概要
前回の記事の続きです。
今回はPandasでもう少し行列データを操作したいと思います。
Pandasでデータ操作
-
まず、Pandasでよく使う用語について記載しておきます。
- Series:1次元配列のことです。
- Data Frame:2次元配列(行列)データのことです。
- Panel:3次元配列データのことです。
- index:行ラベルのことです。
- columns:列のことです。Programingをやられる方にとってはおなじみの用語ですね。
-
用語について、軽く抑えたところで、進めていきたいと思います。
-
前回は、気象庁観測データCSVを読み込んだところまで行きました。その続きでデータ操作を行います。
-
shapeで行列の数を求めることが出来ます。
-
columnsで列名を求めることが出来ます。
print('shape:', df_data_1.shape)
print('columns:', df_data_1.columns)

- 上記で求めたcolumns を指定してデータを出力してみます。
df_data_1[['都道府県', '現在時刻(日)','現在時刻(時)', '現在時刻(分)', '現在値(mm)']]

- 出力する条件を絞ってみましょう。都道府県が東京都のデータに絞ってみます。
- 加工する前に、列名は日本語だと何かと難しいです。しかも、気象庁の天気データCSVは列名に半角括弧なども含まれているので、本格的にデータ操作するのであれば、英語に加工したり、半角括弧は変換するなりした方が良いですね。とりあえず、都道府県列で絞ってみました。
df_data_1[['都道府県', '現在時刻(日)','現在時刻(時)', '現在時刻(分)', '現在値(mm)']].query("都道府県=='東京都'")

- Index(行番号)を指定して検索してみましょう
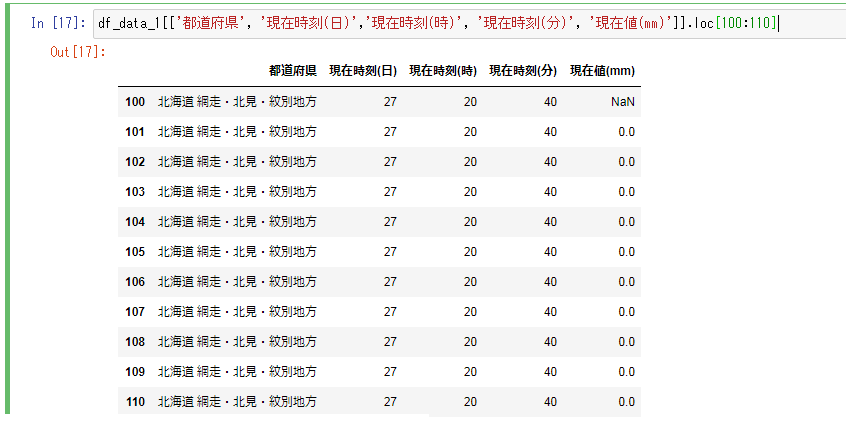
df_data_1[['都道府県', '現在時刻(日)','現在時刻(時)', '現在時刻(分)', '現在値(mm)']].loc[100:110]
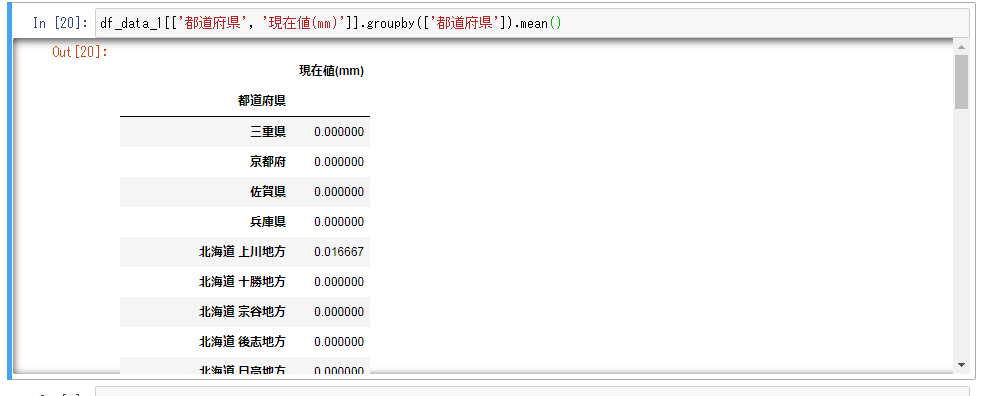
- 都道府県でgroup byして平均を求めてみます。group by した後にmean()で平均を求めています。ちなみにmaxを指定すると、最大値、minを指定すると最小値を求めることが出来ます。
df_data_1[['都道府県', '現在値(mm)']].groupby(['都道府県']).mean()
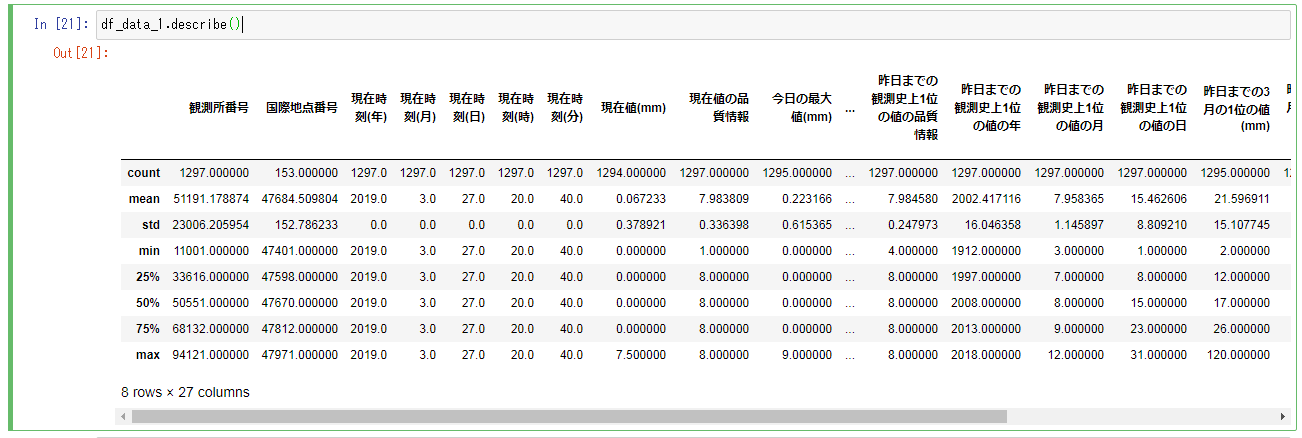
- 要約統計量を取得(全カラム)
df_data_1.describe()
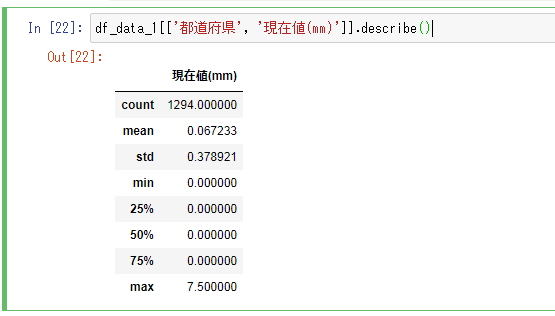
- 都道府県、現在値(mm) で要約統計量を取得してみます。
df_data_1[['都道府県', '現在値(mm)']].describe()
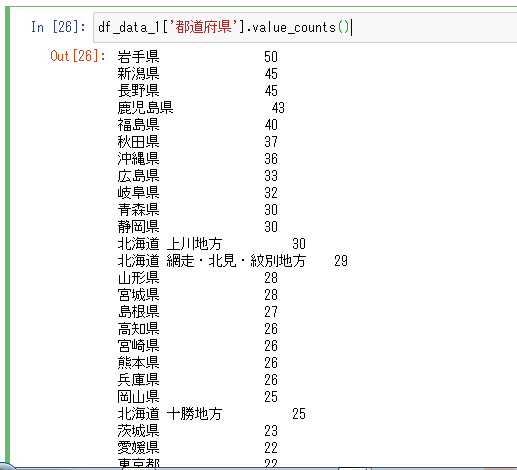
- ユニークの値とその出現回数をカウントしてみます。
df_data_1['都道府県'].value_counts()
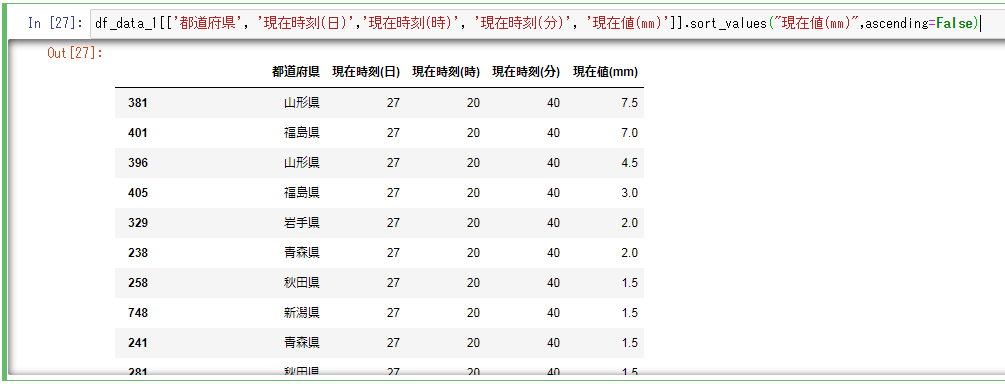
- 必要なカラムを絞って、'現在値(mm)'を降順でソートしてみましょう。sort_valuesでカラムを指定して、ascendingで昇順(True)、降順(False)を指定します。
df_data_1[['都道府県', '現在時刻(日)','現在時刻(時)', '現在時刻(分)', '現在値(mm)']].sort_values("現在値(mm)",ascending=False)
- データ操作が簡単に行えて、面白いですね。きりが無いので紹介はこの辺りまでとしますが、興味がありましたら、この辺りを読んで色々と試してみてください。