OpenKEというオープンソースのフレームワークを用いて知識グラフ補完を行いました。
自分用のメモとして、その結果を文字に起こしておこうと思います。
記事の流れ
本記事の対象
以下のいずれかに該当する人が本記事の対象となります。
- 知識グラフについて興味がある人
- pythonでできることを知りたい人
- OpenKEを使ってみたい人
知識グラフとは
知識グラフは様々な知識の繋がりを構造として表したものになります。
例)
(obama, born-in, Hawaii)
のような主語(subject), 関係(the form of relations), 目的語(object)の関係をもつデータを知識グラフと言います。
主語(subject), 関係(the form of relations), 目的語(object)それぞれを$s, r, o$とおいた場合、$s$ と $r$ もしくは $o$ と $r$ の関係から残った $o, s$ を推測することが今回の目的となります。
OpenKEとは
OpenKEは欢迎来到清华大学自然语言处理与社会人文计算实验室(THUNLP)が作成したオープンソースのフレームワークです。
C++とpythonで作成されている知識グラフ専用のフレームワークで、現在はpytorchとtensorflowに対応しているようです。
詳しくは以下のgithubのリンクもしくはOpenKEのホームページを参照してください。
OpenKEのホームページ
OpenKEのgithub
使用するプログラム
次に実際に実行するプログラムを以下に示します。
今回はexamples内のtrain_distmult_WN18.pyを用います。
import openke
from openke.config import Trainer, Tester
from openke.module.model import DistMult
from openke.module.loss import SoftplusLoss
from openke.module.strategy import NegativeSampling
from openke.data import TrainDataLoader, TestDataLoader
# dataloader for training
train_dataloader = TrainDataLoader(
in_path = "./benchmarks/WN18RR/",
nbatches = 100,
threads = 8,
sampling_mode = "normal",
bern_flag = 1,
filter_flag = 1,
neg_ent = 25,
neg_rel = 0
)
# dataloader for test
test_dataloader = TestDataLoader("./benchmarks/WN18RR/", "link")
# define the model
distmult = DistMult(
ent_tot = train_dataloader.get_ent_tot(),
rel_tot = train_dataloader.get_rel_tot(),
dim = 200
)
# define the loss function
model = NegativeSampling(
model = distmult,
loss = SoftplusLoss(),
batch_size = train_dataloader.get_batch_size(),
regul_rate = 1.0
)
# train the model
trainer = Trainer(model = model, data_loader = train_dataloader, train_times = 2000, alpha = 0.5, use_gpu = True, opt_method = "adagrad")
trainer.run()
distmult.save_checkpoint('./checkpoint/distmult.ckpt')
# test the model
distmult.load_checkpoint('./checkpoint/distmult.ckpt')
tester = Tester(model = distmult, data_loader = test_dataloader, use_gpu = True)
tester.run_link_prediction(type_constrain = False)
test_dataloaderは"./benchmarks/WN18RR/"
modelはdistmult
loss関数はSoftplusLoss()
にしておきます。
dimは200という形に設定されています。
全て、ダウンロードした時の値そのままです。
examples内に他にも複数種類の実行プログラムがあります。
設定に関して
データセット、モデル、ロスの3つが変更できる部分がになります。
train_dataloaderとtest_dataloaderの"./benchmarks/WN18RR/"は同じものにしてください。
このbenchmarksには以下のリンク内のデータセットを使用できます。
benchmarks
TrainDataLoaderの中の変数は自由に変えることができます。sampling_modeにはnomalの他にcrossが選択できます。(cross設定はより深い設定を少し変えないといけない場合があります。)
モデルは以下のリンクを参照していただければと思います。
使用可能モデル
ロスにはSoftplusLossの他にMarginLossとSigmoidLossを用いることができます。
実行結果
実行結果は以下のようになりました。私はGPUマシンを持っていないためgoogle colaboratoryで実行しました。
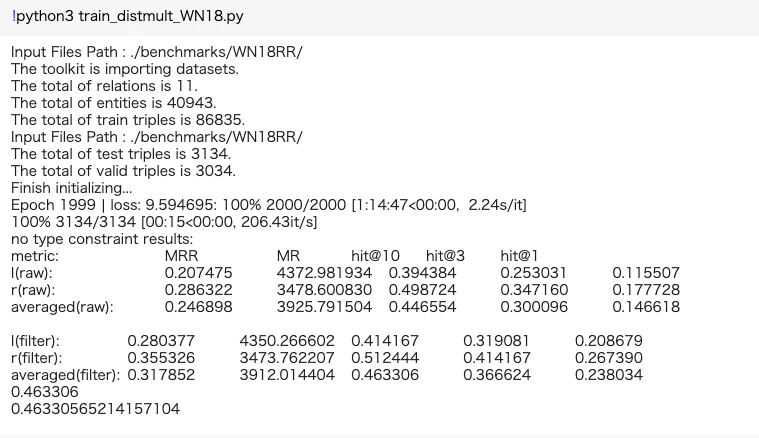
GitHubとの比較・評価
GitHubにあるExperimentsの表と比較していきます。表はHits@10(filter)の時の値のようです。
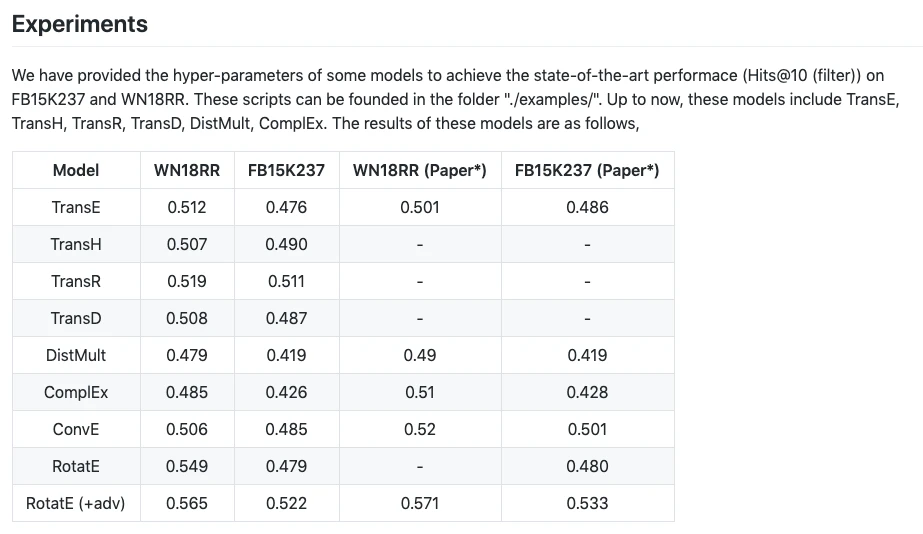
実験結果では平均0.463306となったので精度はGitHubにあるDistMultの値より0.015ほど低くなってしまいました。
改善点としては、他のloss関数を採用するということが挙げられます。
また、neg_entやneg_rel, alphaの値を変化させてみるというのも一つの手だと思います。
まとめ
今回はOpenKEを用いて知識グラフ補完を行ってみました。
結果としては期待する結果を得ることはできませんでしたが、改善の余地がみられたため上記で示した改善点に着手していければと考えています。
最後まで読んでいただきありがとうございました。