はじめに
その計算、AiiDAで自動化してみませんか?
この連載では、第一原理計算などの計算科学の分野で注目されはじめているツール「AiiDA」について解説していきます。
AiiDAは、 複雑な計算ワークフローの自動化やデータ管理、再現性の確保をサポートしてくれる頼もしいツールです。
これから計算に挑戦しようという初心者の方も、スクリプトを書いてガンガン計算を回してしているヘビーユーザーの方も、ぜひ一度チェックしてみてください!
今回は第1回ということで、AiiDAの全体像についてざっくりと解説します。
とりあえずチュートリアル的に使ってみたい、という方は『(その2)AiiDAを使ってみよう』から先に見ていただくのもよいでしょう。
こんな方におすすめ
- ハイスループット計算をやってみたい方
- 計算データの管理やデータベース化にお悩みの方
- 計算データを公開したい方
- 未経験の計算手法を手軽にお試ししたい方
- 機械学習フローにシミュレーションを組み込みたい方
- 自作の計算手法を普及したい方(手法開発者)
- 計算課題を持っているけれど、計算コードの使い方には自信が無い方(特に、これから計算をしたい実験の方)
- etc.
AiiDAって何?
AiiDA(Automated Interactive Infrastructure and Database for Computational Science)は、計算ワークフローとデータ管理を自動化してくれるPythonベースのインフラストラクチャです。
EPFL (スイス) と Bosch (米国) を中心としたグループによって共同開発され、MITライセンスで利用可能なオープンソースソフトウェアとしてGitHubで公開されています。
現時点(2025年2月)では、AiiDAはまだ成熟段階にあるとはいえ、上記GitHubや掲示板を中心に非常に活発なコミュニティが形成されています。
ユーザからのフィードバックや改善提案がリアルタイムで共有されており、質問もしやすい環境が整っている点が他の類似ツールにはないAiiDAの大きな魅力です。
AiiDAが提供する機能の全容は後で説明しますが、ざっくりいうと「人間の代わりに計算を自動で実行し、かつ各ステップを追跡してデータベースに記録してくれる、Pythonで手軽に動かせる便利ツール」だと思ってください。
経験者向けに書くと、データベースとのやりとりやリモート計算機の監視、実行中の計算の非同期制御といった機能を一通り提供してくれるライブラリです。
なぜ計算を自動化するの?
計算を自動実行できるようになると、単に計算担当者が楽をできるという以上の効能があります。
自動計算の真価のひとつは何といってもハイスループット計算でしょう。
ハイスループット計算とは、膨大な量の計算を自動で実行して大量のデータを収集する手法のことです。
例えば、複数の計算条件で並列に計算を走らせることで網羅的な評価を行ったり、計算データを大量に生成して機械学習に使うことができたりします。
このような計算では、計算結果のデータベース化や計算リソースの管理、エラー処理など、規模が大きくなると手動では扱いきれない部分が増えてくるため、AiiDAのようなワークフロー管理ツールが非常に重宝されます。
自動計算のもうひとつの利点は、計算の再現性にあります。
ワークフローを自動化しておけば、どのような複雑な手続きが必要な計算手法であっても再現が可能です。
これはつまり、計算のいわば ”お手本” を共有できるということを意味しており、計算手法の開発者にとっては提案手法を普及する助けになりますし、計算実務者にとっては新しい計算コードや計算手法を導入する際のハードルを下げてくれます。
AiiDAのエコシステムを活用することで、自動実行可能な計算ワークフローを簡単に、ユーザ同士が共有しやすい形式で作成・利用することができます。
なぜAiiDAを使うのか?
では、AiiDAを使うと何が嬉しいのでしょうか?先に結論から言っておくと、AiiDAには
- 計算の管理を単一のシステムに集約できる
- 操作がPythonインタフェースで完結する
- 計算ワークフロー(論理構造)と実行環境を分離できる
という利点があります。
このことを、次のような図を使いながら説明していきます。
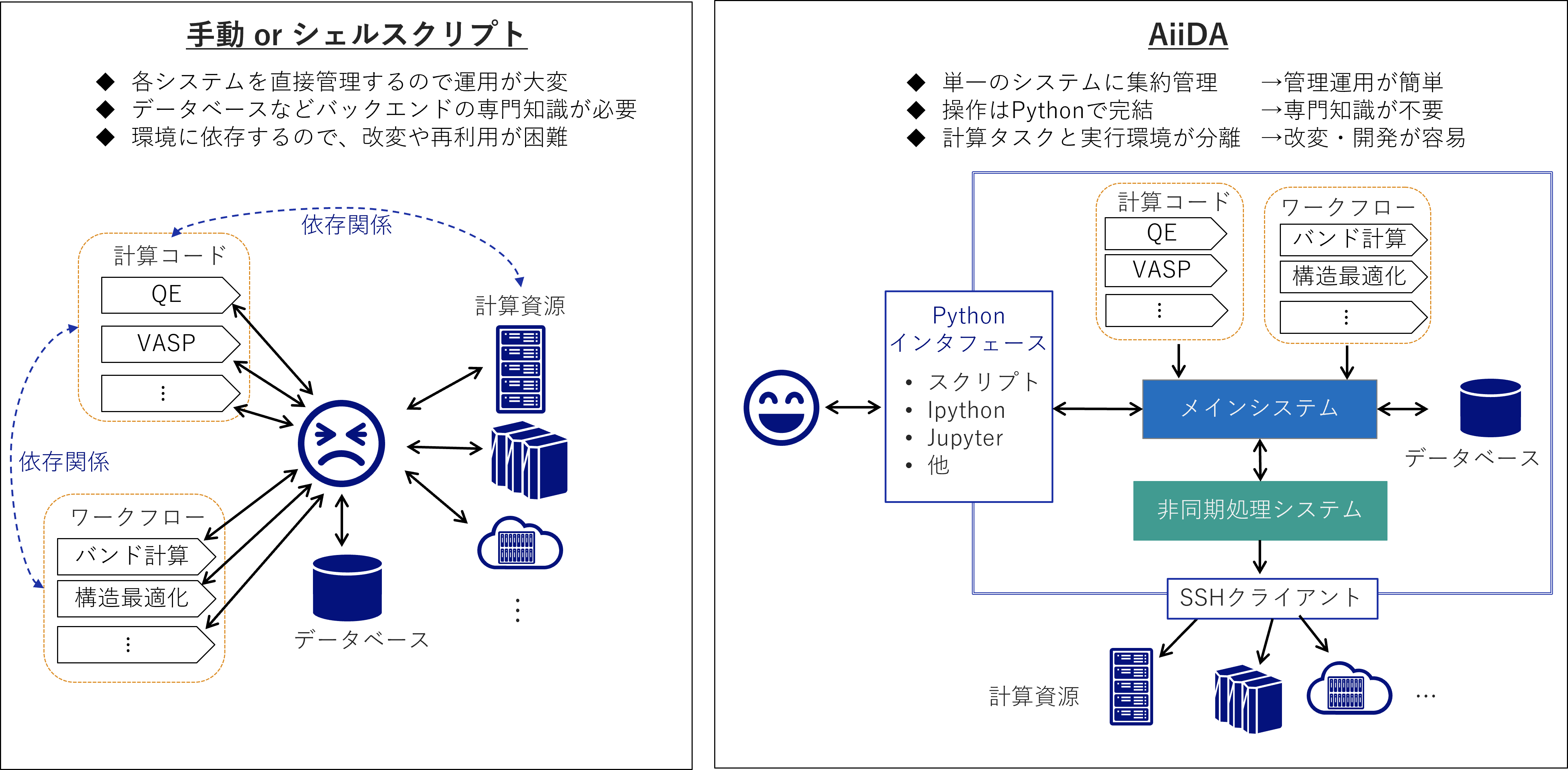
ハイスループット計算ワークフローを手動で管理する場合(左図)とAiiDAで管理する場合(右図)を比較してみましょう。
計算の管理を単一のシステムに集約できる
手動の場合、各計算コードやワークフロー、計算資源をバラバラに扱うことになりがちで、あっという間に手に負えなくなります。
慣れている方だとシェルスクリプトで一括処理するところかと思いますが、大規模なハイスループット計算を行う場合にはそれなりに高度な制御機構を作りこむ必要が出てきます。
AiiDAを使うと、計算処理を全てAiiDAのメインシステムに集約して管理することができ、運用コストが大幅に減ります。
操作がPythonインタフェースで完結する
手動の場合だと計算結果をデータベース化するためにSQLデータベースの運用が必要だったり、計算を制御するために非同期処理が必要だったりと、情報システムまわりの知識と経験が要求されます。
AiiDAではこれらの操作は全てバックエンドで処理されるので、高度な専門知識が無くてもSQLデータベースや非同期処理システムの便利な機能を享受できます。
Pythonインタフェースを完備しているため、ユーザはPythonだけ習得していればすぐにハイスループット計算を始められます。
計算ワークフロー(論理構造)と実行環境を分離できる
この手のシステムを自作すると、よほど気を付けて設計しない限りは環境に依存してしまい、特定のマシン、計算コード、計算ワークフローでしか動かないものになってしまいがちです。
このことは、システムを別の環境に移植したり、計算ワークフローを他のユーザと共有したりする際の妨げとなります。
AiiDAは高度な抽象化機能を備えており、計算タスクと実行環境を分離して管理しています。これにより、異なる計算環境に移行しても同じワークフローの再利用が可能となっています。
シェルスクリプトユーザ向けの補足
大規模化するとどのように大変になっていくのか、簡単な例を考えてみましょう。ある第一原理計算コードを使って「構造最適化→バンド計算」というワークフローを実行するハイスループット計算プロジェクトがあったとします。
これをシェルスクリプトで実装しようとすると、素朴には (1) 構造最適化計算のジョブを投げる、(2) 構造最適化計算が終わっているか出力ファイルから判別、(3) 計算終了しているものについてバンド計算のジョブを投げる、という処理を書くことになるかと思います。ここまではいいでしょう。
では、次にこれらの計算ジョブを複数の計算資源(ワークステーション、共用施設のスパコン、クラウドHPC環境、etc.)に分散して実行する場合を考えます。
一般には使う計算機ごとにジョブ管理システムが異なるため、上記の処理の実行コマンド部分を計算機ごとに分岐する必要が生じます。
また計算コードについても、サポートされているビルドのバージョンが異なると、出力フォーマットが変わってしまい(2)のステップで躓く可能性があります。こちらも計算機ごとに出力パーサーを用意して分岐処理する必要があります。
このように、計算資源とコード、ワークフローは互いに依存関係にあるので、使用する計算資源が増えてくると、管理スクリプトは組み合わせで複雑になっていくおそれがあります。
ここでさらに、いま走っているプロジェクトと並列して別プロジェクトを開始することになった場合を想像してみましょう。(ハイスループット計算プロジェクトは通常長期間にわたるため、こういった状況は頻繁に起こり得ます。)
同じ計算資源を共有する場合、新しいプロジェクト用のスクリプトを用意するだけでは済まず、走っている最中のプロジェクトのスクリプトを修正して新プロジェクトと排他的になるよう気を配る必要があります。言うまでもなく大変な作業です。
このように、簡単なワークフローでさえもプロジェクトの規模が大きくなると途端に管理が大変になってゆくのです。
AiiDAの強み
計算科学は、科学における自然探求の手法であると同時に、技術としての側面も持ちます。
したがって計算科学者もまた、専門分野に関する知見に加えてある程度の情報処理技術に習熟している必要があります。
AiiDAはそのうち情報システムの扱いに係る大部分を担ってくれるツールといえるでしょう。
計算科学者は最低限Pythonに関する知識さえあればよく、自身の計算課題について高度なワークフロー制御を行うことができます。
ここで、「他にも同じことができるワークフローツールはあるんじゃないの?」と思われた方もいるでしょう。
答えはイエスです。ではなぜあえてAiiDAを使うのかというと、ひとえにこの手のワークフローツールの中ではコミュニティが一番活発だからという点に尽きます。
公式GitHubリポジトリ を見ると、本記事執筆時点(2025年3月)で200人を超えるユーザがおり、約100人のコントリビュータによる定期的なコミットや活発なイシュー・プルリクエストのやりとりが確認できます。
このように活発なコミュニティに支えられ、持続的に進化しているという点は、類似ツールの中からAiiDAを選択する強いインセンティブになり得ると考えています。
AiiDAの基本機能のより詳細な紹介
ここまでは使い方にフォーカスした説明をしてきましたが、ここでAiiDAが有する機能についてより具体的に見てみましょう。AiiDAは、計算科学におけるハイスループット計算を支えるために、以下の4つの主要な機能を提供しています。これらの機能が連携することで、計算ワークフローの自動化からデータ共有まで、研究プロジェクト全体を効率的に管理できるようになっています。
1. 自動化
高度な計算ワークフロー自動化機能を有しています。
- 再現性と追跡性の確保: 計算の各ステップやその入出力データが自動的にデータベースに記録されるため、いつでも同じ条件で再現することが可能です。
- 抽象化されたワークフロー: 実際の実行環境からワークフローを分離することで、どの環境でも同一のAPIで操作でき、計算環境の違いを気にする必要がありません。
- 高度な非同期処理: 分岐や繰返し処理、エラー発生時のハンドリングなど、柔軟なワークフロー制御が可能になっています。
2. データ管理
計算によって生み出される膨大なデータを効率的に扱える機能を備えています。
- 関係データベース(RDB)利用: 計算結果はRDBに保存され、SQLクエリで高度な検索が行えます。
- 因果関係の記録: 全てのデータと計算プロセスを因果関係(入出力関係)で紐づけて保存するため、計算の追跡や検索が効率的に行えます。
- 柔軟なデータ保存: 必要なデータだけを選んで保存することで、効率的にストレージを利用できます。
3. 開発・運用環境
AiiDAは、Pythonインタフェースを完備しているため、ユーザフレンドリーな開発・運用環境を提供します。
- Pythonエコシステムの活用: 仮想環境やパッケージ管理ツール、テストフレームワークなど、Pythonの豊富なツール群をそのまま利用可能です。
- 対話型インターフェース: IPythonシェルやJupyter Notebookなど、多彩な環境でワークフローの開発や実行ができます。
- 低い学習コスト: Pythonさえ習得していれば、複雑なワークフローでも直感的に操作できます。
4. 共有
最後に、AiiDAは研究成果や計算データの共有を容易にする仕組みを備えています。
- インポート/エクスポート機能: データベースに保存された計算データは、他のユーザと簡単に共有可能です。
- Webベースのデータ共有: JupyterウィジェットおよびJupyterHubを活用することでWeb上でデータの閲覧や共有ができます。また、Materials Cloud ArxiveなどAiiDAに対応している公開データベースもあります。
- プラグインによる拡張: AiiDAの機能は、プラグインとしてPythonパッケージ化されているため、他のユーザが作成した計算ワークフローも手軽に取り入れられます。
AiiDAシステムの概観
最後に、AiiDAがどのように構成されているか、システムの全体像を俯瞰してみましょう。
バックエンドの話になるので、「とにかく使い勝手を試してみたい」という方は飛ばして『(その2)AiiDAを使ってみよう』に進んでいただいても問題ありません。
AiiDAのシステムは下の図のようになっています。
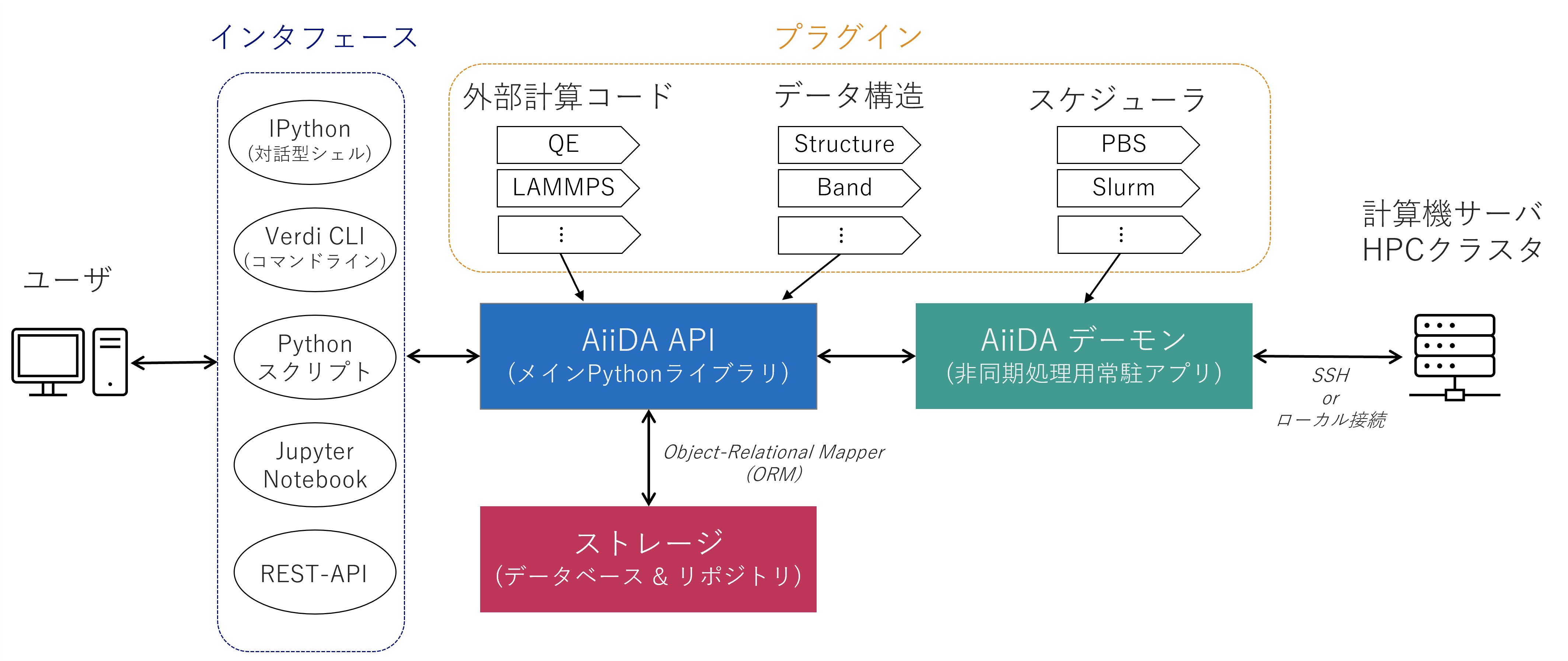
大きく分けて、次の5つの要素から構成されています:
1. AiiDA API
AiiDAのAPIはすべてPythonクラスとして実装されており、システムの中核を担っています。
メインプログラムの主要な役割は、Object-Relational Mapper (ORM) と呼ばれる、Pythonオブジェクトをデータベースに読み書きするためのインタフェース機能です。
ORMのおかげでユーザはSQL文を書くことなく、Pythonの文法で 関係データベース (RDB) の機能を利用することが可能になります。
2. ストレージ
AiiDAのストレージは、以下の2つの主要部分から成り立っています。
- データベース: 計算結果やワークフローのメタデータはリレーショナルデータベースに保存され、SQLクエリを用いて高速な検索が可能です。
- リポジトリ: ファイルやフォルダなど、大容量データの管理に特化しており、データベースと連携して効率的に保存されます。
3. AiiDAデーモン
ハイスループット計算の実現には、非同期的な計算プロセス管理が欠かせません。
これを実現するのが デーモン (常駐アプリケーション)です。
デーモンは各計算プロセスの進捗を監視し、プロセスの進行状況に応じて制御命令やデータの収集を行います。
リモート計算資源もSSH接続を用いて監視します。
4. プラグインシステム
AiiDAは プラグイン による機能拡張をサポートしており、コアプログラムを変更することなくユーザ側での機能の拡張ができます。
プラグインはPythonパッケージとして提供されており、通常のPythonパッケージを扱う感覚で使用・公開できます。
公式のプラグインレジストリ には様々なプラグインがあらかじめ用意されているので、ぜひ一度覗いてみて下さい。
5. インタフェース
ユーザはPythonが備える多彩なインタフェースをそのままAiiDAの操作に使用できます。
- コマンドライン
- 対話型シェル (IPython)
- ノートブック (JupyterNotebook)
- 他、Webブラウザ (RESTful API) など
これらの要素が一体となることで、AiiDAは高度な計算ワークフロー管理機能と柔軟性、そして操作性を両立しているのです。
まとめ
これまで、AiiDAがどのように計算科学の現場でハイスループット計算を支援し、複雑なワークフローの自動化とデータ管理を実現しているかについてご紹介しました。
以下のポイントで、AiiDAの特徴を改めて振り返ってみましょう:
-
ワークフロー自動化ツール:
AiiDAは計算科学における計算ワークフロー自動化を支援するためのオープンソースのPythonライブラリです。 -
統合されたシステム構成:
PythonベースのAPI、リレーショナルデータベース、専用のデーモン、プラグイン機構、そして豊富なインタフェースが一体となって、高い機能性と柔軟性、操作性を実現しています。 -
活発な開発・共有環境:
活発なコミュニティ活動により頻繁にメンテナンスが行われ、信頼性の高いインフラが提供されています。
AiiDAは、初心者からヘビーユーザーまで幅広い計算自動化のニーズに応えるための強力なツールです。次回『(その2)AiiDAを使ってみよう』では簡単なチュートリアルを行ってみたいと思いますので、気になった方は是非とも試しに使ってみて下さい。
質問・コメント等お気軽にどうぞ!
参考文献
この記事の執筆においては、AiiDAの公式ドキュメント、および次の論文を参考にしました。
- Pizzi, Giovanni, et al., "AiiDA: automated interactive infrastructure and database for computational science", Computational Materials Science 111, 218-230 (2016).
また、現行版のAiiDAの実装は以下の文献にまとめられておいるので、AiiDAを使用して得た成果を発表する際には、以下の論文を引用することが推奨されています:
-
S. P. Huber, et al., "AiiDA 1.0, a scalable computational infrastructure for automated reproducible workflows and data provenance", Scientific Data 7, 300 (2020),
-
Martin Uhrin, et al., "Workflows in AiiDA: Engineering a high-throughput, event-based engine for robust and modular computational workflows", Computational Materials Science 187, 110086 (2021).