はじめに
はじめまして修士で研究者のはしくれをやっている者です。
新日鉄住金ソリューションズ(NSSOL)様のインターンにて論文を読んだので僭越ながら解説記事を書きたいと思います。
元論文へのリンクも貼っておきますのでより詳しく知りたい方はそちらをご参照ください。
概要
今回紹介するのは”Mapping Natural Language Commands to Web Elements”
(論文: https://arxiv.org/abs/1808.09132
リポジトリ: https://github.com/stanfordnlp/phrasenode)
簡潔に言えば自然言語でwebページを操作する研究です。以下の画像は論文からの引用なのですが目的を端的に表しています。
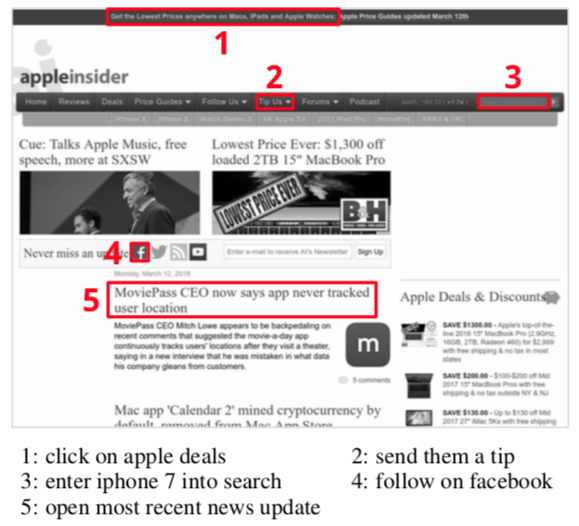
”チップを送って”と入力すると”チップを送る”のタブが選択され、該当アドレスに移動できる感じですね。
そのために“自然言語”、”webページ”両方を意味的に解釈してつなぎ合わせるというのがこの研究です。
データセット
まずはデータセットについて説明します。データセットは1835のwebページと51663のコマンドのデータセットが用意されています。
Webページ はgoogleのトップ10000万のホームページから不適切なものをフィルタリングしたもの。コマンドはクラウドワーカを使って行いたい操作を記述してもらったものです。
データは以下の様な形で表されています(リポジトリのdata/phrase-node-dataset/dataのディレクトリにあります。)
{"equiv": [12], "exampleId": "3PW9OPU9PREF0OL3SDSRC5UBCW512V_a0", "phrase": "go to home page", "version": "v6", "webpage": "110mb.com", "xid": 12}
簡単に説明すると
- ”xid”はwebページのコマンドと等しい要素。
- “equiv”は”xid”とリンク先が一致する要素。
- “phrase”はコマンドの自然言語表現。
- “version”,”webpage”はwebpageの情報のキー。
このデータのphraseとwebページのデータが入力、xidが予測したいものになります。
そしてwebpageの元データはdata/phrase-node-dataset/infos/v6の中に入っています。
version,webpageのデータを元に検索しnode毎の形に整形しています。このコード内でnode毎の形に整形している。(phrasenode/webpage.py)
整形され以下の様な形で表されます。
{u'styles': {}, u'topLevel': True, u'top': 0, u'height': 15520, u'width': 1280, u'tag': u'BODY', u'id': None, u'attributes': {u'class': u'enable-animations icons-loaded'}, u'hidden': False, u'classes': u'enable-animations icons-loaded', u'ref': 0, u'children': [1, 464], u'left': 0}
更に同コード内で入力に用いられる次の形に整形します。とりあえず入力として以下を用いると覚えていただければ大丈夫です。
tags @ (x_ratio, y_ratio) text id classes children
モデル
全体の構造は以下の図のようになっています。
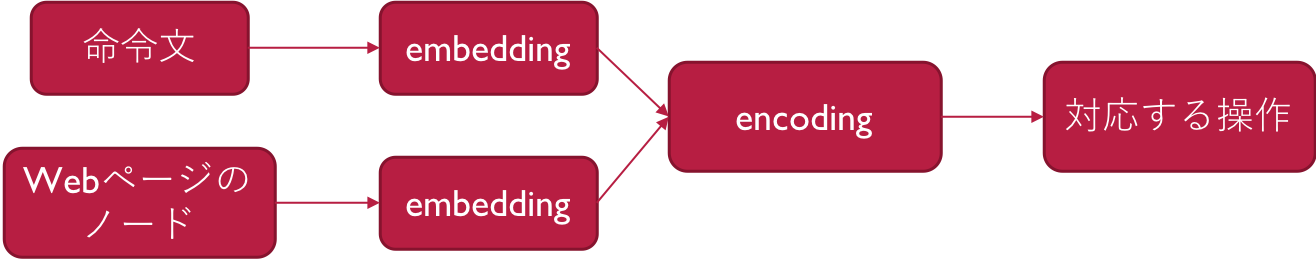
命令文の埋め込み、webのノードの埋め込み、2つを組み合わせるencodingのおおよそ3つの構造を持ています。
命令文の埋め込み
命令文の埋め込みでは各トークンの分散表現を平均します。平均ではなくLSTMも用いたが改善しなかったそうです。
埋め込みにはGloVeというモデルを用いています。GloVeについてここでは詳しく説明しませんが簡潔に言えばWord2vecとSVDの良い所取りをしたモデルです。
# Embed the phrases + normalize
phrases = []
for example in examples:
phrases.append(word_tokenize(example.phrase.lower()))
# num_phrases x dim
phrase_embeddings = self.phrase_embedder(phrases)
if self.proj is not None:
phrase_embeddings = F.sigmoid(self.proj(phrase_embeddings))
else:
pass
phrase_embeddings = phrase_embeddings / torch.clamp(phrase_embeddings.norm(p=2, dim=1, keepdim=True), min=1e-8)
Webのノードの埋め込み
Webのノードの埋め込みでは各ノード毎に文章、ノードの属性、見た目の特徴の3つのパートに分けて埋め込みを行い、最後に連結します。
例えばnodeは以下の様な形で入力されます。
span @ (0.0, 0.0) text=u'Toggle navigation' classes=[[u'sr-only']]
ノード埋め込みの大まかな構成は以下の様になっています。
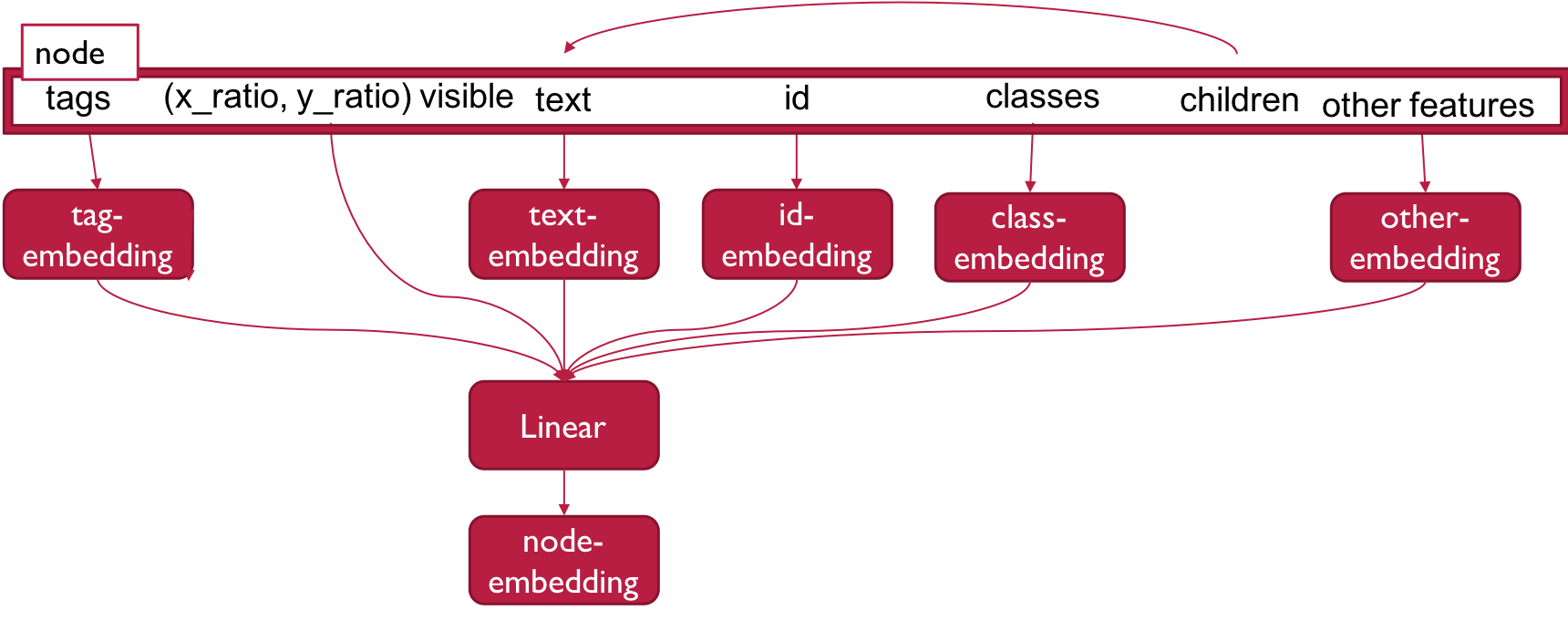
文章の埋め込み(text)
命令文に適用したものと同様のGloVeを利用して埋め込む。
各文章は大抵そんなに長くないと言う事で10単語を上限としている。
texts = []
for node in nodes:
if not self.ablate_text:
if self._recursive_texts:
text = ' '.join(node.all_texts(max_words=self._max_words))
else:
text = node.text or ''
texts.append(word_tokenize2(text))
else:
texts.append([])
text_embeddings = self._utterance_embedder(texts)
文章の属性の埋め込み(ex,classes,tag,ids)
各属性毎に埋め込みを行い、複数ある場合は平均をとる
# num_nodes x attr_embed_dim
tags = [node.tag for node in nodes]
tag_embeddings = self._tag_embedder.embed_tokens(tags)
# num_nodes x attr_embed_dim
if not self.ablate_attrs:
ids = [word_tokenize2(node.id_) for node in nodes]
else:
ids = [[] for node in nodes]
id_embeddings = self._id_embedder(ids)
# num_nodes x attr_embed_dim
if not self.ablate_attrs:
classes = [word_tokenize2(' '.join(node.classes)) for node in nodes]
else:
classes = [[] for node in nodes]
class_embeddings = self._classes_embedder(classes)
if not self.ablate_attrs:
other = [word_tokenize2(semantic_attrs(node.attributes)) for node in nodes]
else:
other = [[] for node in nodes]
other_embeddings = self._other_embedder(other)
見た目の特徴の埋め込み(ex, (0.0, 0.0) )
x軸上の割合、y軸状の割合、視認性(bool)の3つの要素をそのまま用いる
# num_nodes x 3
coords = V(FT([[node.x_ratio, node.y_ratio, float(node.visible)] for node in nodes]))
最後に全ての埋め込み(文章、クラス、タグ、ids、見た目の特徴)を連結し線形層に通します。
# num_nodes x dom_embed_dim
dom_embeddings = torch.cat((text_embeddings, tag_embeddings, id_embeddings, class_embeddings, other_embeddings, coords), dim=1)
#dom_embeddings = text_embeddings
return self.fc(dom_embeddings)
#return F.relu(self.fc(self.dropout(dom_embeddings)))
#return F.sigmoid(self.fc(dom_embeddings))
最後にエンコーディングを行います。
[命令の埋め込み、WEBページの埋め込み、命令埋め込み*WEBページ埋め込み]をドロップアウトし線形層を通して出力を生成します。
出力と答えのidとのクロスエントロピー損失をバックプロパゲーションして学習します。
比較手法
比較手法としてはTF-IDFで全ての要素をスコア付けして命令文を検索クエリとして要素検索を行う検索ベースのモデルと命令文と各ノードのテキストトークンを直接相互作用させるアライメントベースのモデルを用いている。アライメントベースモデルも筆者らの考案したモデルである。
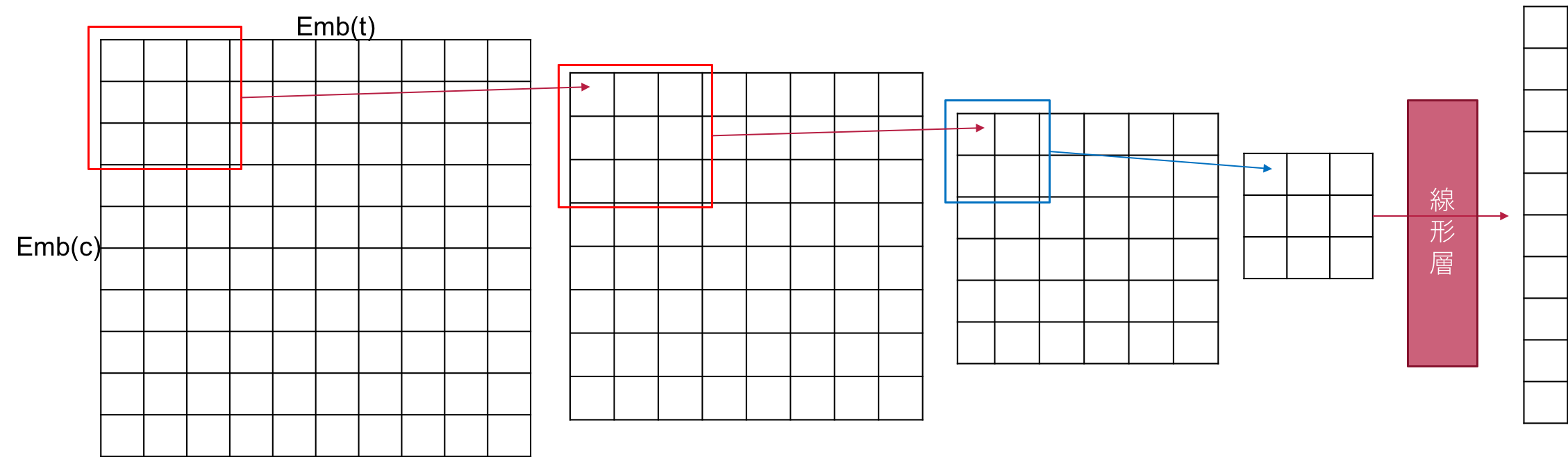
エレメントのテキストと属性を連結し10文字までにトリミングしてエンベディングしたものがEmb(t)、命令も同様に10文字までにトリミングしてエンベディングしたものがEmb(c)です。内積をとったものに33の畳み込みを2回とと22のプーリングを行い、タグのエンベディングと連結した後線形層に通して10次元のエンコーディングを受け取ります。
実験結果
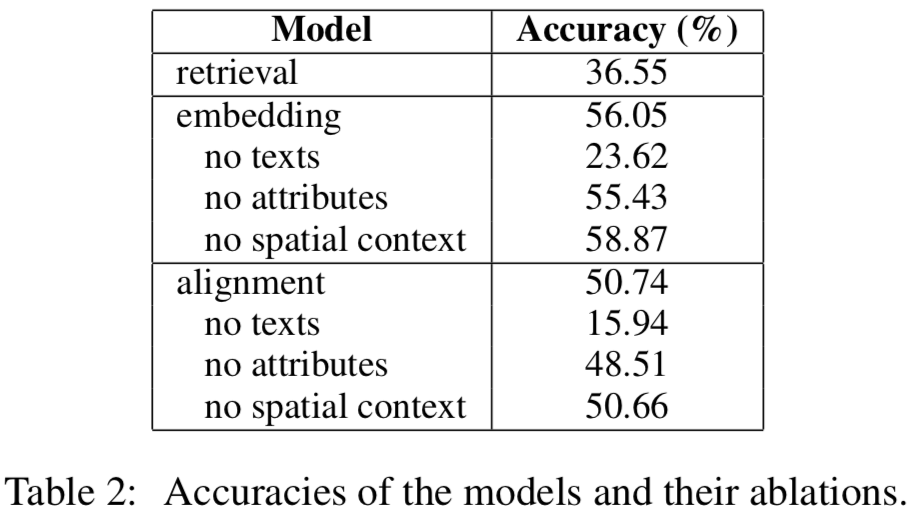
ここで精度は最も高い予測スコアの要素が正解と一致する割合です。一部情報を除いたものと比較すると文書情報がやっぱり重要なんだなとか空間的な文脈情報は取り入れてもあまり精度に繋がらないとかわかります。
失敗例
一部合致
(e.g., “click customised garages” → the link with text “Customised Garages, Canopies & Carports”)
エンコーディングモデルは全部のトークンの平均を取ってるから一部一致に弱い。コマンドの部分のエンベディングをLSTMにしてもダメだったらしいですがアテンションだとうまく行ったりしないですかね。
文字列の不一致
(e.g., “shop for knitwear” when many elements contain the word “shop”)
同じ単語を含む選択肢がたくさんある場合も結構失敗する様です。あるいは
(e.g., “get the program” → the “Download” link, not the “Microsoft developer program” link).
単語だけなら近い他の要素がある場合も単語一致に引っ張られて意味的な解釈が出来ない事があります。
説明文
(e.g., “please close this notice for me” → the “X” button with hidden text “Hide“).
間接的な説明文は難しい様です。様々な特性を埋め込んでいる分、エンコーディングモデルの方が相性が良い問題の様です。
推論できない
例えばテキストボックス。なになにの文章の下のボックス、などの様に近くの状況を絡めて説明するしか無いが解釈が難しい。
複数の答え
複数の合致する答えがある時に明確にユーザが求める答えを返せない。
成功例
失敗例だけ見せてもあれなので良い感じの奴も載せてみます。

Webページ: www.000webhost.com
命令文:
1:“find me the website builder tab.”明確に単語が入っていれば当たる。
2:“sign me up”複数のsign upアイコンが存在するが予測上位5件に全て含まれていた。
3:“see how i can make money”簡単なパラフレーズは問題ない。