tr:dr
- AWS Glueは様々なところからデータを集めて、加工して、一箇所に保存する環境を一手に提供してくれるサービス
- Sparkクラスタをサーバレスで用意出来るのめっちゃ便利
AWS Glueとは
AWS Glue は抽出、変換、ロード ([ETL]) を行う完全マネージド型のサービスで、お客様の分析用データの準備とロードを簡単にします。AWS マネジメントコンソールで数回クリックするだけで、ETL ジョブを作成および実行できます。AWS Glue では、AWS に保存されたデータを指定するだけで AWS Glue によるデータ検索が行われ、テーブル定義やスキーマなどの関連するメタデータが AWS Glue データカタログに保存されます。カタログに保存されたデータは、すぐに検索、クエリ、ETL で使用できます。AWS Glue では、データ変換とデータのロードプロセスを実行するコードが生成されます。
AWS Glue で生成されるコードは、カスタマイズ性、再利用性、可搬性を備えています。ETL ジョブの作成が完了したら、AWS Glue のフルマネージド型 Apache [Spark] スケールアウト環境でジョブの実行をスケジュールできます。AWS Glue では、依存性の解決、ジョブのモニタリング、アラートを行う柔軟なスケジューラを提供します。
AWS Glue はサーバーレスであるため、インフラストラクチャの購入、設定、管理は不要です。ジョブの実行に必要な環境が自動的にプロビジョニングされます。また、お客様が支払うのは、ETL ジョブの実行中に使用したコンピューティングリソースの費用のみです。AWS Glue では、分析用のデータは数分で準備できます。
ETL
- そもそもETLって何?
Extract/Transform/Load
Extract/Transform/Load(略称:ETL)とは、データウェアハウスにおける以下のような工程を指す。Extract - 外部の情報源からデータを抽出
Transform - 抽出したデータをビジネスでの必要に応じて変換・加工
Load - 最終的ターゲット(すなわちデータウェアハウス)に変換・加工済みのデータをロード
- ETLというのは複数のデータソース(RDB, CSV, No SQL…)で同じフォーマットになっていないものを抽出→変換→ロードを行うことで、BIなどで利用可能な形に変更する作業
AWS Glueの機能
- AWS Glueにはたくさんの機能があるのですが、主要な機能として、 Crawler 、 Job 機能があります。
Crawler
- スクレイピングとよくセットで話される。所謂Crawlerです。GlueではこのCrawlerを使って、必要なデータをまず集めることが出来ます。ELTのExtractを部分を受け持つ部分です。
Data store
- crawlingするためのデータ対象を設定出来ます。S3, JDBC, DynamoDBを選択出来ます。Data storeは複数指定出来るので、複数のところから大量のデータを集める事ができます。
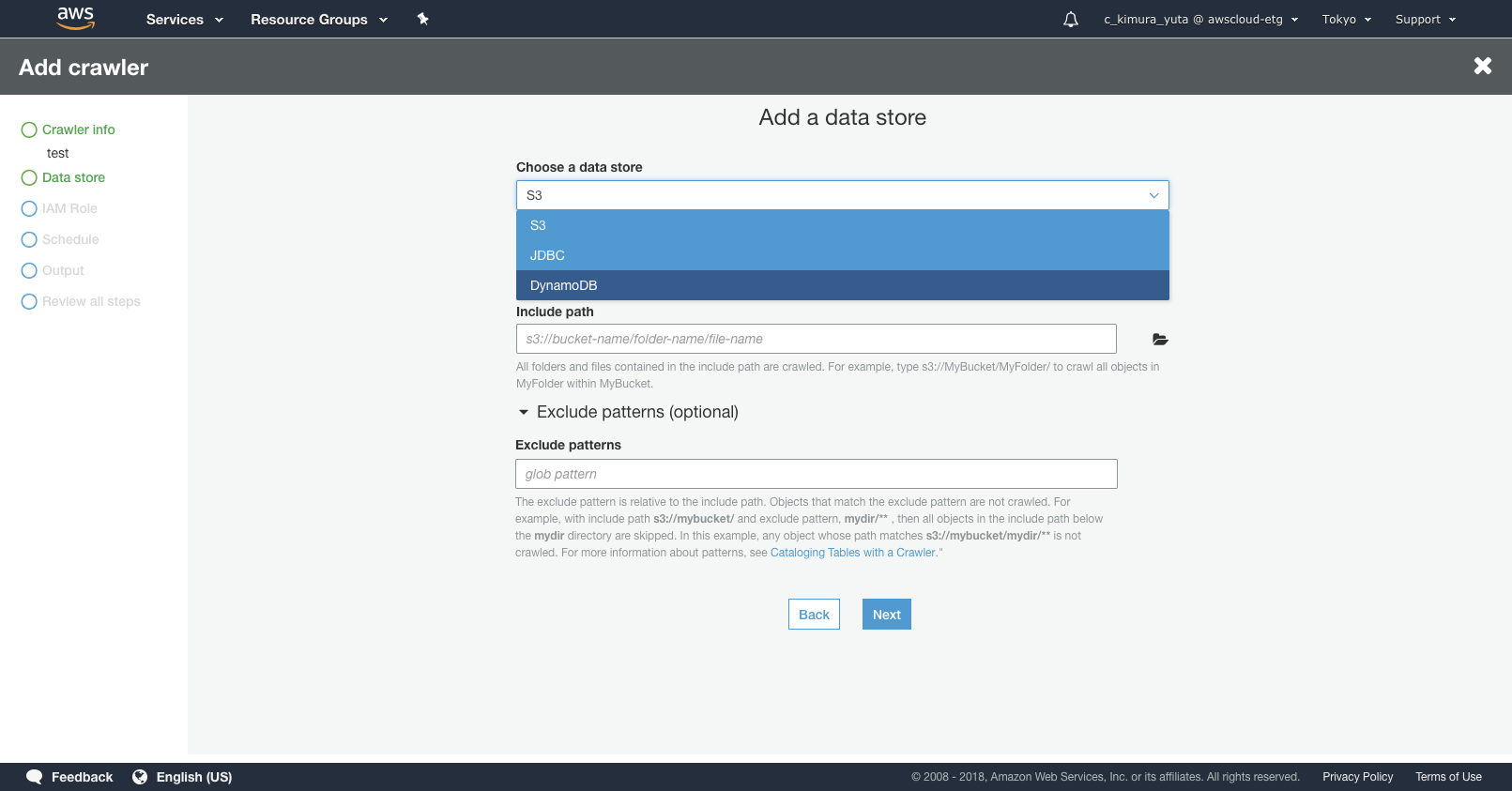
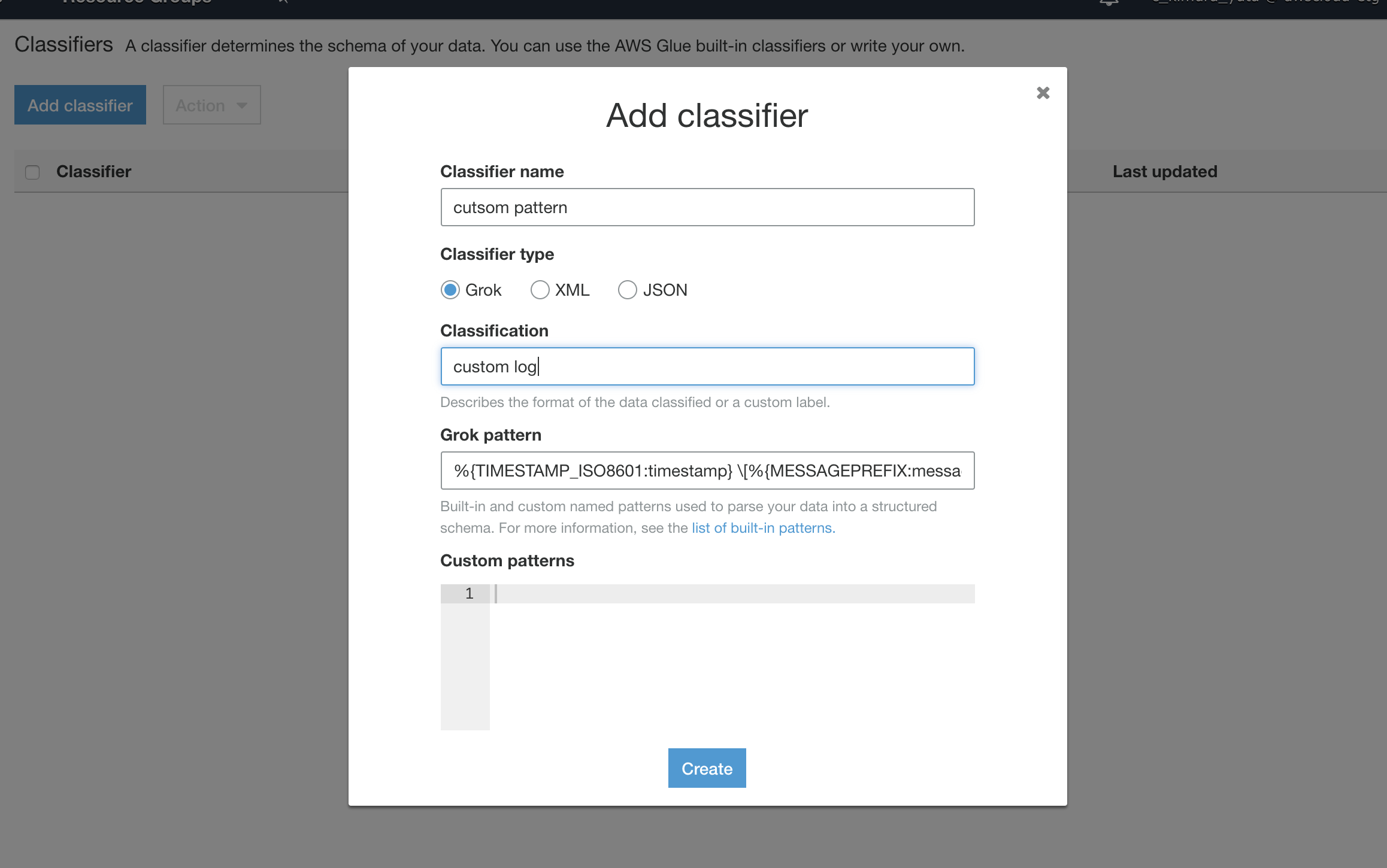
Classifier
- LogstashにあるGrokパターンを利用して、data storeから決まった形式のデータを認識すると、data catalogのスキーマを生成してくれます。標準のGlueの組み込みGrokフィルターもありますが、組み込みに自分が取り込みたい形式が無い場合は自分でカスタムのGrokパターンを書いて定義することもできます。
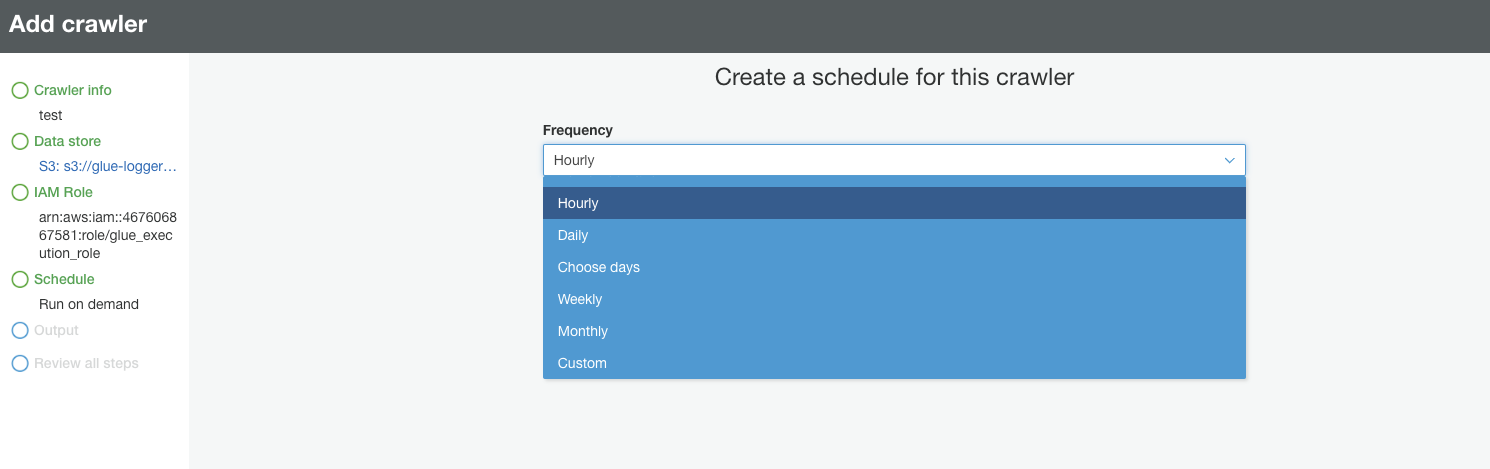
Schedule
- Crawlerの実行のScheduleを指定できます。日時、On-demand、CustomでCron形式でかけます。もちろんLamdbaなどから起動することも可能
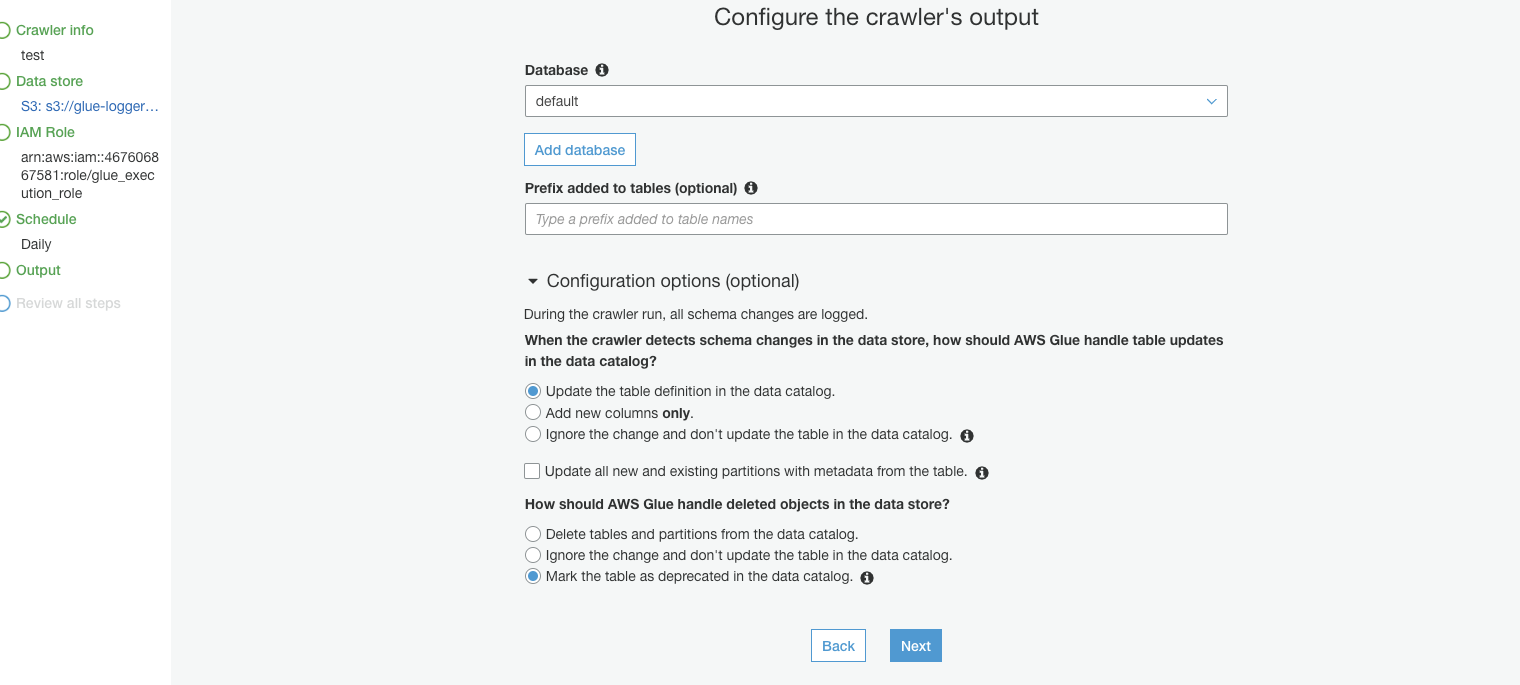
Output
- Crawlerが集めたデータの出力先を指定する。集めたデータはAWS Glue データカタログ として保存されます。
- AWS Glue data catalogはApache Hiveメタストア互換で、データベースや、テーブル、パーティションに関する情報(メタデータ)をS3に保存します。
- この時点ではあくまでこのデータはどこにあるか?などの情報だけを持っているだけで、データを変換して保存し直しているわけではありません。ただdata catalogにまとめることによって複数の箇所にあったデータをAthenaを利用して一括で検索出来るようになったり、後述のJobやEMRなどでGlue data catalogを参照して、変換・集計することが出来るようになります。
Job
-
ELTのTransformと Loadを部分を受け持つ(Extractも出来る)
-
SparkオンリーなサーバレスEMR
-
マネージドでサーバレスなSparkの実行環境を提供。
-
Crawlerで集めたdata catalogを元にデータを変換・整形をしてS3,RDB,Redshift,DynamoDBなどに流しこんだり、またJob単体でもデータのロードの集計をすることができます。
-
ユースケース
- 複数の異なるスキーマのdata storeからのデータを取得して、同じスキーマに変更して他のdata storeに入れる。
- data storeから取得したデータを集計して、他のdata storeに入れる。
- S3に保存する際にParquetやORC形式に変換して、データ量やクエリ時間を短くすることにも利用出来る。
-
利用できる言語
- Python(Pyspark)とScalaが利用出来る。
- Pythonが2.7,Scala 2.11系にしか対応していない部分が少しつらい。
-
料金体系
- 実行時間とDPU単位で課金がされます。
-
実行ファイル
- 実行ファイルはS3において
spark-submitでファイルを読み込んで実行。
- 実行ファイルはS3において
-
開発環境
- AWS glueは開発endpointという形でJob Scriptの開発環境も提供しており、インタラクティブにスクリプトの開発も出来るようです(まだ試してない)
- https://docs.aws.amazon.com/ja_jp/glue/latest/dg/dev-endpoint.html