はじめに
2025/6/12~19に開催された「第4回 AI Challenge Day」に参加してきました!
本イベントは、株式会社角川アスキー総合研究所主催 × 日本マイクロソフト株式会社協賛の生成AIのハッカソンです。
RAGアーキテクチャを用いた質問応答システムや一連の会話をするAIエージェントを構築し、回答精度を競い合います。
BIPROGYは、前年度の第2回以来再び参加させていただきました。
今年も、普段AI全般の技術検証・製品開発および適用を行っている部隊のメンバー5人で参加してきました。
この記事では、AI Challenge Day で出題されたECサイトというテーマに対して、BIPROGY がどんな RAG や AI エージェント のシステムを構築したかをご紹介します!!
発表会と授賞式はYouTubeで公開されています。
なお、前年度の記事はこちらになります。
ASCII × Microsoft の生成AIコンテスト「第2回 AI Challenge Day」参加レポート
第4回大会概要
お題
第4回大会のお題は、ECサイトにおける次世代顧客体験を提案するAIエージェントの開発です。
RAG(Retrieval-Augmented Generation)やAIエージェントを用いたシステムを構築し、用意された7体の仮想顧客ペルソナからの指示や質問に、どれだけ正確に回答できるかの精度を競います。
問題は問1から問5まであります。
問1〜4
問1〜4では、事前に与えられた顧客ペルソナからのクエリ(質問)に対し、システムの出力が Ground Truth にどれだけ近づけられるかを評価します。
精度評価には以下の2つの方法があります。
- AIの出力と Ground Truth の類似度や流暢性などをLLMにより評価、スコア化する方式
- AIの出力と Ground Truth のコサイン類似度を用いてスコアを算出する方式
問5
問5では、開発したAIエージェントが7人の仮想顧客ペルソナと対話を行い、以下の観点などで評価されます(表記観点は一部のみ):
- 購入金額(評価方法: ルール)
- 購入に至るまでの対話過程(評価方法: LLM, ルール)
- レスポンスタイム(評価方法: ルール)
- 顧客のプライバシー対応(評価方法: LLM)
- マルチモーダルへの対応(評価方法: LLM)
データの種類
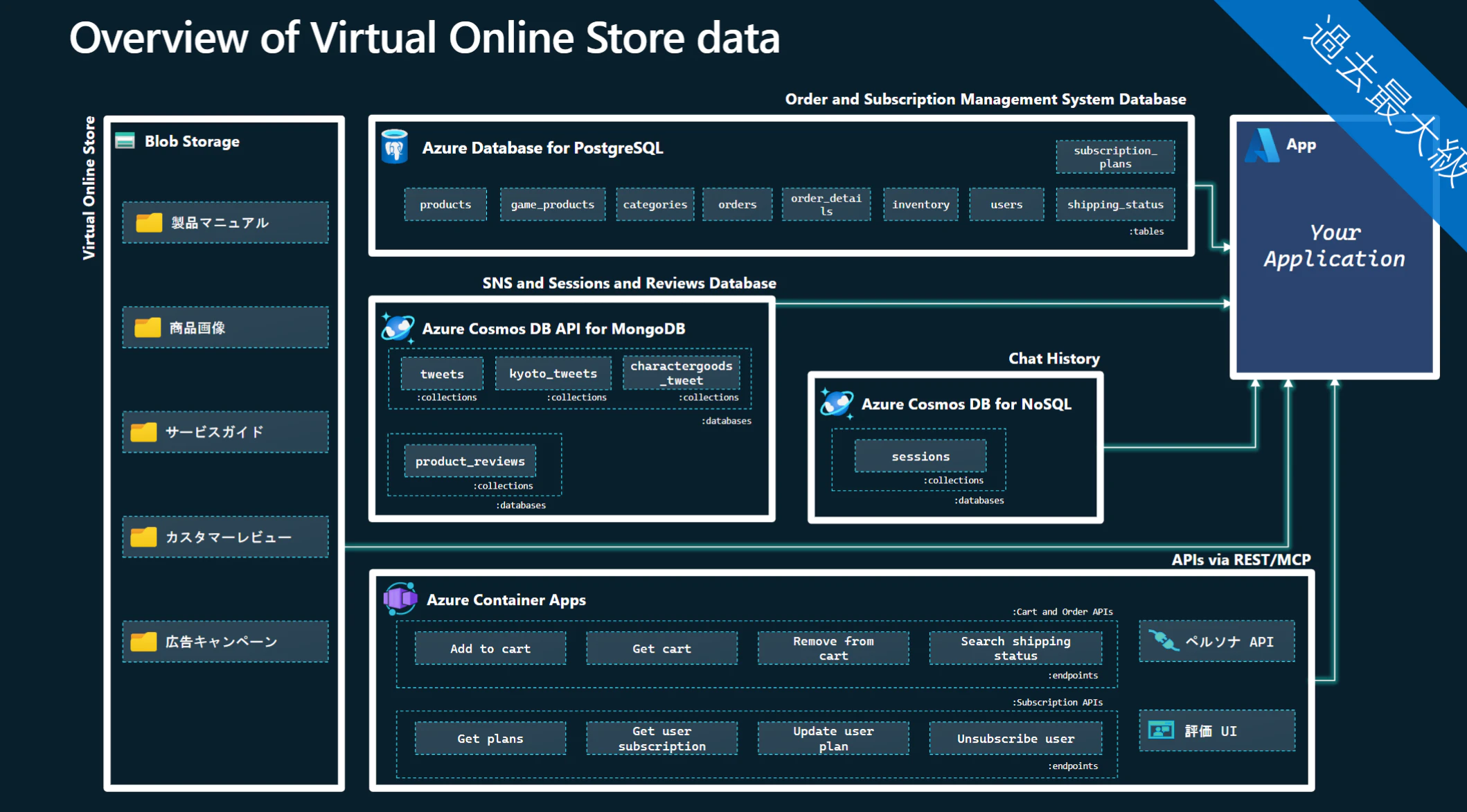
問1〜5を通じて、RAGでは以下のような多様な非構造化・構造化データを利用し、各ペルソナの質問に的確に回答する必要があります。
主なデータ例は以下の通りです。
-
構造化データ(PostgreSQL)
- 商品、カテゴリ、注文、ユーザーなど
-
半構造化データ(MongoDBやNoSQL)
- Xの口コミ、商品レビュー
- 会話履歴
-
非構造データ(PNGやPDFなど)
- 商品画像、製品マニュアル、サービスガイド、カスタマーレビュー、広告キャンペーン資料
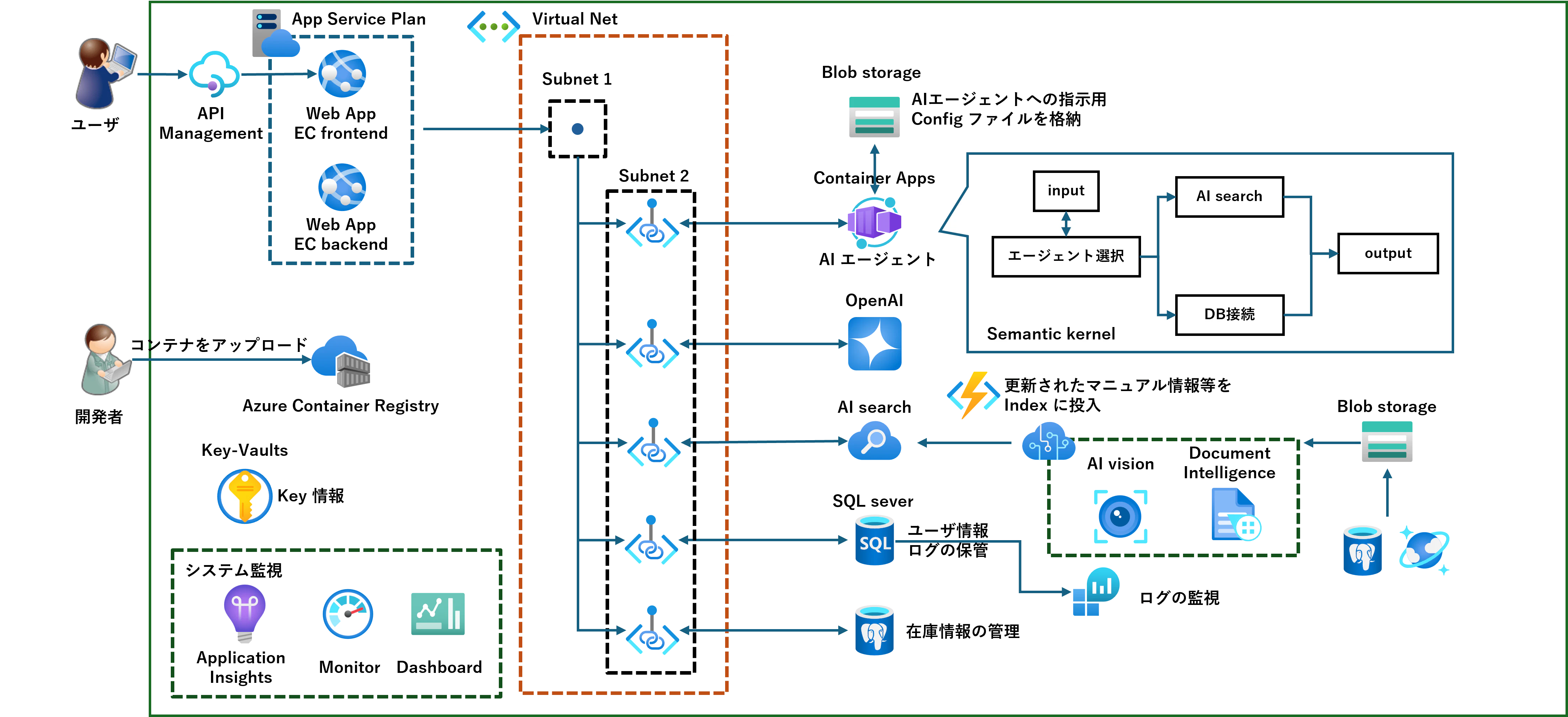
アーキテクチャ
最終的に以下の構成にしました。基本的なRAGの構成を採用し、AIエージェントのフレームワークには Semantic Kernelを採用しています。詳細については後述しますが、ポイントは以下の通りです。
- PDF・Word・PowerPoint・Excel・HTMLは Azure AI Document Intelligence で文字起こし
- 画像ファイルは Azure AI Vision の Vectorize Image APIでベクトル化し、 Azure OpenAI Service の gpt-4.1-mini モデルで画像の説明文を生成
- AIエージェントへの指示を定義する Config ファイルは Azure Blob Storage で一元管理し、指示文のみの変更であれば再デプロイせず動的に変更が可能
RAG
Azure AI Search には インデクサー という機能があり、Azureポータルのデータのインポートウィザードから利用すると、以下をノーコード/ローコードで行うことができます。
- データ取得の自動化:Azure Blob Storage、Azure Cosmos DB、Azure SQL Databaseなどの外部データソースと接続し、データを自動で取得
- スキルセットとの連携:OCR、言語翻訳、言語解析などの組み込みAIスキルやカスタムスキル(カスタムスキル自体は開発が必要)と連携し、取り込んだデータの前処理・加工が可能
- インデックス設計:インデックスのスキーマ(フィールド定義など)の設定が可能
- スケジューリング:インデクサーは定期実行するようにスケジュール設定が可能
- 差分更新の対応:前回以降に変更されたデータのみを検出し、インデックスの更新が可能
今回はデータセットのうち、構造化データ(商品マスタなど)、半構造化データ(Xの口コミ)についてインデクサーによる取り込みを実施しました。
※非構造化データについては後述しますがインデクサーを使わず取り込んでいます。
構造化データ・半構造化データの取り込み
前処理
ノーコードでとは書きましたが、実際は前処理をAzure Functionsで行ってからインデクサーを作成しました。今回はインデクサーに不慣れで時間がなく諦めましたが、前処理はカスタムスキル(カスタムWeb APIスキル)を使っても実装できると思います。
- 構造化データ:キー項目で関連するテーブル同士をあらかじめ結合し、CSV化
- 半構造化データ:MongoDB Extended JSONのオブジェクト(例:$date)の
$を削除(インデックスのフィールド名に$が使えないため)
構造化データ(PostgreSQL)をCSV化した理由
PostgreSQL の活用については2つの方法を検討しました。
- SQL を function calling によって自動生成し、そこからデータを取得する
- テーブルを CSV 化し、Azure Blob Storage に格納し、必要なコンテキストをセマンティック検索で取得する
私たちはこのうち2の CSV 化してセマンティック検索の方法で行いました。
1 の方法で進める場合、 SQL 文を自由に作成するには各種プロンプトにスキーマ定義を含めてやる必要があり、これに時間がかかります。
また、今回の課題においてはセマンティック検索でも十分に必要な情報を含められることが検証段階で分かったため、比較的実装コストが低い方を 2 の方法を採用しました。
実運用では、ハイブリッドで利用するなど、いろいろな工夫をしていきたいですね。
後処理
インポートウィザードからインデクサーを作成すると、インデックスの言語アナライザーが標準の標準 - Lucene となります。しかし、より精度をあげるために日本語 - Microsoft としたかったため、インデックスやインデクサーの json ファイルをコピー・修正し、json ファイルからポータル画面上でインデックス等を作成し直しました。
非構造化データの取り込み
非構造化データについてもインデクサーによる取り込みをウィザード上からしようとしましたが、思ったように作成することができず時間を優先して断念しました。
取り込みは、SDK を用いて行いました。
こちらは今後もっと勉強していきたいと思います!
PNG・JPEG
画像ファイルについては商品画像が多く含まれており、以下のフィールドで画像インデックスへ登録しました。
- 画像のベクトル:画像をベクトル化した値
ベクトル化には Azure AI Vision の Vectorize Image API を使用しました。 - 説明文:画像について gpt-4.1-mini に説明させた文章
- ファイル名:画像のファイル名
しかし、残り1日程となった際に商品画像以外で OCR するべき画像ファイルを発見・・・!時間の都合上諦めましたが、データの確認をしっかりすべきだったという反省点になりました。
PDF・Word・PowerPoint・Excel・HTML
Azure AI Document Intelligence を使用してテキストを抽出し、以下のフィールドで登録しました。ページ情報は今回のお題では不要と判断し、利用しませんでした。
- コンテンツ:抽出したテキスト情報(チャンク分割したもの)
- コンテンツベクトル:コンテンツをベクトル化した値
- ファイル名:ドキュメントのファイル名
検索
ペルソナとの会話の中では、会話の内容に応じて検索する内容も多様でしたが、代表的なものについてどのように検索を行ったかご紹介します。
評判検索
ペルソナの中には他の人の評判を元に商品を紹介して欲しいという人もいたため、評判検索が必要となります。検索のフローとしては以下のようになります。
- X の口コミやレビューのインデックスに対して、ハイブリッド検索を実施
- レビューの json ファイルから商品と評価、レビュー内容を読込み
- 1、2の結果から回答生成
2 についても本来はインデックスを作成した方が良かったかもしれませんが、ファイルサイズとしても大きくはなかったため、時間の都合上今回はそのまますべてのデータをAIエージェントのコンテキストに持たせました。
商品検索
商品検索では質問だけでなく、質問と一緒に画像ファイルを送られるケースがあるため、マルチモーダル検索が必要となります。そのため以下のフローで検索を実行しました。
- 質問に添付された画像をベクトル化
- 画像ファイル用インデックスに対してベクトル検索を実施
- 商品マスタインデックスに対して、2 の結果から得られた画像の説明文と質問文を元にベクトル検索を実施
- 3 の結果から回答生成
ECエージェントの実装
ECエージェントは単一のエージェントではなく大きく分けて以下の役割を持つエージェントが必要と考えました。
- カスタマー対応:実際にお客様とやり取りをするエージェント。問い合わせの初期対応以外にもカスタマーハラスメントの対応や商品購入後の会員登録案内やレビュー依頼などを行います
- 商品の検索:お客様の要望に合う商品を検索するエージェント
- 購入対応:実際にカートの操作を行い、商品の追加や決済を行うエージェント
今回はこれらの役割をさらに細分化して以下の10個のエージェントを作成しました。
懇親会で他の参加企業に聞いた限りでは、弊社の作成した構成が一番エージェントの数が多かったです。
| 種別 | 役割 |
|---|---|
| カスタマー対応エージェント | お客様への初期対応を行うエージェント。過去に利用履歴のあるお客様の場合は履歴を取得し、お客様の要望に沿った処理を行うように調整を行います。 |
| PC関連商品検索エージェント | PCやマウス、キーボード等PCに関連する商品を検索するエージェント。 |
| 電子機器検索エージェント | 電子機器に該当する商品を検索するエージェント |
| キャラクターグッズ検索エージェント | キャラクターグッズに該当する商品を検索するエージェント |
| ゲーム検索エージェント | ゲームに該当する商品を検索するエージェント |
| 評判検索エージェント | SNSなどの情報から商品の評判に関連する情報を検索するエージェント |
| 定期購入商品検索エージェント | ゲームプランのサブスクリプションなど定期購入することができる商品を検索するエージェント |
| カート操作エージェント | カートへの商品の追加や削除を行うエージェント |
| 決済エージェント | 現在カートに入っている商品の購入手続きを行うエージェント |
| レビューエージェント | 会員登録やレビューの対応を行うエージェント |
マルチエージェントを動かすためのフレームワークとしては、この後説明する Semantic Kernel を利用しています。
Semantic Kernel とは
Semantic Kernel は、Microsoft が開発している生成AIアプリケーション/AIエージェントアプリケーション向けのオープンソースフレームワークです。
Semantic Kernel でのマルチエージェント実装
Semantic Kernel でAI エージェントアプリケーションを開発するには、Semantic Kernel Agent Framework と Semantic Kernel Prompt Framework の2通りの方法があります。
先に結論から言うと、ECエージェントを構築するにはユーザーから寄せられる多種多様なタスクに対して個別のロールを持つエージェントが必要に応じて処理を引き継いでタスクを処理したいため Handoff を使うことのできる Agent Framework を採用しました。
Agent Framework
役割ごとに AI エージェントを定義することでユーザーの指示に対して自律的に考えタスクを遂行するためのフレームワークです。エージェントが連携する方法として以下の5種類があります。
| 方法 | 概要 | 適用場面 |
|---|---|---|
| Concurrent | 与えられたタスクをすべてのエージェントにブロードキャストし、結果を個別に収集します。 | さまざまなロールを持つエージェントにそれぞれの立場から回答を作成させる場合に用います。 |
| Sequential | 定義された順番にエージェントを呼び出します。エージェントには前のエージェントの結果を使って処理を行うことができます。 | タスクの処理方法を普遍的な順番で処理できる場合に用います。 |
| Group Chat | グループマネージャーが様々なロールを持つエージェントをコントロールしてタスクを処理します。 | グループ内のエージェントと複数回やり取りをして回答を作成する場合に用います。 |
| Handoff | ルールに基づいて他のエージェントに処理を引き継ぎます。適切にルールを作成することで適切なエージェントに引き継いでタスクを処理することができます。 | 明示的に エージェント間で処理を引き継いでタスクを行いたい場合に用います。 |
| Magentic | Magentic マネージャーが与えられたタスクに対して動的にプランを生成しタスクごとにエージェントを割り当ててタスクを処理します。 | 自動的にエージェントを呼び出してタスクを行う場合に用います。 |
Prompt Framework
複雑なワークフローを自動化するためのフレームワーク。ワークフローの各処理をステップとして実装し、各ステップの実行順序を定義することでワークフローを組むことができます。
semantic kernel におけるエージェントの作り方
semantic kernel において、エージェントは以下のように定義できます。
import os
import requests
from semantic_kernel.connectors.ai import FunctionChoiceBehavior
from semantic_kernel.functions import kernel_function
from semantic_kernel.agents import ChatCompletionAgent
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
AzureChatCompletion(
api_key=os.environ.get("API_KEY"),
deployment_name=os.environ.get("DEPLOYMENT_NAME"),
endpoint=os.environ.get("ENDPOINT"),
api_version=os.environ.get("API_VERSION"),
)
# PC検索エージェント
search_pc_agent = ChatCompletionAgent(
name="SearchPC",
description="PC関連の検索をするエージェント",
instructions=(
"お客様の要望に沿ったPCまたはPCに関連する商品を検索し情報を提供してください。"
"取得した情報が多い場合は、要望に沿った情報のみに要約してください。"
"回答を行ってもユーザーが再質問する可能性があるため、絶対にタスクを完了させないでください。"
),
service=AzureChatCompletion,
plugins=[SearchPCPlugin()],
)
実際に作成したPC検索のエージェントを例に説明します。
今回は、 sementic kernel におけるエージェントをChatCompletionAgentで定義しました。
定義したエージェントにおけるそれぞれの引数は以下のような意味となっています。
-
name: エージェントの名前 -
description: エージェントの役割 -
instructions: エージェントがこなすタスク内容 -
service: Azure Open AI サービスへの接続情報 -
plugins: 実行されるプラグイン
エージェントがPC検索できるよう、SearchPCPluginというプラグインを定義します。
このプラグインには、RAGを用いてPCの検索を行う kernel 関数を含めます。
class SearchPCPlugin:
@kernel_function
async def search_pc(self, text: str, image_urls: list) -> str:
image_results_str = ""
for image_url in image_urls:
# 画像情報の取得
image_response = requests.get(image_url)
# 画像のベクトル化
image_vector = vectorize_data(image_response.content)
# ベクトル検索
image_results = search_vector(image_vector, "image-index", "image_vector")
image_results_str_result = "\n".join([
result["caption"] for result in image_results
])
image_results_str = image_results_str + image_results_str_result
# 商品情報の検索クエリ
query = text + image_results_str
# 商品情報の検索
pc_products_text_vector = await generate_embeddings(query)
pc_products_results = search_text_and_vector(
query,
pc_products_text_vector,
"rag-products-master",
"text_vector",
top=5,
k_nearest_neighbors=5,
)
# 検索結果の格納
pc_result_list = []
for pc_result in pc_products_results:
pc_result_list.append(
(
f"商品名: {pc_result["name"]}\n"
f"型番: {pc_result["model_number"]}\n"
f"価格: {pc_result["price"]}\n"
f"詳細: {pc_result["chunk"]}\n"
f"重量: {pc_result["weight"]}\n\n"
)
)
# 商品マニュアルの検索
pc_text_vector = await generate_embeddings(query)
pc_text_results = search_text_and_vector(
query,
pc_text_vector,
"text-index",
"content_vector",
top=5,
k_nearest_neighbors=5,
)
for pc_result in pc_text_results:
pc_result_list.append(
f"マニュアル情報: {pc_result["content_text"]}"
)
pc_results_str = "\n".join(pc_result_list)
agent_response = pc_results_str
return agent_response
kernel 関数内に出てくる関数は以下です。
kernel 関数内に出てくる関数
from azure.search.documents import SearchClient
from azure.search.documents.models import VectorizedQuery
from azure.core.credentials import AzureKeyCredential
API_VERSION = os.getenv("API_VERSION")
MODEL_VERSION = os.getenv("MODEL_VERSION")
AI_SERVICE_ENDPOINT = (
os.getenv("AI_SERVICE_ENDPOINT")
+ f"computervision/retrieval:vectorizeImage?api-version={API_VERSION}&model-version={MODEL_VERSION}"
)
AI_SERVICE_KEY = os.getenv("AI_SERVICE_KEY")
SEARCH_ENDPOINT = os.environ.get("AI_SEARCH_ENDPOINT")
AI_SEARCH_API_KEY = os.environ.get("AI_SEARCH_API_KEY")
# セマンティック検索のために使用するセマンティック構成を定義
def get_target_semantic_configuration(query_type, search_index_name):
match search_index_name:
case "image-index":
semantic_configuration = "image-index-semantic-configuration"
case "rag-game-products":
semantic_configuration = "rag-game-products-semantic-configuration"
case "rag-products-master":
semantic_configuration = "rag-product-master-semantic-configuration"
case "rag-twitter":
semantic_configuration = "rag-twitter-semantic-configuration"
case "text-index":
semantic_configuration = "text-index-semantic-configuration"
case _:
query_type = "simple"
semantic_configuration = None
return query_type, semantic_configuration
# AI search によるベクトル検索
def search_vector(
vector,
search_index_name,
search_fields,
k_nearest_neighbors=10,
query_type="semantic",
):
client = SearchClient(
endpoint=SEARCH_ENDPOINT,
credential=AzureKeyCredential(AI_SEARCH_API_KEY),
index_name=search_index_name,
)
vector_query = VectorizedQuery(
kind="vector",
vector=vector,
k_nearest_neighbors=k_nearest_neighbors,
fields=search_fields,
)
if query_type == "semantic":
query_type, semantic_configuration = get_target_semantic_configuration(
query_type, search_index_name
)
vector_results = client.search(
vector_queries=[vector_query],
query_type=query_type,
semantic_configuration_name=semantic_configuration,
)
return vector_results
# AI search によるテキスト検索
def search_text(query, search_index_name, filter=None, top=5, query_type="semantic"):
client = SearchClient(
endpoint=SEARCH_ENDPOINT,
credential=AzureKeyCredential(AI_SEARCH_API_KEY),
index_name=search_index_name,
)
if query_type == "semantic":
query_type, semantic_configuration = get_target_semantic_configuration(
query_type, search_index_name
)
search_text_results = client.search(
query,
filter=filter,
query_type=query_type,
semantic_configuration_name=semantic_configuration,
top=top,
)
return search_text_results
# AI search によるハイブリッド検索
def search_text_and_vector(
query,
vector,
search_index_name,
search_fields,
filter=None,
top=5,
k_nearest_neighbors=5,
query_type="semantic",
):
client = SearchClient(
endpoint=SEARCH_ENDPOINT,
credential=AzureKeyCredential(AI_SEARCH_API_KEY),
index_name=search_index_name,
)
vector_query = VectorizedQuery(
kind="vector",
vector=vector,
k_nearest_neighbors=k_nearest_neighbors,
fields=search_fields,
)
if query_type == "semantic":
query_type, semantic_configuration = get_target_semantic_configuration(
query_type, search_index_name
)
search_text_and_vector_results = client.search(
search_text=query,
top=top,
vector_queries=[vector_query],
query_type=query_type,
filter=filter,
semantic_configuration_name=semantic_configuration,
)
return search_text_and_vector_results
上記のように定義したエージェントを複数組み合わせることでマルチエージェントを実現できます。
semantic kernel におけるマルチエージェントの作り方
マルチエージェントはシングルエージェントを組み合わせて実装します。
def agent_response_callback(message: ChatMessageContent) -> None:
# エージェントからのコールバックを出力するオブザーバ機能
print(f"{message.name}: {message.content}")
def human_response_function() -> ChatMessageContent:
# エージェントからのメッセージを出力するオブザーバ機能
user_input = input("User: ")
return ChatMessageContent(role=AuthorRole.USER, content=user_input)
# 顧客対応を行うエージェント
customer_service_agent = customer_service_agent
# 商品購入を行うエージェント
purchase_agent = purchase_agent
# レビューをもらうエージェント
review_agent = review_agent
# 上記で作成したエージェント
search_pc_agent = search_pc_agent
handoffs = (
OrchestrationHandoffs()
.add_many(
source_agent=customer_service_agent.name,
target_agents={
search_pc_agent.name: "PCに関連する要望であれば、このエージェントに転送する。",
purchase_agent.name: "決済に関する要望であれば、このエージェントに転送する。",
},
)
.add(
source_agent=purchase_agent.name,
target_agent=review_agent.name,
description="レビューや会員登録に関する要望であれば、このエージェントに転送する。",
)
.add_many(
source_agent=review_agent.name,
target_agents={
search_pc_agent.name: "PCに関連する要望であれば、このエージェントに転送する。",
purchase_agent.name: "決済に関する要望であれば、このエージェントに転送する。",
},
)
)
agents = [
customer_service_agent,
purchase_agent,
review_agent,
search_pc_agent
]
handoff_orchestration = HandoffOrchestration[AgentInput, ChatMessageContent](
members=agents,
handoffs=handoffs,
input_transform=input_transform,
agent_response_callback=agent_response_callback,
human_response_function=human_response_function,
)
OrchestrationHandoffsにエージェントを追加していくことでマルチエージェントを作成できます。
複数のエージェントの中から適切なエージェントへのルーティングを行う際には以下のように記述します。
.add_many(
source_agent=customer_service_agent.name,
target_agents={
search_pc_agent.name: "PCに関連する要望であれば、このエージェントに転送する。",
purchase_agent.name: "決済に関する要望であれば、このエージェントに転送する。",
},
)
-
source_agent: ルーティングの元となるエージェント名 -
target_agents: ルーティングの先となるエージェント名とルーティング条件
単一のエージェントへのルーティングを行う際には以下のように記述します。
.add(
source_agent=purchase_agent.name,
target_agent=review_agent.name,
description="レビューや会員登録に関する要望であれば、このエージェントに転送する。",
)
-
source_agent: ルーティングの元となるエージェント名 -
target_agent: ルーティングの先となるエージェント名 -
description: ルーティング条件
エージェントの実行方法
エージェントの実行のために、最初にランタイムを起動してエージェントの実行を管理する必要があります。
from semantic_kernel.agents.runtime import InProcessRuntime
runtime = InProcessRuntime()
runtime.start()
その後、タスクを与えオーケストレーションを呼び出します。
orchestration_result = await handoff_orchestration.invoke(
task="ECサイトの購入補助を行ってください。",
runtime=runtime,
)
結果を取得し、タスクが完了した場合にはランタイムを停止させます。
value = await orchestration_result.get()
print(value)
await runtime.stop_when_idle()
これを実行することで以下のような回答が得られます。
customer_service_agent: いらっしゃいませ、本日は何をお探しでしょうか?
User: 事務作業用で中程度のスペックを希望しています。タブレットにも興味があります。これらの条件に合うモデルはありますか?
search_pc_agent: 事務作業用で中程度のスペックかつタブレットに興味があるとのことですので、以下のモデルが条件に合いそうです。
1. 法人向け Surface Pro 9
- タブレットの携帯性とノートPCのパフォーマンスを併せ持つモデル
- 仕事に必要なパワーと効率を提供
- 価格は約232,980円
2. 法人向け Surface Go 4
- 521g と非常に軽量なポータブル2-in-1モデル
- フィールド作業にも対応可能
- 価格は約97,680円
Surface Pro 9は性能面で中程度以上のスペックが期待でき、Surface Go 4はより軽量で携帯性重視のモデルです。用途や予算に合わせて選択可能です。
さらに詳細なスペックや比較を希望される場合はお知らせください。
User: 法人向け Surface Pro 9 をカートに入れてください。
purchase_agent: 法人向け Surface Pro 9 をカートに1台追加しました。他にご希望の商品や操作はありますか?
User: 特にない、ありがとう。
purchase_agent: ありがとうございました。またのご来店をお待ちしております。
ECエージェントの実装で困ったポイント
今回初めて Semantic Kernel を使用してみましたが、マルチエージェントなシステムを構築する上でいくつか困ったポイントがありました。
全体的に Semantic Kernel の仕様を理解しきれていないことに起因しています。
困ったポイント1:エージェントをうまく呼び出せない
Handoff を利用していたため、必要になったタイミングでうまく他のエージェントに引き継いでくれることを期待していましたが、引き継いでほしいタイミングで引き継ぎが派生せず違うエージェントで処理を実施してしまうことが多々ありました。
具体的には、商品検索後のカートへの追加操作はカート操作エージェントが行う想定でいましたが、PC関連商品検索エージェントなど検索エージェントが行ってしまう場面がありました。
商品検索用のエージェントにはカート操作を行う処理を定義してませんので、レスポンスに 「カートに登録しました。」 と記載されていても実際にカート登録はされていませんでした。
原因としては、処理を引き継ぐ条件の設定や各エージェントの役割を明確に定義できてなかったことにあると思っていますが、最後まで完全になくすことは出来ませんでした。
困ったポイント2:エージェントの引継ぎ時に渡している情報がわからない
前述の通りエージェント内で検索処理など追加の処理を行う場合はプラグインを実装します。
プラグインの引数は、LLM が判断して適切なものを渡してくれるのですが、Handoff が発生して何度かエージェントに処理を引き継いだ場合に間違った引数が割り当てられました。
今回の課題では、ユーザーIDやセッションIDなど一連の処理の中で一意に管理しないといけない値があったのですが、実際に実行してみるとエージェント呼び出しごとで違う値になってる場合がありました。
どうやったら解決できるのかわからなかったので、最終的にはプラグインの引数で渡すのではなく外部の値を参照することで問題を回避しました。
困ったポイント3:消費したトークン数がわからない
問5の評価項目には入出力のトークン数が入っていたため、トークン数を取得する必要がありました。
しかし、実装の終盤でトークン数を取得しようとしたときに、レスポンスに含まれておらずどうやっても取得できないことが分かりました。
最終的には、技術サポートスタッフの方に助けていただく形でトークン数を取得することができました。
詳細については、ここでは長くなるので割愛させて頂きます。
ライブラリ内のコードを修正する方式だったため、ライブラリ側で対応いただけるのを待っています!!!
結果!!
気になる結果は...
157.0点でした!!
そして結果の方は全体の5位となります。
上位とはいえ悔しい...
特にエージェントとの会話を行う問5では、自分たちの想定していないエージェントにルーティングされてしまうことが多く、なかなか難しかったです。
たくさんのエージェントに適切にルーティングを行うための構成についてもっと考える時間があればよかったと思います。
おわりに
以上、 AI Challenge Day の参加レポートでした。
AIエージェントの技術が日々進化していく中で、実際に手を動かしていくことでどのように実装していくかを深く知ることができました。
また、同じ課題に取り組んだ他社様の発表を聞くことで、自分たちにはない視点を得ることが出来ました。
課題は難しくなかなか精度があがりませんでしたが、とても楽しかったです!
次回もぜひ参加したいです!
We Are Hiring!