以下の記事は3年前に作ったものですが、アカウントを移動したので記事もこちらに移しておきます。
2020年3月現在、新型コロナウイルスをめぐる報道が各メディアでけたたましく喧伝されるようになって久しく、TVのワイドショーや報道番組では、もはやそれ以外の話題のニュースが扱われることの方が珍しいという、はっきり言って異常な状況が続いています。
巷では「コロナのせいでまたイベントが中止になった」「コロナもうマヂ無理。。。」などとフレンドリーにコロナと略して呼ばれているようですが……コロナって太陽の周りのガス層のことですよね?
ラテン語で王冠を意味する言葉がコロナであり、このウイルスの見た目が王冠のように見えることからコロナウイルスと呼ばれています。太陽のコロナも、この「王冠」に由来しています。(crown=”corona”)
王冠に形が似ていることからそれに肖ってコロナの名が冠されたのだから、コロナウイルスのような人類の身体を蝕む病原体には律義に「コロナウイルス」とウイルスを付けて呼ばないとさすがに王様に失礼ではないでしょうか?
驚異的な感染力の病気を恐れるのは間違いではないのですが、その一方で何故かトイレットペーパーやティッシュペーパーが買い占められ品薄になるなど、過剰な恐怖感のアジテーションなのではないかという見方もあります。
私は普段、ITに関する勉強をしているのですが、AI技術を使って身近な課題に対する解決策を提起する方法を考える機会がありました。
ここでは、「Weka」というニュージーランドのワイカト大学が開発した機械学習ソフトウェアを使って、被験者の発言の信憑性の判定という観点から、人のグループを効率よく仕分けるものを作成しました。簡単に言うと、ウソ発見器のようなものです。
機械学習というのはAIという幅広い概念の中の一分野で、膨大なデータからパターンを抽出して分析する手法を表す言葉です。
人工知能と聞くと一般的には「仮面ライダーゼロワン」のヒューマギア(人工知能搭載人型ロボ)や「スターウォーズ」のC-3POのような人型ロボットを連想する人が多いと思うのですが、そのようなAIは「汎用人工知能」と呼ばれ未だ創作の中のキャラクターしか存在せず、実際の社会ではそのようなロボットは実現していません。(実在する中ではPepperくんがそれに近いと言われています)
つまり、現在の技術ではAIというと将棋や自動運転など「特化型人工知能」という限定的な問題解決を行うものを指すことになります。
ちなみにいうと、AI技術というのは人間の知能に近い動作をする機械を作るものであって、ウイルスそのものを検知するような医用生体工学の分野とは異なります。
私が作ったものは元々大学で2月初頭頃に取り組んだものだったのですが、予想外に評価が良かったので、公開することにしました。
以下、その内容です。
■課題の定義
中国・湖北省の武漢市を中心に発生した新型コロナウイルスの感染拡大による肺炎の流行が現在、深刻化し、WHOが緊急事態宣言を発表する事態となっている。
いかにしてパンデミックを食い止めるべきか?と私は考えた。
この感染がなぜここまで拡大したかというと、航空機技術の発展によって海を越えた異国間の行き来が極めて楽になったことの功罪であるのだが、中国において旧暦の正月に当たる「春節」が1月25日であり、大型連休がウイルスの流行時期と重なり、武漢から日本へ訪れる中国人観光客が増加していた。
ここで、仮に中国人の観光客グループによる日本のバスツアー参加者が10名いる状況を想定する。
ウイルスの感染拡大を防ぐためには、乗客が中国のどの地域から来たのかを正確に把握していることが重要となるが、これだけウイルスの発生源に関する報道がなされている中で、武漢から来た乗客が「武漢から来た」ということを正直に言うことは憚られるため、虚偽の申告を行う可能性がある。
そこで、その発言が本当なのか、将又嘘なのか、真偽の当たりを付けて予想するため、どこから来たのか、ではなく他の質問でまずデータを集め、そのデータとあらかじめ収集していた武漢在住の中国人のデータ、および武漢でない都市に住む中国人のデータを比較する。
■解決法と解決の過程と結果の説明、入出力データ
課題の解決法として、Wekaによる決定木を用いる。
sex, age, income, cuisine, Wuhanの5つのattribute(性別、年齢、年収(万円)、好きな中国料理、武漢在住か、の5つの属性)を武漢在住の者を含む中国人に聞き、学習データとして用意し、Wekaを用いて決定木として学習する。年収は通貨を元とした方が良いかもしれないが、ここでは分かりやすさのためにあえて円を通貨とする。
バスツアーの参加者にも同様に、Wuhanを除く4つのattributeを聞いた後に、最後に「武漢から来たか?」の質問に対してyesとnoの2種類で答えさせ、その答えを学習結果を用いてデータの精度を評価する。
30名分のラーニング(学習データ)を、次のtable 1のように用意した。
table 1 data(Learning)
|
number |
sex |
age |
income |
cuisine |
Wuhan |
|
1 |
male |
62 |
700 |
doupi |
yes |
|
2 |
female |
71 |
0 |
dumpling |
yes |
|
3 |
male |
42 |
600 |
ramen |
yes |
|
4 |
female |
20 |
300 |
doupi |
yes |
|
5 |
female |
29 |
500 |
fried rice |
yes |
|
6 |
male |
25 |
400 |
doupi |
yes |
|
7 |
female |
36 |
500 |
doupi |
yes |
|
8 |
male |
27 |
600 |
mapo tofu |
yes |
|
9 |
male |
26 |
500 |
fried rice |
yes |
|
10 |
female |
21 |
300 |
doupi |
yes |
|
11 |
female |
38 |
600 |
mapo tofu |
yes |
|
12 |
female |
35 |
0 |
doupi |
yes |
|
13 |
male |
80 |
0 |
doupi |
yes |
|
14 |
female |
28 |
400 |
ramen |
yes |
|
15 |
male |
33 |
400 |
doupi |
yes |
|
16 |
female |
34 |
500 |
dumpling |
no |
|
17 |
male |
59 |
1000 |
fried rice |
no |
|
18 |
male |
65 |
0 |
ramen |
no |
|
19 |
male |
62 |
600 |
dumpling |
no |
|
20 |
male |
63 |
600 |
mapo tofu |
no |
|
21 |
female |
33 |
0 |
dumpling |
no |
|
22 |
female |
46 |
0 |
dumpling |
no |
|
23 |
female |
20 |
200 |
fried rice |
no |
|
24 |
female |
76 |
0 |
mapo tofu |
no |
|
25 |
female |
22 |
300 |
dumpling |
no |
|
26 |
male |
75 |
0 |
ramen |
no |
|
27 |
female |
63 |
0 |
ramen |
no |
|
28 |
female |
46 |
600 |
fried rice |
no |
|
29 |
male |
68 |
0 |
mapo tofu |
no |
|
30 |
female |
62 |
800 |
mapo tofu |
no |
この表のデータをWekaで読み取れるようにしたファイルquestion.arffは、以下のようになった。
@relation question
@attribute sex {male, female}
@attribute age numeric
@attribute income numeric
@attribute cuisine {doupi, dumpling, ramen, friedRice, mapoTofu}
@attribute Wuhan {yes, no}
@data
male,62,700,doupi,yes
female,71,0,dumpling,yes
male,42,600,ramen,yes
female,20,300,doupi,yes
female,29,500,friedRice,yes
male,25,400,doupi,yes
female,36,500,doupi,yes
male,27,600,mapoTofu,yes
male,26,500,friedRice,yes
female,21,300,doupi,yes
female,38,600,mapoTofu,yes
female,35,0,doupi,yes
male,80,0,doupi,yes
female,28,400,ramen,yes
male,33,400,doupi,yes
female,34,500,dumpling,no
male,59,1000,friedRice,no
male,65,0,ramen,no
male,62,600,dumpling,no
male,63,600,mapoTofu,no
female,33,0,dumpling,no
female,46,0,dumpling,no
female,20,200,friedRice,no
female,76,0,mapoTofu,no
female,22,300,dumpling,no
male,75,0,ramen,no
female,63,0,ramen,no
female,46,600,friedRice,no
male,68,0,mapoTofu,no
female,62,800,mapoTofu,no
そして、このデータのファイルをWekaで開き、Cross-validationの欄には10を入れ、learning methodとしてJ48を選択した。
スタートボタンを押し、ラーニングを開始したときの分類器出力の結果(Classifier output)は、次のようになった。
=== 実行情報 ===
スキーマ:weka.classifiers.trees.J48 -C 0.25 -M 2
データ名: question
インスタンス数:30
属性数:5
sex
age
income
cuisine
Wuhan
テストモード:10-フォールド 交差検証
=== 分類器モデル (学習セット) ===
J48 pruned tree
------------------
cuisine = doupi: yes (8.0)
cuisine = dumpling: no (6.0/1.0)
cuisine = ramen
| income <= 200: no (3.0)
| income > 200: yes (2.0)
cuisine = friedRice
| income <= 500: yes (3.0/1.0)
| income > 500: no (2.0)
cuisine = mapoTofu
| age <= 46: yes (2.0)
| age > 46: no (4.0)
Number of Leaves : 8
Size of the tree : 12
モデルビルド所要時間: 0 秒
=== 階層化交差検証 ===
=== Summary ===
Correctly Classified Instances 20 66.6667 %
Incorrectly Classified Instances 10 33.3333 %
Kappa statistic 0.3333
Mean absolute error 0.305
Root mean squared error 0.4565
Relative absolute error 60.3068 %
Root relative squared error 90.2252 %
Total Number of Instances 30
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.533 0.2 0.727 0.533 0.615 0.776 yes
0.8 0.467 0.632 0.8 0.706 0.776 no
Weighted Avg. 0.667 0.333 0.679 0.667 0.661 0.776
=== Confusion Matrix ===
a b <-- classified as
8 7 | a = yes
3 12 | b = no
Cross-validation tableを見ると、横の各行は実際に「武漢在住であるか?」の質問にyesと答えた人(a)、noと答えた人(b)を表し、縦の各列は武漢在住であると予想した人(a)、武漢在住でないと予想した人(b)を表す。
このデータから、precision=8/(8+3)=0.727, recall=8/(8+7)=0.533, F-Measure = 2*precision*recall / (precision+recall) = 2*0.727*0.533/(0.727+0.533) = 0.615
を得ることができる。
(※precision…精度(「武漢在住である」と予想した人が実際に武漢在住だと答える確率)
recall…再現率(実際に「武漢在住である」と答えた人を武漢在住だと予想する確率)
precisionとrecallはトレードオフの関係にあるため、F-Measureの値が総合的な評価の指標となる)
これを決定木として可視化した結果を出力したものは次のfigure 1のようになった。
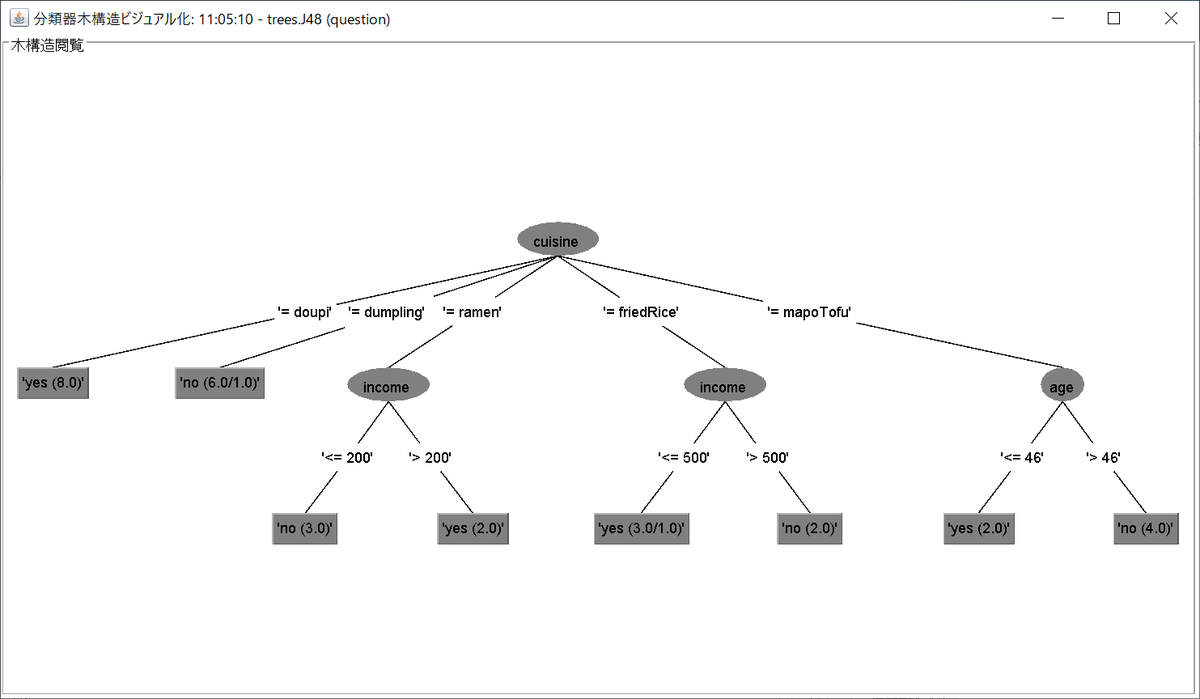
figure1 Decision tree
この結果から、cuisineを始めにして分類することが最も好ましいといえる。
以下、cuisine(好きな中国料理)について、
・doupi(豆皮)と答えた8名のうち、8名全員がyesと答えている。
・dumpling(餃子)と答えた7名のうち、6名はnoと答えている。
・ramen(ラーメン)と答えた5名のうち、income<=200の3名は全員がnoと答え、income>200の2名は両名共にyesと答えている。
・friedRice(炒飯)と答えた6名のうち、income<=500の4名のうち3名はyesと答え、income>500の2名は両名共にnoと答えている。
・mapoTofu(麻婆豆腐)と答えた6名のうち、age<=46の2名はyesと答え、age>46の4名は全員がnoと答えている。
そして、バスツアーの乗客である中国人観光客10名にも同様に質問し、発言の真偽を予想するデータのファイルquestionPredict.arffは次のように用意した。
@relation question
@attribute sex {male, female}
@attribute age numeric
@attribute income numeric
@attribute cuisine {doupi, dumpling, ramen, friedRice, mapoTofu}
@attribute Wuhan {yes, no}
@data
male,29,800,doupi,yes
female,72,0,friedRice,yes
male,78,0,ramen,no
male,62,300,doupi,no
female,68,0,doupi,yes
male,35,900,friedRice,no
female,65,0,mapoTofu,no
male,43,300,doupi,no
male,36,800,dumpling,no
female,57,0,ramen,no
そして、WekaのSupplied test set buttonをクリックし、questionPredict.arffを開き、More optionsをクリックし、Output Predictions boxにチェックを付け、スタートボタンを押して予想を開始した結果は次のようになった。
=== 実行情報 ===
スキーマ:weka.classifiers.trees.J48 -C 0.25 -M 2
データ名: question
インスタンス数:30
属性数:5
sex
age
income
cuisine
Wuhan
テストモード:ユーザー指定テストセット:不明なサイズ(増加読み込み)
=== 分類器モデル (学習セット) ===
J48 pruned tree
------------------
cuisine = doupi: yes (8.0)
cuisine = dumpling: no (6.0/1.0)
cuisine = ramen
| income <= 200: no (3.0)
| income > 200: yes (2.0)
cuisine = friedRice
| income <= 500: yes (3.0/1.0)
| income > 500: no (2.0)
cuisine = mapoTofu
| age <= 46: yes (2.0)
| age > 46: no (4.0)
Number of Leaves : 8
Size of the tree : 12
モデルビルド所要時間: 0 秒
=== 予測テスト分割 ===
inst#, actual, predicted, error, probability distribution
1 1:yes 1:yes *1 0
2 1:yes 1:yes *0.667 0.333
3 2:no 2:no 0 *1
4 2:no 1:yes + *1 0
5 1:yes 1:yes *1 0
6 2:no 2:no 0 *1
7 2:no 2:no 0 *1
8 2:no 1:yes + *1 0
9 2:no 2:no 0.167 *0.833
10 2:no 2:no 0 *1
=== テストセット上で評価 ===
=== Summary ===
Correctly Classified Instances 8 80 %
Incorrectly Classified Instances 2 20 %
Kappa statistic 0.6
Mean absolute error 0.25
Root mean squared error 0.4625
Relative absolute error 50 %
Root relative squared error 92.4962 %
Total Number of Instances 10
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
1 0.286 0.6 1 0.75 0.81 yes
0.714 0 1 0.714 0.833 0.81 no
Weighted Avg. 0.8 0.086 0.88 0.8 0.808 0.81
=== Confusion Matrix ===
a b <-- classified as
3 0 | a = yes
2 5 | b = no
この出力結果から、precision=3/(3+2)=0.6, recall=3/(3+0)=1, F-Measure = 2*precision*recall/(precision+recall) = 2*0.6*1/(0.6+1) = 0.75を得ることができる。
また、Correctly Classified Instancesは80%であり、10名中8名の回答は予想と一致している。
■感想
学習データを決定木を用いて学習し、予測した結果を見ると、全体的に、8割の確率で予想と一致する結果となったことは良い精度であるといえるだろう。
そこで、予想と異なる結果となった2名に着目する。
1人目のデータは、「male,62,300,doupi,no」であり、「男性・62歳・年収300万円・好きな中国料理は豆皮(おこわオムライス)・武漢から来ていない」という回答であるが、
学習データによるとcuisine(好きな中国料理)をdoupi(豆皮)と答えている人は8名中8名全員がWuhanをyesと答えた(武漢在住である)ため、「武漢から来た」と予想する結果は尤度が高いといえる。
そもそも、豆皮とは武漢市において人気のある比較的ローカルな朝食料理のことであるため、この男性が嘘をついているのではないかという疑うことは自然である。
2人目のデータを見てみると、「male,43,300,doupi,no」と、またしても「豆皮が好きと言っているにもかかわらず武漢から来ていない」と答えたことが1人目と一致しており、疑わしさを補強する結果となっている。
このようにして、機械学習において決定木を利用することで人間の発言の真偽の確かさを統計的に分析することができることは、母集団の多い標本を効率的に仕分けるのに役立ち、一見無関係のようにも思える人工知能の技術が医学に大きく貢献するポテンシャルを持っていると言えるだろう。
日本での新型コロナウイルスの感染者が増えている現状は決して無視できず、予防としてこまめな手洗い、適度な運動、マスク着用の徹底、免疫力の強化に励みたい。
【おまけ】新型コロナウイルスの風評被害の影響で伽藍堂と化した横浜中華街へ敢えて足を運ぶと、そこはコロナのコの字も無いいたって平和な場所だった
今回の件で様々なイベントが中止になったり、人が集まる場所への客足が遠のいたり経済にも大きな影響を与えているコロナウイルスですが、とりわけ厳しい経営状況に置かれている場所があります。
「横浜中華街」です。
・発生源が中国の武漢である
・船内で多数の感染者を出したクルーズ船「ダイヤモンド・プリンセス」が横浜港に停泊していた
という風評被害のダブルパンチを喰らい、普段は大勢の人で賑わう場所である中華街が、ガラガラになっているという情報を聞き入れました。
しかし、そこで働いている中国人は最近まで武漢にいたわけではないし、観光客もほとんどが日本人だし、横浜港からは十分な距離が離れているため、人が少ない今、行っても感染する確率はかなり低いというのが筋の通った考え方ではないでしょうか。
そして実際、行ってきました。
その現状を確かめるために。
みなとみらい線の横浜・中華街駅を降りて最初に目についた大きな門の奥を見て、最初に思ったのが「意外と人歩いてるなぁ」ということ。
それでも、数年前に来た時よりは明らかに建物の中が空いていました。
まず、横浜博覧会の開華楼というお店でタピオカドリンクを買いました。
ライチのドリンクの中にカラフルなタピオカが入っておりインスタ映えで人気だそうです。
こんなことを言うのはデリカシーに欠けるとは知りながらも、店員の方に断腸の思いで聞きました。
「今、大変じゃないですか?関係ないことでお客さん減っちゃって…。」
すると店員の方は、「そうですねぇ人少ないですねぇ」と苦笑いして言いました。
他のお店の人も大体同じように答えました。
あらゆる店内にはコロナのコの字も書かれておらず、平常通りに接客する優しい店員さんばかりでした。
その後複数の店で買い物をしていて気づいたのですが、今、中華街ではほとんどの店舗がPayPayに対応しているため、実際に現金に触れる必要がありません。
なので、接触による感染のリスクという面で見ても、人が少ないという面で見ても、今行ってみるのは逆にお勧めできるのではないでしょうか。
午前中には売り切れてしまうという「幻のちまき」も割と楽に変えると思います!多分!