初めに
現場でAWSのコンテナサービスであるECSを利用し、システムを構築した際のハマったポイントについて共有します。
そもそもECSとは
Amazon ECS(Elastic Container Service)はコンテナ化されたアプリケーションを簡単にデプロイ、管理、スケーリングできる、完全マネージド型のコンテナオーケストレーションサービスです。(AWS公式ドキュメントより)
コンテナ化したアプリをマネージドサービスで利用したいという場合に選択されることが多く、 CI/CDパイプラインと合わせて導入されるケースも見受けられます。
ECSでは、コンテナをタスク定義という形で記述します。
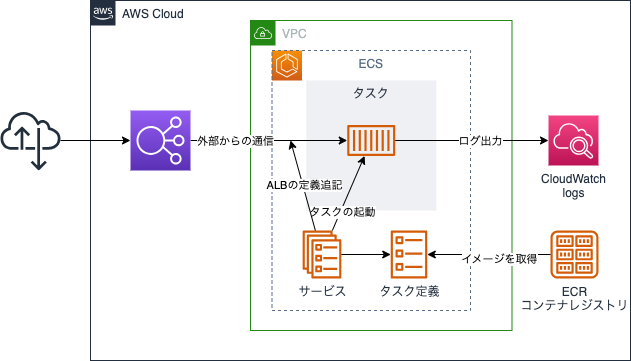
ECSの詳細な説明は割愛するため、上述の公式ドキュメントをご確認ください。
利用してみて気になること
マネージドサービスを利用している分、ユーザ側ではコンテナをデプロイしたら気軽に使える一方、以下のようなことを調べるときに時間がかかることが多いです(筆者の経験より
- 起動しなかった場合の状態把握(インフラ起因?アプリ起因?)
- スケールアウトした場合の発生時刻や原因調査
ECSのイベントを知ることで、よりECSの運用に対するハードルを下げることができます
ECSのライフサイクルについて
ECSのサービスやタスクの見える化EventBridgeを活用し、ECSイベントを取得できるようにします。
具体的には、以下の4つ状態変化イベントについて知ることが出来ます。
| No | イベント名 | 説明 |
|---|---|---|
| 1 | コンテナインスタンス状態変更イベント | コンテナインスタンスの起動・停止やタスク停止によるインスタンスのリソース変化など |
| 2 | タスク状態変更イベント | タスクの状態変化(PENDING から RUNNING または RUNNING から STOPPED) |
| 3 | サービスアクションイベント | サービスのレベルをINFO(正常な状態)、WARN(サービスがタスクの起動に失敗する状態)、ERROR(サービスがタスクの配置に失敗する状態) で分類 |
| 4 | サービス展開状態変更イベント | サービスがアプリをデプロイするときに発生する状態変化(デプロイの成功や失敗)で分類 |
具体的な手順
こちらを参考に進めました。
Terraformでは以下のリソースを用意
当初2つを用意したのですが、イベントブリッジのイベントが全てFailedとなり、ライフサイクルイベントが取得できておりませんでした。
再度ドキュメントを確認したところ、以下のリソースを追加したところ、ライフサイクルイベントを取得することができるようになりました!
まとめ
- クラウドベンダのマネージドが多いことは運用者にとっての負担軽減につながる一方、状態の把握が難しい時がある
- ECSライフサイクルを活用することで、マネージドなコンテナサービスでも状態を見える化できることで、障害発生時や高負荷時における原因切り分けが容易になるため、ぜひ設定はしておきたい
皆様のコンテナライフのお役に立てば幸いです!!