Puppeteer?
読み方は「ぱぺてぃあ」。
Node.jsのライブラリでChromeを操作しDOMの要素を取得、ステータスコードを取得、レスポンスタイムを計測・・等々できます。
※Chromeのデベロッパーツールで見れる情報は(たぶん)全てpuppeteerで取得できる
Sample
「サイト内の各ページのタイトルが予測した値になっているか?」という自動テストをPuppeteerを利用して処理してみます。
大まかな流れは下記のようになります。
- テストデータをCSVファイルから読み込み
- 1行ずつループし、取得した値と予測した値を比較
- 結果表示
Code
$ tree -I node_modules
.
├── package.json
└── src
├── data
│ └── title.test.csv
├── lib
│ └── output.js
└── test
└── title // テスト・処理内容応じてにディレクトリを切って、実行ファイル(index.js)と説明ファイル(README.md)を置くといい感じ
├── README.md // テスト概要や実行方法を記載
└── index.js // 実行ファイル
index.js
const puppeteer = require('puppeteer');
const papa = require('papaparse');
const assert = require('assert');
const fs = require('fs');
const root = '../../'
const { showTestStart, showResult } = require(root + 'lib/output');
// メイン処理
(async () => {
console.time('Processing time');
// テスト対象のサイト
const domain = 'https://www.google.com';
// テスト対象のデータ ※ Listを直接コードに書く、CSVから読み込む etc...
file = fs.readFileSync(root + 'data/title.test.csv', 'utf8')
dataList = papa.parse(file, {
header: true,
skipEmptyLines: true
}).data;
// カウンタ初期化
let count = 0;
// エラー一覧
let errorList = [];
// ブラウザ起動
const browser = await puppeteer.launch();
for (const data of dataList) {
count += 1;
// アクセス先のURLを生成
const url = domain + data.path;
// 進捗を表示
showTestStart(url, count, dataList);
// ページ生成
const page = await browser.newPage();
// JSやCSSの読み込みを無視
await page.setRequestInterception(true);
page.on('request', (interceptedRequest) => {
if (url === interceptedRequest.url()) {
interceptedRequest.continue();
} else {
interceptedRequest.abort();
}
});
// テスト対象のURLにアクセス(返り値にresponseが返る)
await page.goto(url);
// ページタイトル取得
const title = await page.title();
try {
// 予期された結果と比較
assert.equal(title, data.title);
console.log('✅ ' + 'Expected result');
} catch (err) {
console.log('❌ ' + 'Unexpected result');
console.log(err.message);
errorList.push(err.message);
}
console.log('\n');
// ページ閉じる
await page.close();
}
// ブラウザ閉じる
await browser.close()
showResult(errorList);
console.timeEnd('Processing time');
})();
lib/output.js
exports.showTestStart = (currentUrl, index, urls) => {
const color = '\u001b[44m\u001b[37m';
const reset = '\u001b[0m';
console.log(`${color} 🖥 ${currentUrl} | ${index} / ${urls.length} ${reset}`);
};
exports.showResult = (errorList) => {
let msg = '';
if (errorList.length === 0) {
msg = '✅ 🎉🎉🎉Congratulation for passing!!🎉🎉🎉';
} else {
msg = '❌ Failed the test...😭';
}
console.log('\n' + msg + '\n');
};
data/title.test.csv
url,title
/,Google
/search/howsearchworks/,Google Search - Discover How Google Search Works
package.json
{
"name": "puppeteer-template",
"version": "1.0.0",
"description": "",
"main": "index.js",
"directories": {
"test": "test"
},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "yusukeito58",
"license": "MIT",
"dependencies": {
"assert": "^2.0.0",
"papaparse": "^5.1.1",
"puppeteer": "^2.1.1"
}
}
実行
サンプルで用意したプログラムを実行してみます。
$ git clone https://github.com/yusukeito58/puppeteer-template.git
$ npm i
$ cd src/test/title
# 実行
$ node index.js
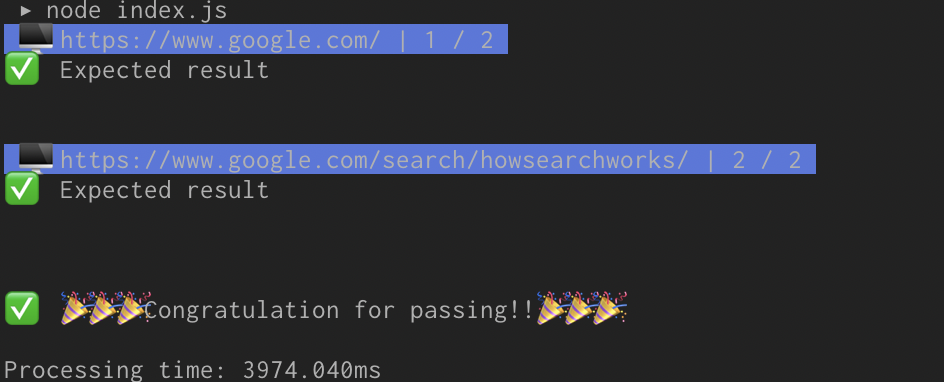
結果
うまくいくと下記のように表示されます。
Tips
個人的に利用頻度が多い処理をまとめておきます。
特定要素の有無を判定
例. 検索ボタンがあるか確認
// 要素を取得
const hasElement = async (page, selector) => {
const item = await page.$(); // selectorを引数で受け取るようにするともっと汎用的に使える
if (item) {
return true;
} else {
return false;
}
};
(async () => {
for (...) {
:
const selector = 'center > input.gNO89b';
ret = await hasElement(page, selector);
:
}
}();
UserAgentを指定
例.デバイスを「iPhone X」に設定
const devices = require('puppeteer/DeviceDescriptors');
// テストデバイス
const device = devices['iPhone X'];
(async () => {
for (...) {
:
// デバイス設定
await page.emulate(device);
:
}
}();
JSやCSSなどの読み込みを無視
処理速度が数倍違ってきます。
(async () => {
for (...) {
:
await page.setRequestInterception(true);
page.on('request', (interceptedRequest) => {
if (url === interceptedRequest.url()) {
interceptedRequest.continue();
} else {
interceptedRequest.abort();
}
});
:
}
}();
テストデータをCSVファイルから取得
url,title
/,Google
/search/howsearchworks/,Google Search - Discover How Google Search Works
const papa = require('papaparse');
const fs = require('fs');
:
(async () => {
:
// テストデータ取得
file = fs.readFileSync(root + 'data/title.test.csv', 'utf8')
dataList = papa.parse(file, {
header: true,
skipEmptyLines: true
}).data;
:
)();
非同期に対象ページにアクセス
データが大量にあった場合、直列的に対象ページにアクセスすると処理時間を要するため、非同期に同時処理すると処理時間が短縮されます。
安定しないケースもあるので、検証が必要かも知れません。(もっと良い方法ありそう)
例. 大量の対象URLが全て正常(ステータスコードが200である)か確認する
// ステータスコードを取得
const getStatusCode = (browser, url) => {
return new Promise(async (resolve) => {
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(0);
await page.setRequestInterception(true);
page.on('request', (interceptedRequest) => {
if (url === interceptedRequest.url()) {
interceptedRequest.continue();
} else {
interceptedRequest.abort();
}
});
const response = await page.goto(url);
// ステータスコードを返却(true:200台)
const result = {
'url': url,
'status': response.ok()
}
await page.close();
resolve(result);
})
}
:
(async () => {
:
for (let url of urls) {
allResponse.push(getStatusCode(browser, url)) // あまり大量だとPCがが唸る・・・
}
errors = await Promise.all(allResponse) // 非同期実行
.then(results => {
// エラーとなった情報だけにフィルタリング
return results.filter(result => !result.status)
})
:
)();
配列を〇〇個ごとに分割
Puppeteerから少し外れますが、前項の非同期処理を行う前処理です。同時実行する個数に調整する際に利用します。
const divideArrIntoPieces = (arr, n) => {
let arrList = [];
let idx = 0;
while(idx < arr.length){
arrList.push(arr.splice(idx, idx + n));
}
return arrList;
}
(async () => {
:
urlList = divideArrIntoPieces(allUrl, 10);
for (let urls of urlList) {
for (let url of urls) {
:
}
}
}();
画像を保存
// ダウンロード対象
imgUrl = 'https://www.google.com/images/branding/googlelogo/2x/googlelogo_color_272x92dp.png';
// ローカルの保存先
const imgPath = './images/image.jpg';
// 画像ダウンロード
const viewSource = await page.goto(imgUrl);
// ローカルに保存
fs.writeFileSync(imgPath, await viewSource.buffer());
参考
- Puppeteer : https://github.com/puppeteer/puppeteer
- Examples : https://github.com/puppeteer/examples
- API Document : https://github.com/puppeteer/puppeteer/blob/master/docs/api.md
- Assert : https://nodejs.org/api/assert.html
- Papaparse : https://www.papaparse.com