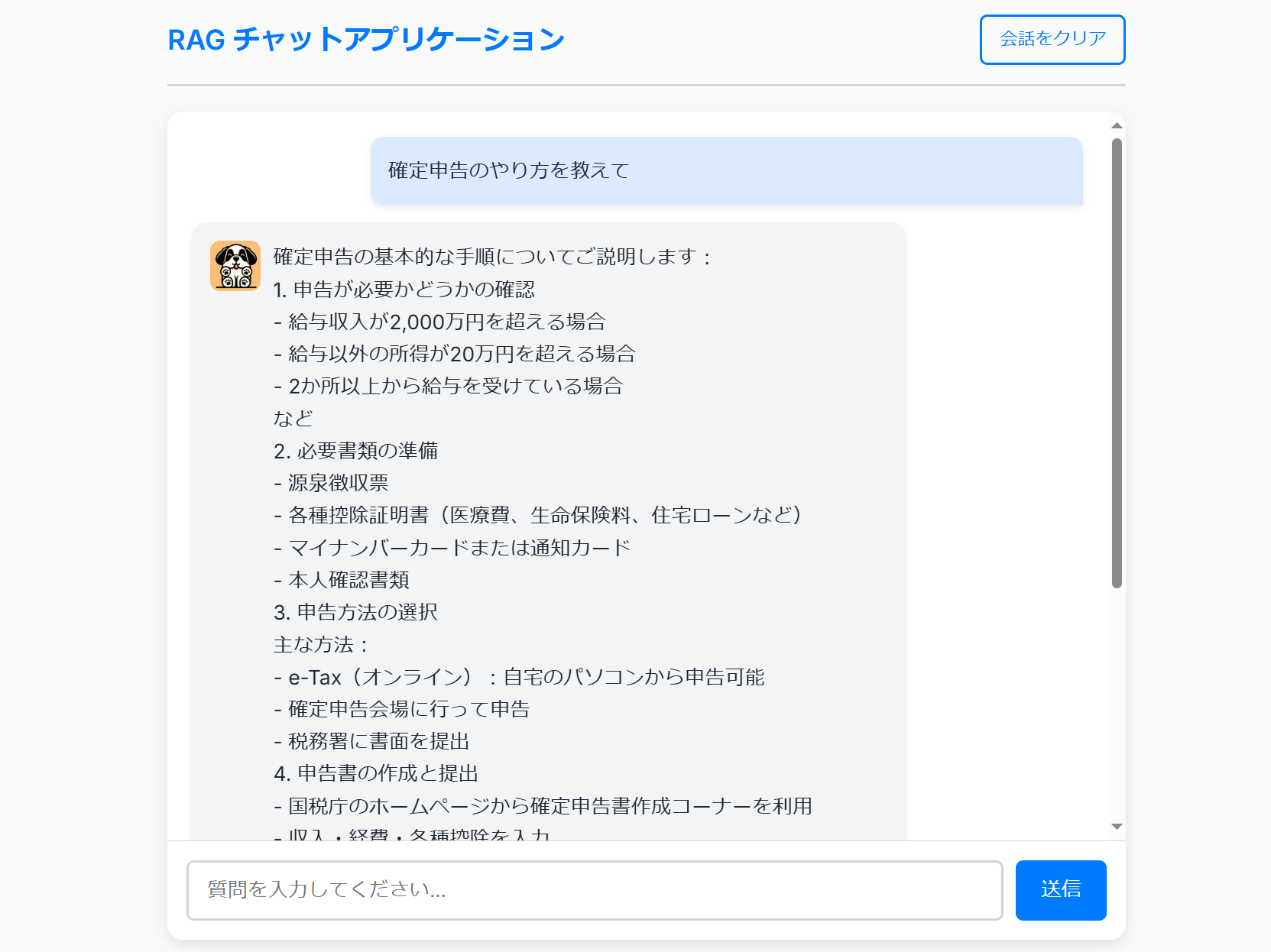
- 1回目のクエリでは、DB起動のためのエラーが表示されます。
- 2回目のクエリでは、回答が返ってきます。
- 3回目のクエリでは、2回目のクエリ・回答の内容をもとにした回答が返ってきます。
つまづいたところ(直すのに時間がかかったエラー)
Lambdaコードの作成時、大きく2点躓いた部分がありました。
モジュール未検出エラー (ImportModuleError)
以下エラーが出ていました。
[ERROR] Runtime.ImportModuleError: Unable to import module 'app.main': No module named 'pydantic_core._pydantic_core'
[事象]
Lambda実行時、pydantic_core._pydantic_core 、pydantic モジュールのインストールや依存関係に問題がある。
[解決策]
Lambdaの実行環境と開発環境(CloudShell)の内容を揃える必要があります。
LambdaはPython 3.12を利用していたが、CloudShellでは、Python 3.9が利用されていました。
そのため、以下の様にコマンドを実行することで解決しました。(--python-version 3.12 --only-binary=:all:)
pip install -U langchain-aws langchain-community -t . --python-version 3.12 --only-binary=:all:
DynamoDBキー不一致エラー (ValidationException)
以下エラーが出ていました。
[ERROR] 2025-03-21T15:44:37.979Z 736f5f1e-71bc-4f0d-97b1-a8d0edf69478 An error occurred (ValidationException) when calling the GetItem operation: The provided key element does not match the schema
[事象]
DynamoDBテーブルへのGetItem実行時、指定したキーがテーブルスキーマと一致していませんでした。
[解決策]
キーの指定方法は正しかったが、キーとして利用していた ConversationID が None だったため、アイテムを取得することが出来ていませんでした。
そのため、DynamoDBテーブルに値が入っているかを確認し、入っていない場合はそこを先に直す必要がありました。
感想
Aurora v2のスケーリング
大量のアクセスを行ったわけではないため、スケールインのみの確認となりましたが、Aurora v2は非常に高速にACUの調整を行ってくれるように感じました。
Lambdaの開発中は、すぐにデータベースが停止してしまうため、その都度データベースの再開を待つ必要がありました。
そのため、開発中や本番環境での利用においては、ACUの調整が必要だと感じました。
ただし、コストは非常に安価に抑えることができました。
RAGの仕組みと限界
構築前は、RAGの仕組みとして「データソースへのクエリが不要な質問についてはクエリを行わず、必要な場合のみクエリを実行する」、また「データソースにない情報についても一般的なLLMとして応答する」と考えていました。
しかし、実際にはそのような動作ではなく、基本的にデータソースにある情報のみを基に回答する仕組みであると感じました。
そのため、データソースに関する質問以外では、現在のClaudeやChatGPTなどを利用したほうが、対応できる内容が多く、ある程度のファイルの読み込みやインターネットへのクエリも可能なため、適していると感じました。
もし、上記のような仕組みを実現する場合は、Bedrockのマルチエージェントコラボレーションなどを利用し、以下のようにスーパーバイザーエージェントとワーカーエージェントの役割を分けて運用する必要があると考えました。
- スーパーバイザー:ワーカーを利用するか判断するエージェント
- ワーカー①:データソースにクエリを実行するKnowledge Baseエージェント
- ワーカー②:インターネットにクエリを実行するKnowledge Baseエージェント
API GatewayのCORS関連の仕組み
CORSエラーが解消されず、502や500エラーが返り続けていました。
ブラウザの開発者ツールでも、CORSに対応したヘッダーが返っていないように見えていました。
Lambda側ではヘッダーを返すように設定しており、Lambdaのメトリクス上では実行されたデータポイントが記録されていませんでした。
また、API Gatewayの統合レスポンスにもヘッダーを返す設定を行いましたが、解決には至りませんでした。(Lambdaプロキシの場合、Lambda側でヘッダーを返す必要があります)
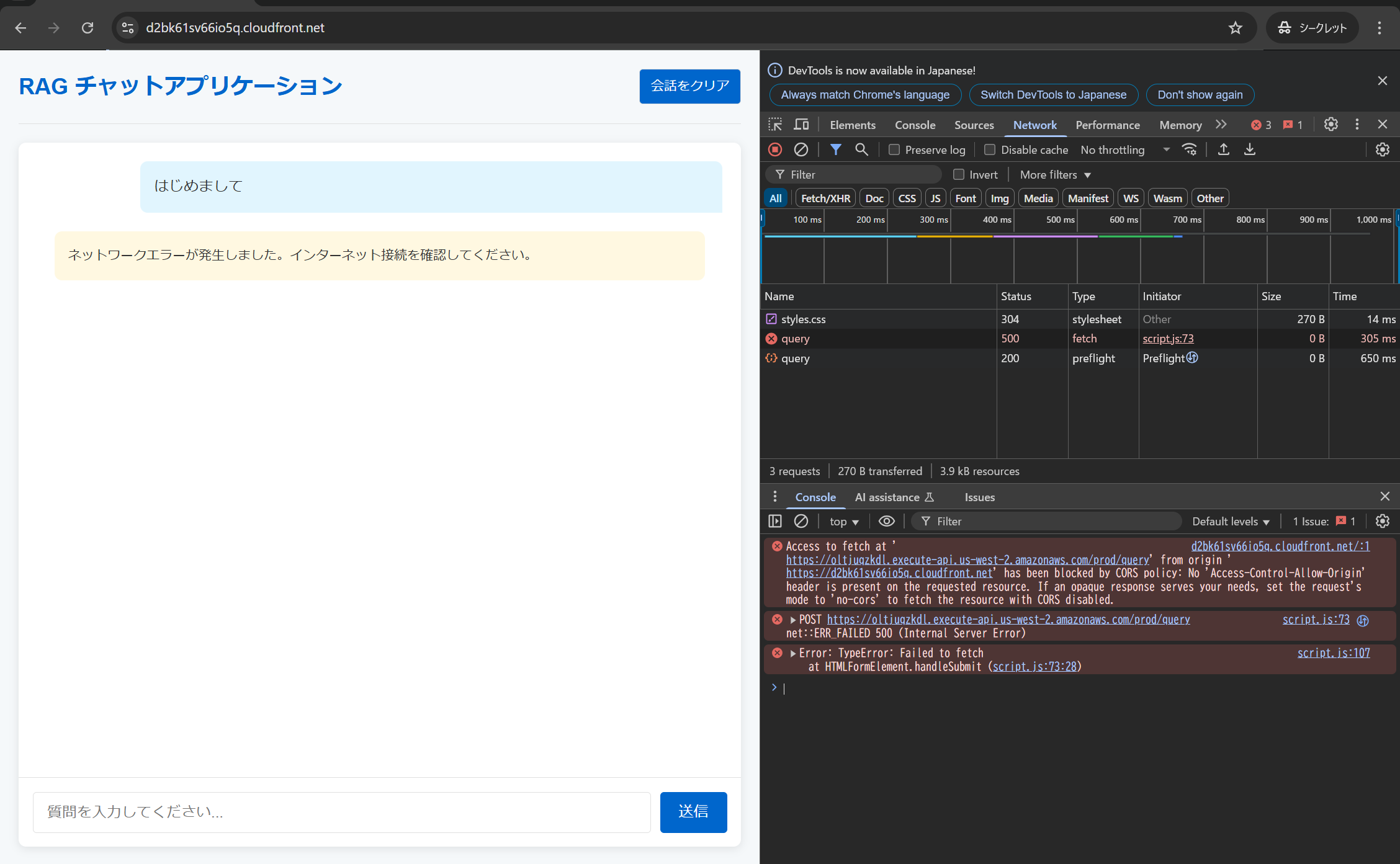
そのため、解決策が見つからず困っていましたが、API GatewayのCloudWatchログの有効化がやや面倒だったため、最初は有効化せずに作業を進めていました。
しかし、ログを有効化して確認したところ、**「API GatewayがLambdaにアクセスする権限を持っていない」**というエラーが記録されていました。
Execution failed due to configuration error: Invalid permissions on Lambda function
CloudWatchログの有効化を推奨します。
Lambda側のエラーではない場合でも500の内部エラーが返ることがありますが、Lambdaが実行されていない場合は、API Gateway側の設定を確認しましょう。
パーミッションの付与に関する情報が少なく、最後まで気づくことができませんでした。