概要
- scikit-learnのサイトには、現在(2019.05.02時点)で7種類のToyデータセットが用意されています。
- そのうちの一つ「ボストン住宅価格データセット」を使ってデータ解析してみます。このデータセットはUCI ML住宅データセットを加工したデータです。
ボストン住宅価格データセットの解析
ボストン住宅価格データセットの読み込み
- 戻り値(boston)として、data(説明変数)とtarget(目的変数)が返ってきますので、変数に格納します。
# ボストン住宅価格データセットの読み込み
from sklearn.datasets import load_boston
boston = load_boston()
# 説明変数
X_array = boston.data
# 目的変数
y_array = boston.target
説明変数の出力
for i in X_array:print(i)
[ 6.32000000e-03 1.80000000e+01 2.31000000e+00 0.00000000e+00
5.38000000e-01 6.57500000e+00 6.52000000e+01 4.09000000e+00
1.00000000e+00 2.96000000e+02 1.53000000e+01 3.96900000e+02
4.98000000e+00]
[ 2.73100000e-02 0.00000000e+00 7.07000000e+00 0.00000000e+00
4.69000000e-01 6.42100000e+00 7.89000000e+01 4.96710000e+00
2.00000000e+00 2.42000000e+02 1.78000000e+01 3.96900000e+02
9.14000000e+00]
[ 2.72900000e-02 0.00000000e+00 7.07000000e+00 0.00000000e+00
4.69000000e-01 7.18500000e+00 6.11000000e+01 4.96710000e+00
2.00000000e+00 2.42000000e+02 1.78000000e+01 3.92830000e+02
4.03000000e+00]
(省略)
[ 6.07600000e-02 0.00000000e+00 1.19300000e+01 0.00000000e+00
5.73000000e-01 6.97600000e+00 9.10000000e+01 2.16750000e+00
1.00000000e+00 2.73000000e+02 2.10000000e+01 3.96900000e+02
5.64000000e+00]
[ 1.09590000e-01 0.00000000e+00 1.19300000e+01 0.00000000e+00
5.73000000e-01 6.79400000e+00 8.93000000e+01 2.38890000e+00
1.00000000e+00 2.73000000e+02 2.10000000e+01 3.93450000e+02
6.48000000e+00]
[ 4.74100000e-02 0.00000000e+00 1.19300000e+01 0.00000000e+00
5.73000000e-01 6.03000000e+00 8.08000000e+01 2.50500000e+00
1.00000000e+00 2.73000000e+02 2.10000000e+01 3.96900000e+02
7.88000000e+00]
説明変数のカラムの説明
以下、13カラムで出力されます。(公式サイトの説明をGoogle翻訳したものをベースにしています。)
| カラム | 説明 |
|---|---|
| CRIM | 町ごとの一人当たりの犯罪率 |
| ZN | 宅地の比率が25,000平方フィートを超える敷地に区画されている。 |
| INDUS | 町当たりの非小売業エーカーの割合 |
| CHAS | チャーリーズ川ダミー変数(川の境界にある場合は1、それ以外の場合は0) |
| NOX | 一酸化窒素濃度(1000万分の1) |
| RM | 1住戸あたりの平均部屋数 |
| AGE | 1940年以前に建設された所有占有ユニットの年齢比率 |
| DIS | 5つのボストンの雇用センターまでの加重距離 |
| RAD | ラジアルハイウェイへのアクセス可能性の指標 |
| TAX | 10,000ドルあたりの税全額固定資産税率 |
| PTRATIO | 生徒教師の比率 |
| B | 町における黒人の割合 |
| LSTAT | 人口当たり地位が低い率 |
| MEDV | 1000ドルでの所有者居住住宅の中央値 |
目的変数の出力
print(y_array)
[ 24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9
21.7 20.4 18.2 19.9 23.1 17.5 20.2 18.2 13.6 19.6 15.2 14.5
15.6 13.9 16.6 14.8 18.4 21. 12.7 14.5 13.2 13.1 13.5 18.9
20. 21. 24.7 30.8 34.9 26.6 25.3 24.7 21.2 19.3 20. 16.6
(中略)
19.1 20.1 19.9 19.6 23.2 29.8 13.8 13.3 16.7 12. 14.6 21.4
23. 23.7 25. 21.8 20.6 21.2 19.1 20.6 15.2 7. 8.1 13.6
20.1 21.8 24.5 23.1 19.7 18.3 21.2 17.5 16.8 22.4 20.6 23.9
22. 11.9]
単位は、1,000(USD)です。
説明変数、目的変数を統合してDataFrame化
import pandas as pd
import numpy as np
from pandas import DataFrame
df = DataFrame(X_array, columns = boston.feature_names).assign(MEDV=np.array(y_array))
# ヘッダ出力
df.head
以下、DataFrameの中身を確認します。
相関関係の可視化
- 説明変数の各項目(CRIMなど)と目的変数(MEDV)の相関関係を以下、可視化してみます。
- グラフ描画ライブラリのseabornをインポートします。
import seaborn as sns
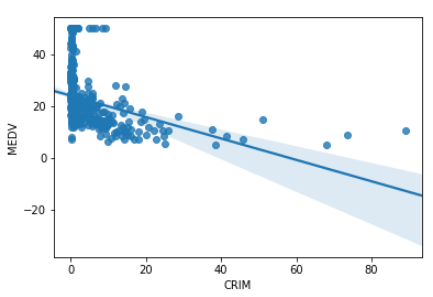
CRIM(犯罪率) - MEDV(住宅価格)
# CRIM(犯罪率)、MEDV(住宅価格)
sns.regplot('CRIM','MEDV',data = df)
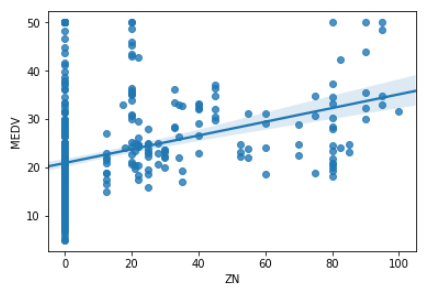
ZN(宅地比率) - MEDV(住宅価格)
# ZN(宅地比率)、MEDV(住宅価格)で可視化
sns.regplot('ZN','MEDV',data = df)
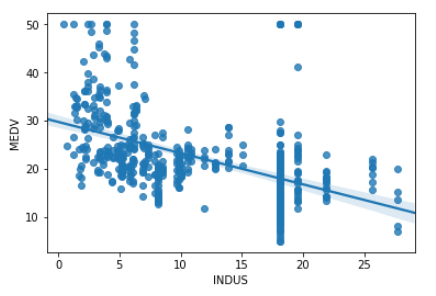
INDUS(非小売業エーカーの割合) - MEDV(住宅価格)
# INDUS(非小売業エーカーの割合)、MEDV(住宅価格)で可視化
sns.regplot('INDUS','MEDV',data = df)
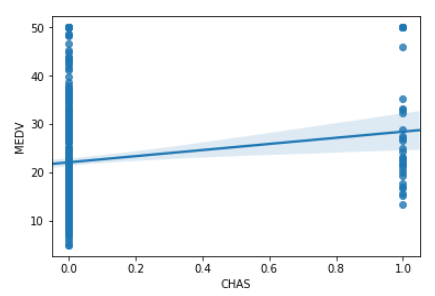
CHAS(チャーリーズ川ダミー変数) - MEDV(住宅価格)
# CHAS(チャーリーズ川ダミー変数)、MEDV(住宅価格)で可視化
sns.regplot('CHAS','MEDV',data = df)
RM(1住戸あたりの平均部屋数) - MEDV(住宅価格)
# RM(1住戸あたりの平均部屋数)、MEDV(住宅価格)で可視化
sns.regplot('RM','MEDV',data = df)
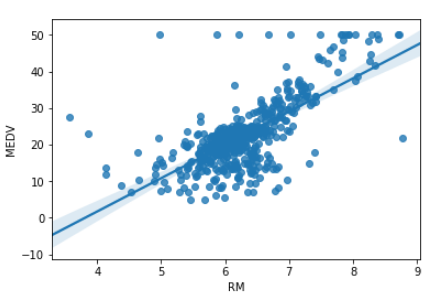
- このように可視化してみると、RM(1住戸あたりの平均部屋数)は、MEDV(住宅価格)と相関関係が見て取れますが、CHAS(チャーリーズ川ダミー変数)には相関関係は見て取れそうに無いですね。
線形回帰で学習
- この記事と同様にscikit-learnを使用して学習させて見ます。
# scikit-learnの準備
from sklearn.model_selection import train_test_split
# 訓練データとテストデータに8:2で分割
X_train, X_test, y_train, y_test = train_test_split(X_array, y_array, test_size=0.2, random_state=0)
# 線形回帰で学習
from sklearn import linear_model
model = linear_model.LinearRegression()
model.fit(X_train, y_train)
# 訓練データを用いた評価
print(model.score(X_train, y_train))
# テストデータを用いた評価
print(model.score(X_test, y_test))
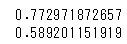
- 残念ながら、あまり精度は高くないようです。
- 後日、非線形回帰の手法も試してみたいと思いますが、本記事ではここまでとしたいと思います。