みなさん、今年ももう終わりです。1年早いですね。
今回はチュートリアル形式でNode.jsとサーバレスを体験していただきたいなと思っています。
初心者の方にもとっつきやすく、目に見えるフィードバックがあるのでモチベーションも続きやすいと思います。
対象の読者
- 面倒なので5分で試したい (大事)
- プログラミングやったことあるけど、もっと踏み込んだものを作りたい
- そもそもJavaScript触ったことない
- JavaScriptを触ったことがあるけどそこまで深く知らない
- asyncとawaitってなに?
- API作ってみたい
- 無料がいい
- サーバレスって聞いたことあるけど触ったことない or メリットがわからない
使うもの
APIが動作環境 -> Zeit NOW
スクレイピング -> Puppeteer
なんでこの構成にしたか
- 僕がPython触ったことがなく、Selenium触るのがちょっとめんどうだった。(JSはある程度触れる)
- スクレイピングは、割とオンデマンドな面があると思っていて、要求があった時に対象のWebサイトの情報を引っ張ってきて返せばいい -> このことからサーバレスとの相性が良いと思ったため。(必要ないときはサーバが立ち上がらない) ※デメリットとしては、APIがコールされる度にPuppeteerが起動するため、その時間がかかってしまうという点がありますがご愛嬌。
- デプロイがめっちゃ楽
Puppeteerについて
Puppeteerの使い方は、Qiitaの他の記事で細かいところまで書いているので、本記事では割愛します🙏
レンダリング済みのページを取得できるため、JavaScriptが動作するページでもそれが反映されている状態でスクレイピングすることができます。
Puppeteerはかなり柔軟な設定ができます。
https://github.com/puppeteer/puppeteer/blob/master/docs/api.md
やってみる(お試し)
やっておくこと: ZEIT(now) に登録しておいてください。
https://now.sh
パッケージ管理はyarnに統一します。
- 適当なディレクトリを作成し、
yarn add nowします。(nowをインストールします) - とりあえず、テスト用のレスポンスを返すファイルを作成してみます。
module.exports = async (req, res) => {
res.end('Hello world')
}
- nowの設定ファイル(now.json)を作成します。
ここでは、全てのリクエストを
index.jsに流すようにします。
{
"version": 2,
"builds": [{ "src": "index.js", "use": "@now/node" }],
"routes": [{ "src": "(.*)", "dest": "index.js" }]
}
この時点で動作させることができます。
yarn now devでローカルで起動できます。nowにデプロイしてみます。
now loginでログインします。
メールアドレスを求められるので、ZEIT(now)登録時のものを入力します。ログインに成功したら、
yarn nowでサーバにデプロイします。
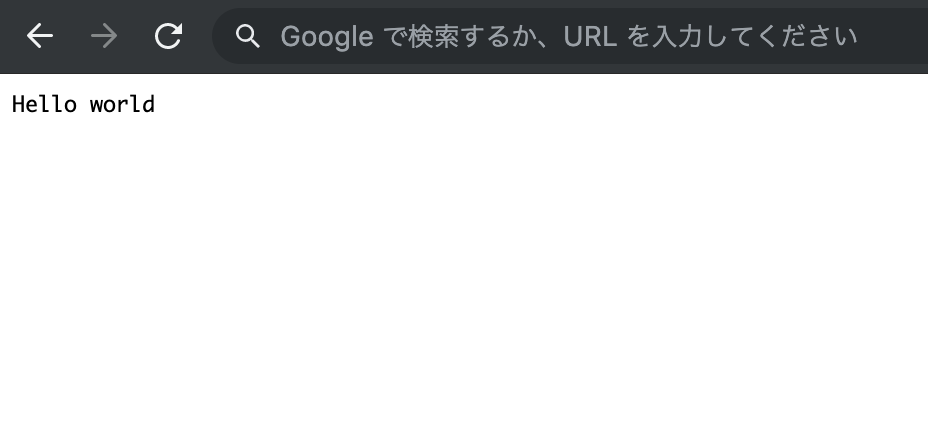
コンソールに、デプロイ後のURLが表示されるので、ブラウザでアクセスします。
Hello worldの文字が表示されていたら成功です。
応用編
サーバレスでPuppeteer起動、スクレイピングして結果を返却するAPIを作成してみたいと思います。
今回は、Qiitaのユーザランキング情報を返却するAPIを作成してみたいと思います。
- Puppeteerが必要になりますが、now上ではそのままPuppeteerが動作しないので、
puppeteer-coreとchrome-aws-lambdaをインストールします。
yarn add puppeteer-core
yarn add chrome-aws-lambda
- 次にスクレイピング & こちらがスクレイピングを行う & APIの本体のソースです。既存のindex.jsを下記のように編集してみます。 30行程度でかけてしまうので、かなり簡単で使いやすいと感じていただけたのではないかと思います。
const chrome = require('chrome-aws-lambda');
const puppeteer = require('puppeteer-core');
const getQiitaHotUser = async () => {
const browser = await puppeteer.launch({
args: chrome.args,
executablePath: await chrome.executablePath,
headless: chrome.headless
});
const page = await browser.newPage();
await page.goto('https://qiita.com/', {waitUntil: "domcontentloaded"});
//検索結果の取得
var items = await page.$$('.ra-User');
const retData = [];
for (let i=0; i< items.length; i++) {
const userName = await items[i].$eval('.ra-User_screenname', el => el.textContent);
const contribCount = await items[i].$eval('.ra-User_contribCount', el => el.textContent);
const profileUrl = await items[i].$eval('a', el => el.href);
retData.push({
userName: userName,
contribCount: contribCount,
profileUrl: profileUrl
});
}
await browser.close();
return retData;
}
module.exports = async (req, res) => {
const data = await getQiitaHotUser();
res.json({data: data });
}
※ このソースはnow.sh上環境でしか動作しません。
- 早速、
yarn nowでnowにデプロイします。 - デプロイが完了すると、コンソール上にエンドポイントが表示されるので叩いてみます。
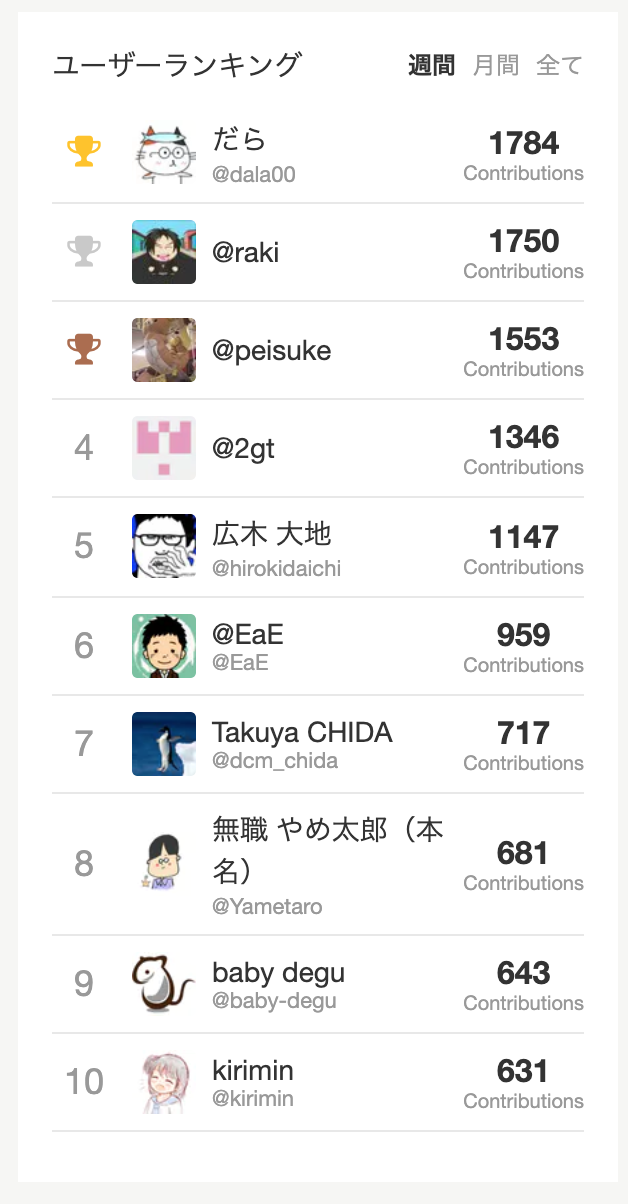
yutaronnoMacBook-Pro:scraping-api yutaron$ curl https://scraping-api.xxxxxx.now.sh
{"data":[{"userName":"@dala00","contribCount":"1784","profileUrl":"https://qiita.com/dala00"},{"userName":"@raki","contribCount":"1750","profileUrl":"https://qiita.com/raki"},{"userName":"@peisuke","contribCount":"1553","profileUrl":"https://qiita.com/peisuke"},{"userName":"@2gt","contribCount":"1346","profileUrl":"https://qiita.com/2gt"},{"userName":"@hirokidaichi","contribCount":"1147","profileUrl":"https://qiita.com/hirokidaichi"},{"userName":"@EaE","contribCount":"959","profileUrl":"https://qiita.com/EaE"},{"userName":"@dcm_chida","contribCount":"717","profileUrl":"https://qiita.com/dcm_chida"},{"userName":"@Yametaro","contribCount":"681","profileUrl":"https://qiita.com/Yametaro"},{"userName":"@baby-degu","contribCount":"643","profileUrl":"https://qiita.com/baby-degu"},{"userName":"@kirimin","contribCount":"631","profileUrl":"https://qiita.com/kirimin"}]}
正常に動作しているようですね💪
まとめ
これまでのチュートリアルで、Node.jsやサーバレスの雰囲気を掴めたと思います。
以前、APIが公開されていないサイトの情報を収集したいなと思ったことがあり、この方法で対応したことから、今回のアドベントカレンダーの題材に選びました。
スクレイピング x API x サーバレスは親和性があるという発見ができたので、個人的には満足しています。
また、Puppeteerは割と高機能なので、いろんな使い方ができます。
CIに組み込んで、フロントエンドのテストに使われたりというのをよく見かけます。
興味が湧いた方はぜひ試してみてください。
参考URL
Puppeteerを使った開発の勘所
https://qiita.com/taminif/items/1ba7f68aedd68bae5e09
puppeteerでの要素の取得方法
https://qiita.com/go_sagawa/items/85f97deab7ccfdce53ea
AWS Lambda Layers上でHeadless Chromeを動かすいくつかの方法
https://qiita.com/tabimoba/items/9ffe4ba6f2af28c702af