はじめに
ニューラルグループ株式会社でインターンをしている酒井です。
全3回にわたって深層学習を用いたブレ除去法(Deblurring)について概観したいと思います。
- Deblur概観: 古典〜2023最新の汎用手法
- Deblur応用: ナンバープレート/超解像
- Deblur研究: ペアを必要としないDeblurGAN
深層学習のブレ除去法は、Zhang et al. (2022) Deep Image Deblurring: A Survey
に非常によく書かれているので、興味のある方はぜひそちらも一読ください。
Deblurring学習データ作成手法
まず、ブレ除去という研究分野の概観については、
をご一読ください。
この章では、学習データの作成方法に絞って紹介します。学習データの集め方は、ブレ除去モデルの種類によって主に以下の2種類に大別されます。
- 同じ瞬間で同じ画角(同一シーン)のブレ画像・シャープ画像の対が必要な場合
- シーンが同一でなくても、同一ドメインのブレ画像・シャープ画像の対があれば良い場合
学習データをWebや動画などから収集したい場合には、後者の同一シーンの縛りがない方が有利なことが多いです。
同一シーンのブレ画像・シャープ画像対の取得方法
多くのdeblurringモデルでは、同一シーンのブレ画像とシャープ画像が学習データに必要です。ペアの学習データの生成には、主に以下の4つの方法があります。
- [人工的なブレ]高フレームレートで高シャッタースピードの連続する画像を数フレーム重ね合わせて人工的なブレ画像を作る
- [人工的なブレ]シャープ画像を適当なカーネルで畳み込んで人工的なブレ画像を作る
- [生成したブレ]同一シーンでないシャープ画像とブレ画像を使って学習したモデルを用いて、シャープ画像から生成モデルでブレ画像を作る
- [本物のブレ]カメラを工夫し、シャッタースピードの長い画像 (ブレ画像) と、短い画像 (シャープ画像) を同時に撮影できるようにする
これらの手法の違いとして、ブレ画像とシャープ画像のペアを擬似的に用意するか本物のペアを使うかという点です。人工的なブレはシャープ画像を平均して作ることが多く取得が容易ですが、下図のように実世界のブレを精確に再現できないという課題があります (e.g., Rim et al (2020))。

Realistic Blur Synthesis for Learning Image Deblurring (2022)より引用
上段が、本物のブレ画像で、下段が、高フレームレートの画像を平均化した人工的なブレ画像です。このように、露光時間の情報がないことによるアーチファクト以外に、サチュレーションやノイズなどの違いもあり、人工的なブレ画像はこれらの情報を完全に再現することは困難な課題です。
ただし、実世界のブレ画像とシャープ画像のペアの用意はコストが非常にかかるため、ブレ除去法の評価指標としてよく用いられるPSNRやSSIMも、人工的に作ったブレ画像を用いたデータを使うことが多いです。したがって、実世界のブレ除去性の評価に課題を抱えています。
高フレームレートで高シャッタースピードの連続する画像を数フレーム重ね合わせて人工的なブレ画像を作る
高フレームレートで高シャッタースピードな画像を用いることで、連続画像間の変化が非常に小さく、複数の画像の平均を取ることで擬似的にブレ画像を作ることができます。この方法は、ブレ除去手法の学習データとして最も普及していて、単一画像のブレ除去(Single-Image Deblurring)だけでなく、複数の連続画像のブレ除去(Video Deblurring)にもよく使われています。
この手法を用いているGoPro datasetでは、240FPSで撮影し、連続する数フレームを平均しブレ画像を作っています。
しかし、240FPSの撮影でも高速で動く物体が、飛び飛びに映るアーチファクトが発生することがあり、その問題を緩和するためにソフトウェア側でフレームを補完し、ブレ画像を作ることもあります。一例として、DeblurGAN-v2は、フレーム補完法で、240FPSから3840FPSに補完することで、より滑らかなブレを作っています。
また、240FPSの高速カメラでの撮影は、シャープ画像に高フレームレート由来のノイズが入る問題もあり、これを解決するために、フレームレートを犠牲にするが高解像度で撮影したものを使い、ブレ画像を同様に作成したのちに解像度を落とすことでこのノイズを抑えるという方法もあります。実例として以下2つがあります。
Nah et al. (2019)では、1080×1920の120FPSの画像を撮影し、フレーム補完で1920FPSにし、数フレームを平均によりブレを作り、その後、解像度を落とすことで人工的なノイズを低減したブレ画像を作っています。
同様に、Hyun Kim, T. et al. (2017)では、GoPro datasetの解像度を落としてノイズを低減して使用しています。
シャープ画像を適当なPSFで畳み込んで人工的なブレ画像を作る
ブレは、数学的にPoint Spread Function(PSF)との畳み込みにノイズを加えたものでモデル化できます。したがって、適当に用意したPSFとノイズを加えてブレ画像を作ることができます。この方法は、単一的なブレを表現するモデルの学習データに使われることがありますが、場所ごとにブレが異なる場合にはあまり向いていないです。
その理由は、被写体が動いてできるブレなどは、場所毎でPSFが異なりモデル化が難しい点にあります。ただし、幾何学的に再現可能な場合(カメラのパン、チルト、ロールなどによって起きるブレなど)は、PSFが一様でなくても、場所毎に用意して畳み込みブレを作ることが可能です。
また、複数フレームを用いたVideo Deblurringでは、前後のフレームのブレ情報の一貫性を重視するため、この方法では一般的に作成困難です。
この方法について興味のある方は、Kupyn et al. (2018) DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networksによくまとまっているのでご覧ください。
同一シーンでないシャープ画像とブレ画像を使って学習したモデルを用いて、シャープ画像から生成モデルでブレ画像を作る
Zhang et al. (2020)で導入されているように、別々のシーンのシャープ画像・ブレ画像で学習されたGANを使って、ブレ画像を作ることもできます。この手法は、前述の2つの手法に比べて、Non-uniformブラーを滑らかに再現することができますが、ドメイン依存のため、学習データにないドメインのデータを入れた場合、現実的にあり得ないブレ画像が生成される可能性があり注意が必要です。
カメラを工夫し、シャッタースピードの長い画像 (ブレ画像) と、短い画像 (シャープ画像) を同時に撮影できるようにする
この方法は、同一シーンのブレ画像とシャープ画像を用いた学習データの理想の形になりますが、一般的なカメラではなく特殊な機器を要するため、コストがかかります。
方法としては、完全に同じ画角で同じタイミングの2つの露光時間の異なる画像を用意するために、ESTRNNで導入されているような、レンズ中の光を2つに分けるビームスプリッターを内蔵した特殊カメラで時刻を同期させてブレ・シャープのペアを同時に撮影するというものです。本物のブレ画像シャープ画像を使える点が、この手法の最大の利点です。
同一ドメインだが別のシーンのブレ画像シャープ画像でも良い手法
いくつかのブレ除去手法は、完全に独立したブレ画像とシャープ画像で学習できるモデルもあり、学習データの収集コストを大幅に抑えることができます。
詳細は、3. Deblur研究: ペアを必要としないDeblurGANをご覧ください。
モデルの性能
ブレ除去モデルの性能は、ブレ除去画像の推定精度と、推論速度、計算コストなどで評価されます。以下にそのブレ除去画像の使われ方を示していきます。
ブレ除去画像評価指標
画像の評価指標には、リファレンス画像(劣化のない同一シーンの鮮明な画像)が必要な指標と、リファレンス画像が不要な指標があります。つまり、ブレ除去画像での評価時は、同一シーンのブレ画像とシャープ画像を用いる場合が、リファレンス画像ありに該当し、
画像の品質を客観的に評価する際には、これらの評価指標が重要な役割を果たし、多種多様の評価指標が開発されています。
その理由は、画像の劣化度合いを評価する際には、以下のような「The Perception-Distortion (P-D) tradeoff」として知られる関係が存在します (参考: The Perception-Distortion Tradeoff (2018), Deblurring via Stochastic Refinement (2022))。
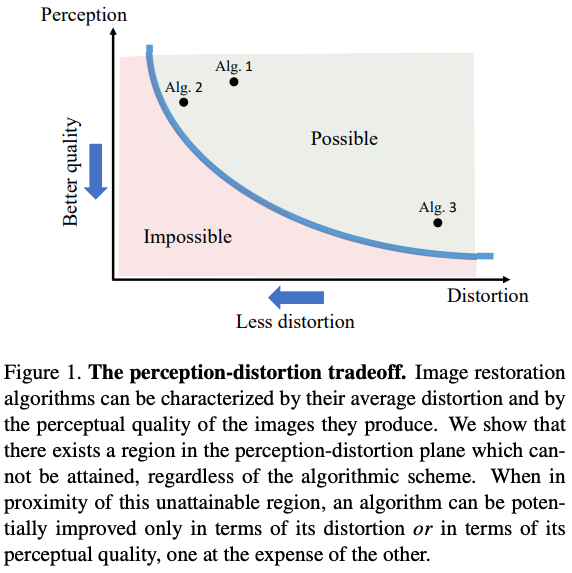
上図のトレードオフの関係は、知覚的な品質(Perception)と歪み情報(Distortion)の両方を良くする時に、その間に限界値が存在することを示しています。
ここでの知覚的品質は、主に人間が自然度合いを評価した指標などリファレンス画像を用いない指標を指し、歪み情報は主にリファレンス画像ありの評価指標が該当します。
そういったP-D tradeoffの関係もあるため、ブレ除去手法も複数の多様な指標を組み合わせてモデルを評価することが多いです。以下で、指標について簡単にまとめていきます。
| 指標名 (太字はブレ除去でよく使われる指標) |
リファレンス画像要否 | 指標の特性 | 値域 | 良い側のスコア | 発表された年 |
|---|---|---|---|---|---|
| PSNR | ⚪︎ | 評価対象画像とリファレンス画像とのピーク信号対雑音比 | [0,∞) | ↑ | 不明 |
| SSIM | ⚪︎ | 評価対象画像とリファレンス画像との構造的類似性指数 | [0,1] | ↑ | 2004 |
| MS-SSIM | ⚪︎ | マルチスケールで改良されたSSIM | [0,1] | ↑ | 2003 |
| VIF | ⚪︎ | 視覚情報の信頼性を測定指標 | [0,1] | ↑ | 2006 |
| IFC | ⚪︎ | 画像の情報の信頼性を測定指標 | [0,1] | ↑ | 2005 |
| CSE | ⚪︎ | 色の違いに焦点を当てた指標 | [0,∞) | ↓ | 2021 |
| LPIPS | ⚪︎ | 学習済みのネットワークを用いた知覚的評価指標 | [0,1] | ↓ | 2018 |
| FID | ⚪︎ | 生成モデルの出力画像と本物の画像の特徴量分布の類似性を測定する指標 | [0,∞) | ↓ | 2017 |
| NIQE | × | 自然な画像度合いの評価指標 | [0,∞) | ↓ | 2012 |
| BRISQUE | × | 歪み度合いの評価指標 | [0,100] | ↓ | 2012 |
| MOS | × | 人間の主観的評価指標 | [1,5] | ↑ | 不明 |
| Liu's metrics | × | 主観的品質評価スコアから回帰分析で作成した評価指標 | [0,1] | ↑ | 2013 |
リファレンス画像必要な指標
Peak Signal-to-Noise Ratio (PSNR)
PSNRは、後述のSSIMと並んでブレ除去で非常によく使われる客観的手法で、リファレンスのシャープ画像と評価するブレ画像の画素値の差分をデシベルで表現したものであり、ブレ画像の最大画素値の自乗値と差分自乗平均値を用いて計算されます。スコアが大きいほど劣化が少ないことを示します。
Structural similarity (SSIM)
Image Quality Assessment: From Error Visibility to Structural Similarity (2004)で提案された、輝度、コントラスト、構造の比較を行うため、PSNRよりもより人間の知覚に近いスコアを提供します。スコアが大きいほど、劣化が少ないことを示します。
このSSIMは、SSIM lossとしてブレ除去の損失関数として使用した手法(Progressive edge-sensing dynamic scene deblurring (2022))もあります。
Multi-Scale Structural Similarity (MS-SSIM)
Multiscale structural similarity for image quality assessment (2003)で提案された、SSIMの拡張版であり、複数のスケールにわたる画像の類似性を評価します。SSIMに比べて、画像の構造的な類似性をより詳細に評価することができます。
Deep Generative Filter for Motion Deblurring (2017)で使われています。
Visual Information Fidelity (VIF)
Image Information and Visual Quality (2006)で提案された、画像の知覚品質を測る指標で、値が0から1の範囲で表され、1に近いほどリファレンス画像に近い品質を持ちます。
Deep architecture for super-resolution and deblurring of text images (2023)で使われています。
Information Fidelity Criterion (IFC)
An Information Fidelity Criterion for Image Quality Assessment Using Natural Scene Statistics (2005)で提案された、情報理論に基づく画像間の特徴の評価指標で、値が0から1の範囲で表され、スコアが高いほど情報の損失が少ない、すなわちリファレンス画像に近いことを示します。
VIF評価指標で紹介した論文、Deep architecture for super-resolution and deblurring of text images (2023)で使われています。
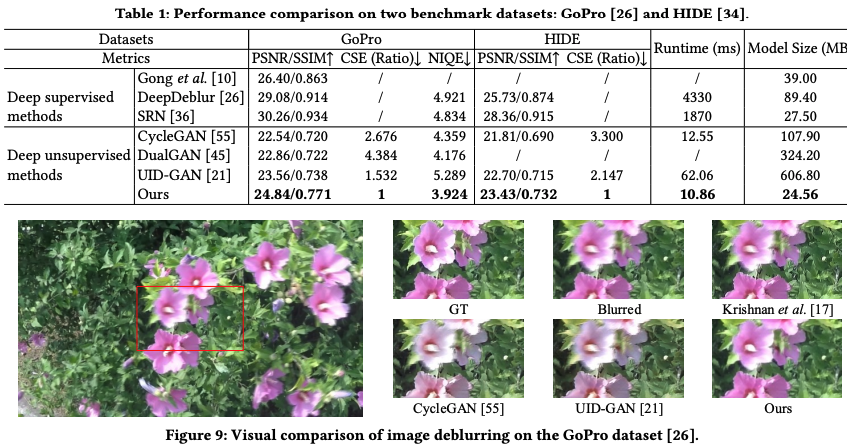
Color-Sensitive Error (CSE)
CRNet: Unsupervised Color Retention Network for Blind Motion Deblurring (2021)で提案された、リファレンス画像ありの画像の色収差における指標、すなわち色の違い度合いを客観的に評価する方法です。CSEが小さいほどよい結果であり、以下がさまざまなブレ除去モデルの結果とその評価値を表しています。
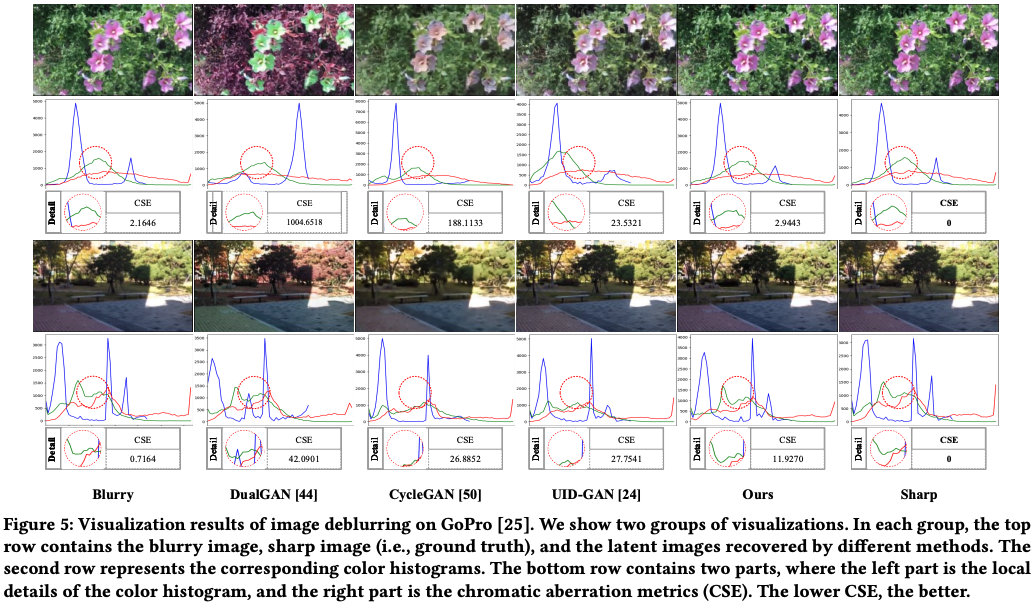
CRNet: Unsupervised Color Retention Network for Blind Motion Deblurring (2021)より引用
Learned Perceptual Image Patch Similarity (LPIPS)
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric (2018)で提案された、学習済み画像分類ネットワーク(例:AlexNetやVGG)の学習済み画像分類器の一部の層を用いて抽出された特徴量を用いた知覚的品質評価の指標です。リファレンス画像との特徴量の差を比較し、スコアは0から1の間で表され、0に近いほど知覚品質が高いことを示します。以下に示すように、一般的に先述のPSNRやSSIMは、過度に平滑化された画像などでも品質が高い結果を出しますが、この指標はより人の知覚に近い結果を得ることができるようです。
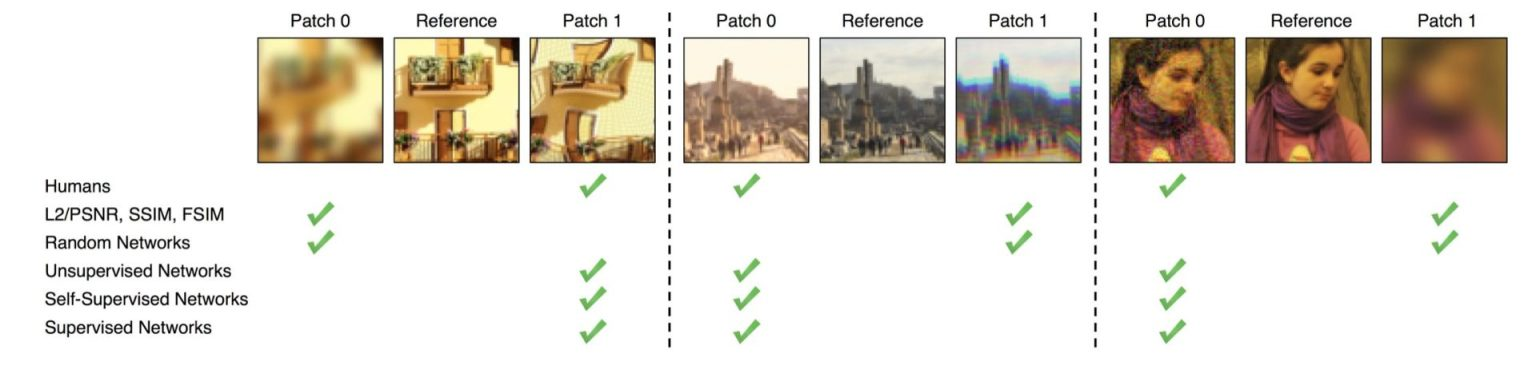
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric (2018)より引用
ブレ除去の研究では、Deblurring via Stochastic Refinement (2022)で使われています。
Frechet Inception Distance (FID)
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium (2017)で提案された、生成モデルが生成した画像と本物の画像との品質の違いを評価する指標です。FIDは、生成された画像と本物の画像の平均・分散を比較することで、本物の画像にどの程度近いかを計算します。
詳しくは、以下の記事が参考になります。
ブレ除去の研究では、LPIPSでも紹介したDeblurring via Stochastic Refinement (2022)で使われています。
リファレンス画像不要な指標
Natural Image Quality Evaluator (NIQE)
Making a “completely blind” image quality analyzer (2012)で提案された、リファレンス画像不要な客観評価指標で、画像の自然さをNatural Scene Statistics(NSS)を用いて評価します。NIQEの値が小さいほど、知覚的品質が良いことを示します。NIQEの得られるスコアは、後述のBRISQUEと異なり人間の感知する画質と相関しないというトレードオフがあります(参考:https://jp.mathworks.com/help/images/train-and-use-a-no-reference-quality-assessment-model.html)。
ブレ除去の枠組みでは、一般的に使用され、例えば以下で使われています。
FCL-GAN: A Lightweight and Real-Time Baseline for Unsupervised Blind Image Deblurring (2022)より引用
Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE)
No-Reference Image Quality Assessment in the Spatial Domain (2012)で提案された、リファレンス画像不要な客観評価指標で、NIQEと同様NSSを用いて画像の歪みの程度を評価します。BRISQUEは、NSSの特徴量を抽出し、サポートベクター回帰によりスコアを算出します。BRISQUEの値が小さいほど、知覚的品質が良いことを示します。以下がその一例です。

A domain translation network with contrastive constraint for unpaired motion image deblurring (2023)より引用
詳しくは、以下の記事が参考になります。
Mean Opinion Score (MOS)
主観的な評価指標の一つとしてMOSがあり、人間が画像の品質を1~5の5段階で評価しその平均点を用いる方法です。ブレ除去においても使われることがあり、MOSの値が5に近いほど良いモデルになります。以下がその一例です。

No-Reference Quality Assessment of Deblurred Images Based on Natural Scene Statistics (2017)より引用
DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better (2019)で使われているように、MOSと類似した指標としてAverage subjective scoresがあります。特にこのスコアの決め方については書かれていないですが、おそらくブレ画像を1としたときの主観的なスコアの平均を取るものと予想できます。

DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better (2019)より引用
Liu's metrics
A No-Reference Metric for Evaluating the Quality of Motion Deblurring (2013)で提案された、ユーザーからの画像の評価値を使い、ロジスティック回帰を用いて作成された評価指標です。
ブレ除去手法では、Robust Blur Kernel Estimation for License Plate Images from Fast Moving Vehicles (2016)で使われています。
ブレ除去画像の後続タスクでの評価指標
Character Error Rate (CER)
文章やナンバープレートのブレ除去の場合、Optical Character Recognition(OCR)の識字率のエラーとしてCERが使われることがあり、CERが小さいほど良いモデルになります。以下の上がブレ除去の結果で、下がそのCERです。

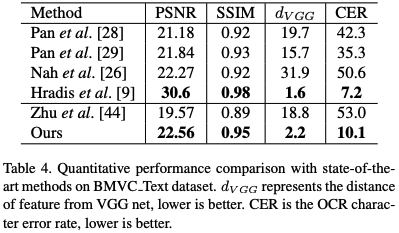
Unsupervised Domain-Specific Deblurring via Disentangled Representations (2022)より引用
You Only Look Once (YOLO)
ブレ除去した画像に対して学習済み物体検知モデルを用いて、物体検知精度の評価からブレ除去度合いを評価する方法もあります。
以下のように学習済みのYOLOを用いてモデルのブレ除去画像の精度を視覚的に比較できます。

DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks (2018)より引用
YOLOの認識精度での評価の場合、リファレンス画像は不要ですが、リファレンス画像を用いる場合、下図のようにシャープ画像のbounding boxを真(リファレンス)として、mean Average Precision(mAP)で評価することができます。
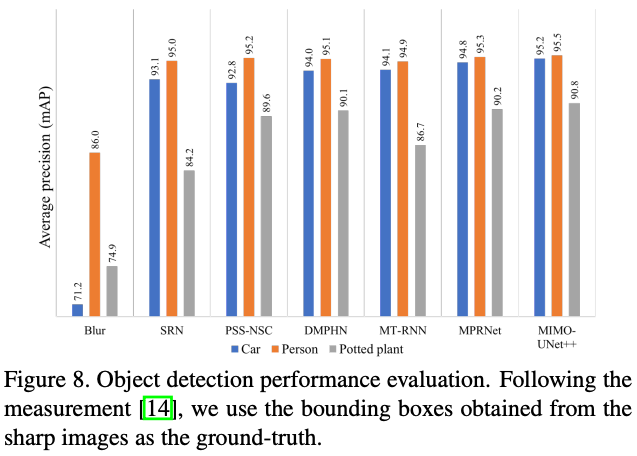
Rethinking Coarse-to-Fine Approach in Single Image Deblurring (2021)より引用
推論速度
deblurモデルの性能は、ブレ除去画像の再現度でなく、推論速度を重視することもあります。
推論速度はモデルの他、計算機のスペックにも依存しますが、 Video Deblurringであれば、リアルタイム処理が可能かのオーダーとして使われることがあります。
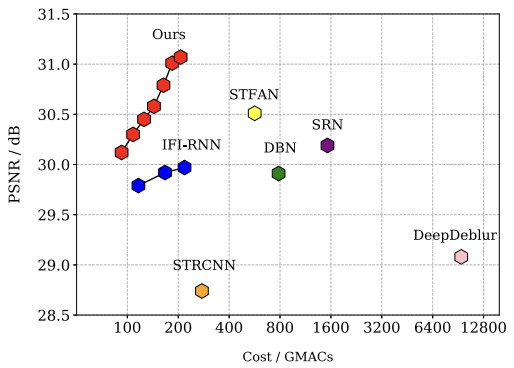
下図では、100枚のHD画像を処理する時間を示しています。この表から、「Ours」の結果では、HDの10FPS程度の動画であればリアルタイム処理が可能であることがわかります。
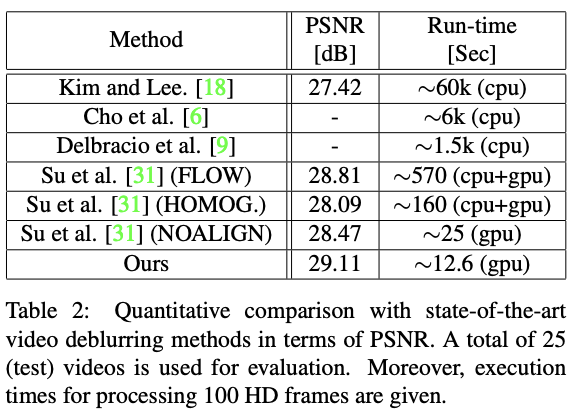
Online Video Deblurring via Dynamic Temporal Blending Network (2017)より引用
推論コスト
推論速度は、CPUやGPU性能に依存してしまうため、演算回数自体を指標とするほうが、論文を跨いで横並びでモデルを評価する際に有効です。
推論コストの指標として、Floating Operations Per Second(FLOPS)やGiga Floating Operations Per Second(GMACs)を用いることがあります。
下図の2つの図のように、横軸に推論コスト、縦軸に推論精度を取ることで、モデルの性能を視覚的に理解しやすくなります。
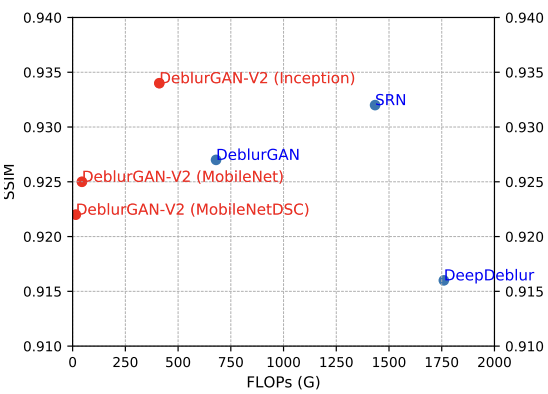
DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better (2019)より引用
Real-World Video Deblurring: A Benchmark Dataset and an Efficient Recurrent Neural Network (2023)より引用
パラメータ数
モデルの性能を測る指標としてパラメータ数もあり、ブレ除去手同じ精度がある場合はパラメータ数が少ない方が、学習データ量も減り、推論速度も早くなる傾向があります
下図の右ではパラメータによる性能の評価をしています。
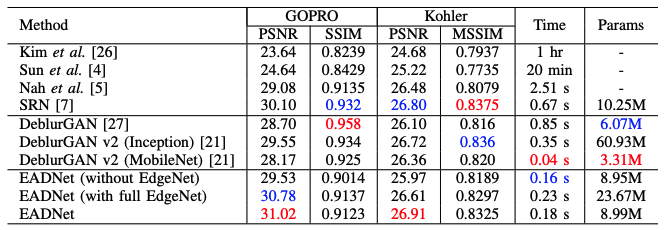
Edge-Aware Deep Image Deblurring (2020)より引用
Single-Image Deblurring サーベイ
この章では、画像のDeblurringに関する手法を2023年8月時点でサーベイしたものをまとめます。
以下の軸で整理しました。
- 局所ブレ対応できるか:局所ブレに対応できるような工夫があるかの分類
- 学習データの集めやすさ:同一シーンのペア画像が必要か、類似シーンで良いかによる分類
- 画像のクオリティ:結果的に得られたブレ除去画像での性能評価指標(評価に用いた画像は論文内で異なる)
- 学習時の画像枚数:モデルの性能を発揮するための目安として論文内で使用された学習時の画像枚数を記載
- 手法の引用数:流行している手法かの判断として論文の引用数を記載
- Codeの有無:手法で使われたCodeが提供されているか
| 研究 | 局所ブレに対応できるか | 学習データの集めやすさ (⚪︎:同一シーン対必須、×:類似シーン対でOK) |
画像のクオリティ | 学習時の画像枚数 | 手法の引用数 (※2023/08 時点) |
Codeの有無 | |
|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | ||||||
| Edge-Aware Deep Image Deblurring (2022) | ⚪︎(エッジに関するlossを使用) | × | 30.78 | 0.914 | ~2,000 | 14 | × |
| Edge Prior Augmented Networks for Motion Deblurring on Naturally Blurry Images (2021) | ⚪︎(エッジに関するlossを使用) | × | 31.42 | 0.964 | ~9,000 | 2 | × |
| GAN-Based Image Deblurring Using DCT Loss With Customized Datasets (2021) | × | × | 34.15 | 0.964 | ~26,000 | 8 | ⚪︎ |
| Rethinking Coarse-to-Fine Approach in Single Image Deblurring (2021) | ⚪︎(マルチスケール画像を入力) | ⚪︎ | 33.68 | 0.959 | ~6,000 | 233 | ⚪︎ |
| Deblurring via Stochastic Refinement (2022) | × | × | 33.23 | 0.963 | ~2,000 | 69 | × |
Edge-Aware Deep Image Deblurring (2022)
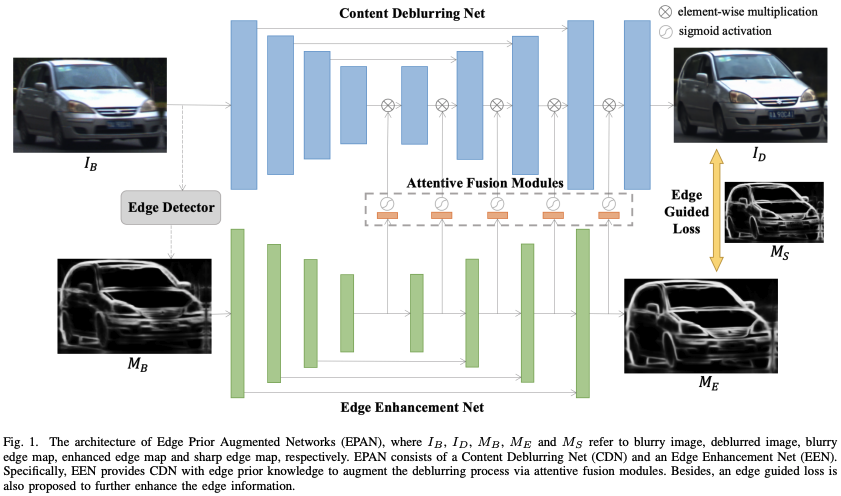
Fu et al. (2022)によって開発されたブレ画像のエッジに関する情報も含めてブレ除去を試みた手法です。
具体的には、ブレ画像のRGB画像に加え、ブレ画像のエッジ検出した画像を加えた4チャンネルをdeblurモデルの入力として使うというものです。ただし、ブレ画像の場合エッジ検出は、ブレの程度依存があり、古典的なCanny法などでは、適切な閾値が画像毎に異なってしまう問題があり、Xie et al. Holistically-nested edge detection (2015)のdeep learningモデルを使って検出したエッジ画像を使っています。エッジに関する情報をブレ除去した画像で行う研究は多いですが、ブレ画像のエッジは稀で個人的には面白い手法だと思いました。
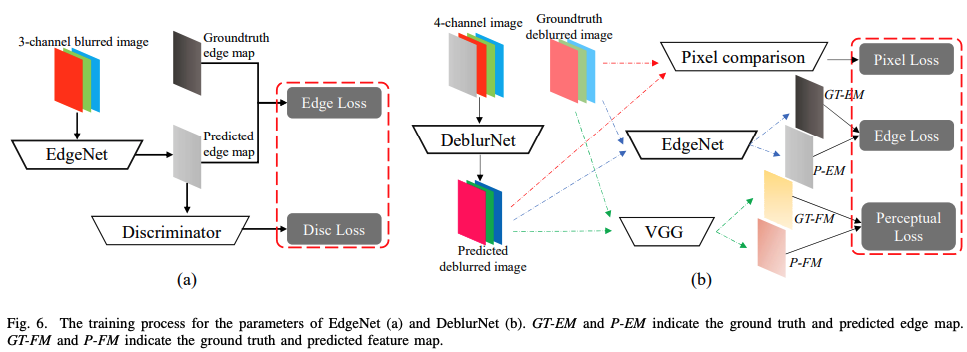
Edge Prior Augmented Networks for Motion Deblurring on Naturally Blurry Images (2021)
ブレ除去するGANに加え、ブレ画像のエッジからシャープ画像のエッジを推定するEdge Enhancement NetのGANを用いることで、ブレの特徴を抽出しブレ除去する手法です。
GAN-Based Image Deblurring Using DCT Loss With Customized Datasets (2021)
Discrete Cosine Transform(DCT, 離散コサイン変換)をベースにした損失関数を用いたGANベースの手法です。
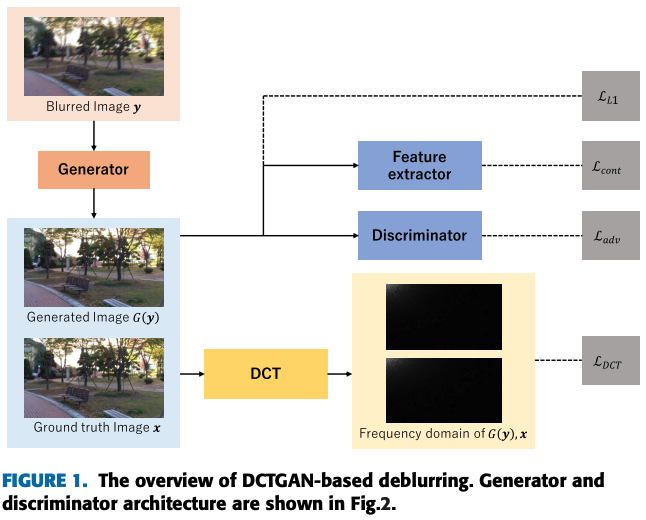
ここで、DCT lossを数式で以下のように定義します。
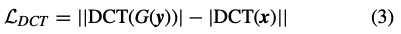
$x$はシャープ画像、$y$はブレ画像、$G(\cdot)$は生成器が生成した画像、$\textrm {DCT}(\cdot)$は、離散コサイン変換を表します。
このDCT lossをGANの生成器に加えることで、画像の周波数成分を直接比較することになり、生成器によって生成された余分な周波数成分を抑制することが期待されます。
著者は、DCTを用いた先行研究のMulti-Perspective Discriminators-Based
Generative Adversarial Network for Image Super Resolution (2019)を参考にしています。
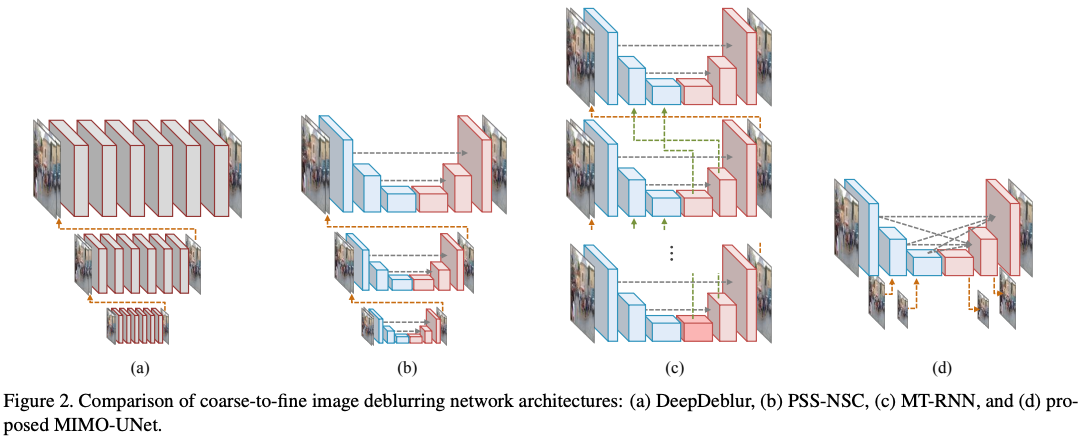
Rethinking Coarse-to-Fine Approach in Single Image Deblurring (2021)
U-Netをベースにし、マルチスケールのブレを低演算量で処理できる多入力多出力のネットワークMIMO-UNetを用いた手法です。この手法により、従来の他の手法に比べて、計算速度と精度ともに向上しています。
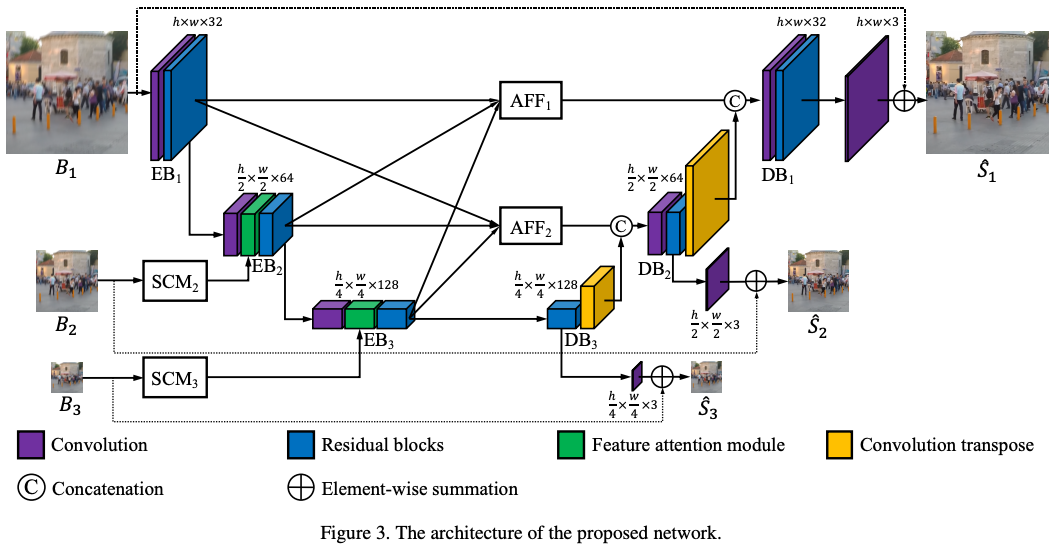
以下は、従来のマルチスケール画像を用いたモデルとのアーキテクチャの比較です。一番右が提案手法です。
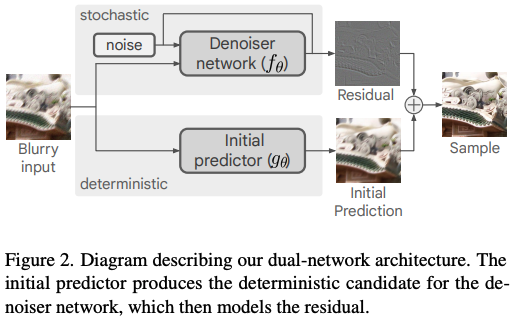
Deblurring via Stochastic Refinement (2022)
diffusion modelを使った手法です。
Video Deblurring サーベイ
| 研究 | 学習データの集めやすさ (⚪︎:同一シーン対必須、×:類似シーン対でOK) |
画像のクオリティ | 手法の引用数 (※2023/08 時点) |
Codeの有無 | |
|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | ||||
| Online Video Deblurring via Dynamic Temporal Blending Network (2017) | × | 29.11 | 記載なし | 157 | × |
| Recurrent Neural Networks with Intra-Frame Iterations for Video Deblurring (2019) | × | 29.97 | 0.895 | 119 | × |
| Adversarial Spatio-Temporal Learning for Video Deblurring (2018) | × | 33.19 | 記載なし | 134 | × |
| Video Deblurring via Spatiotemporal Pyramid Network and Adversarial Gradient Prior (2021) | × | 32.30 | 0.940 | 27 | × |
| Recurrent Video Deblurring with Blur-Invariant Motion Estimation and Pixel Volumes (2021) | × | 28.79 | 0.907 | 41 | ⚪︎ |
| Real-world Video Deblurring: A Benchmark Dataset and An Efficient Recurrent Neural Network (2023) | × | 31.95 | 0.926 | 5 | ⚪︎ |
Online Video Deblurring via Dynamic Temporal Blending Network (2017)
複数の連続フレームから逐次的にブレ除去ができる手法です。
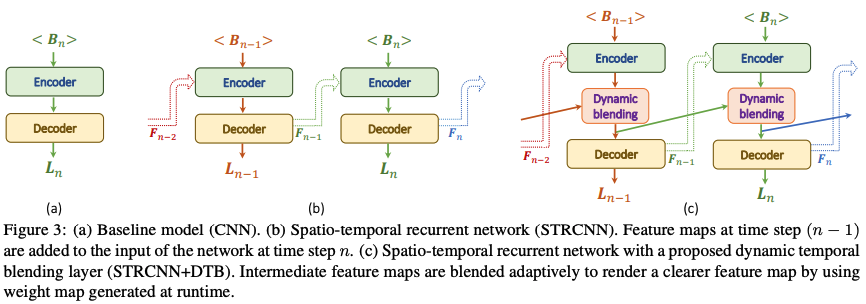
この手法は上図の(C)のように、前のフレームの情報を隠れ層を介して伝搬して実装するため、全ての時系列の情報を効率的に取り込めるようになり、高速な処理を可能にしています。下図がその詳細になります。
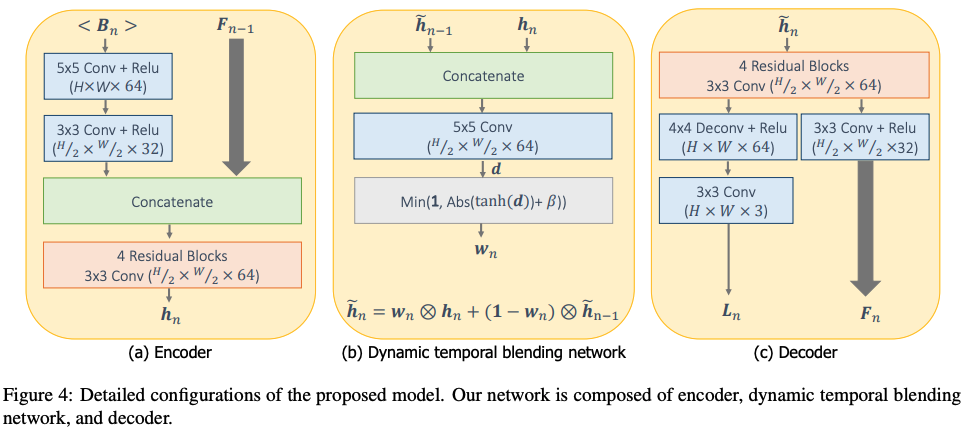
上図の$W_n$が伝搬の重みで画素単位で用意し、Dynamic blending層でこの重みを制御しています。
Recurrent Neural Networks with Intra-Frame Iterations for Video Deblurring (2019)
連続するフレーム間の時系列情報を取り込むため、RNNをベースにした手法です。
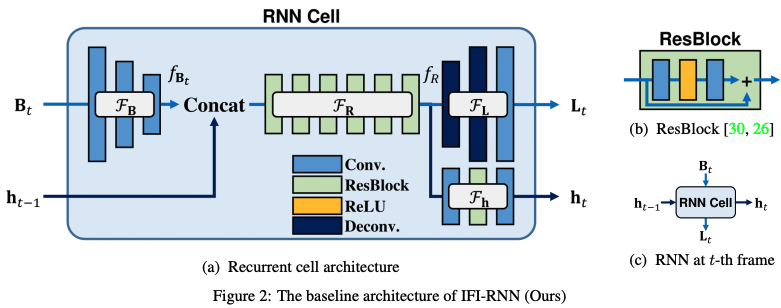
下図(b), (c)のようCNNの隠れ層の一部の接続を確率的にDropoutして学習することで性能の向上を図っています。

Adversarial Spatio-Temporal Learning for Video Deblurring (2018)
Zhang et al. (2018)によって開発された連続する5枚の画像の情報を使ってブレ除去する手法です。loss関数は、ピクセル間lossと識別器のlossです。
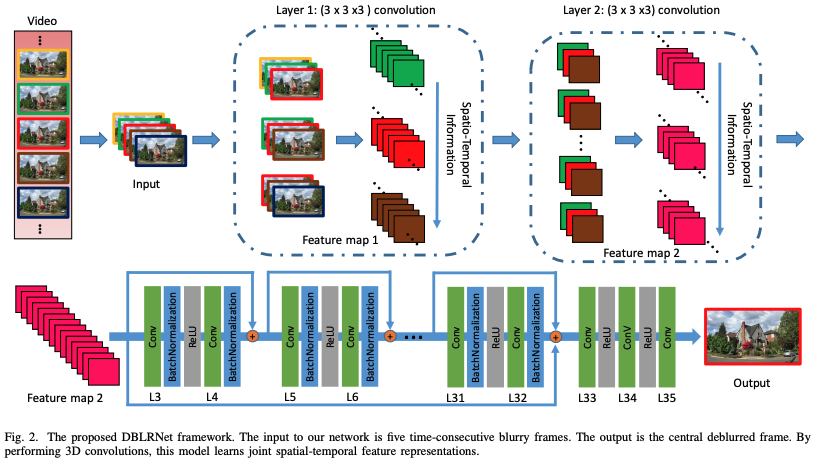
補足ですが時系列情報を保持するために、3D convolutionを用いています。以下が2D convolutionと比較した概念図です。
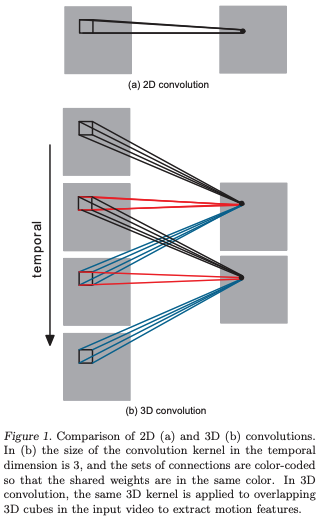
(3D Convolutional Neural Networks for Human Action Recognition (2012)より引用)
Video Deblurring via Spatiotemporal Pyramid Network and Adversarial Gradient Prior (2021)
連続する5枚の画像情報を用いて、さまざまな時間スケールの情報を抽出するために、1、3、5枚の画像に分割して推論する手法です。
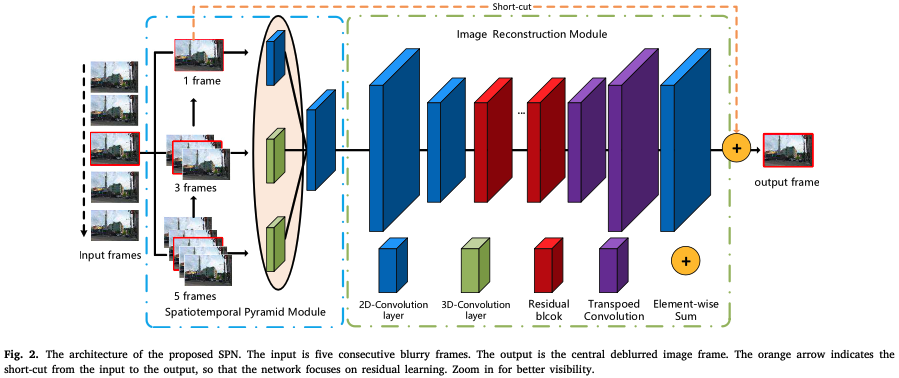
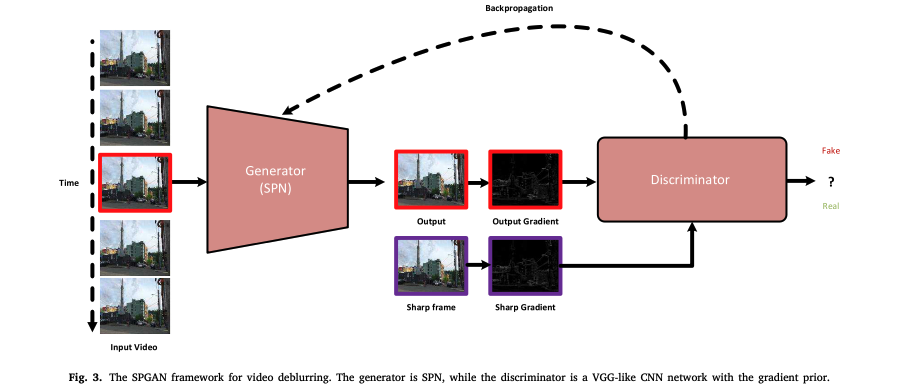
この手法は、ブレ画像とシャープ画像の勾配の性質が異なることに基づき、ブレ除去画像での識別器のlossは画像自身でなく、その勾配画像を使用している点が独創的です。画像自身と勾配画像のどちらが良いかは議論の余地があると思いますが、この論文では以下の図を使い勾配の利点を主張しています。
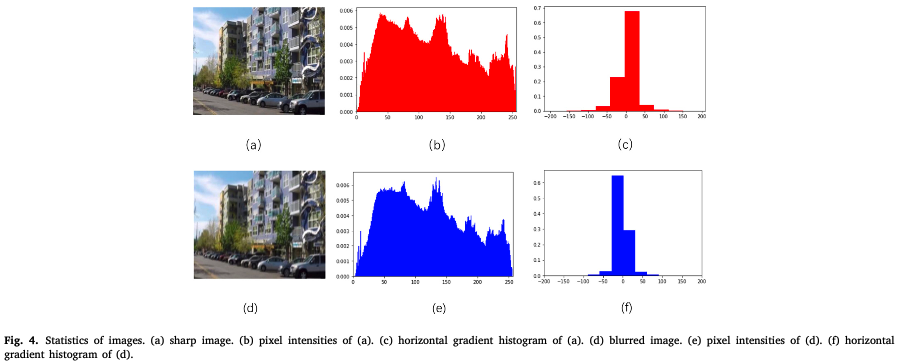
上図の上段左からシャープ画像、輝度ヒストグラム、水平方向の勾配のヒストグラムで、下段は同様にそのブレ画像での結果です。一番右の図を比較すると、ブレ画像ではヒストグラムが0付近に集中していて、シャープ画像との違いが勾配情報からわかるということです。
Recurrent Video Deblurring with Blur-Invariant Motion Estimation and Pixel Volumes (2021)
Opitical flowとPixel Volume Constructionという3次元の特徴マップを用いた手法です。
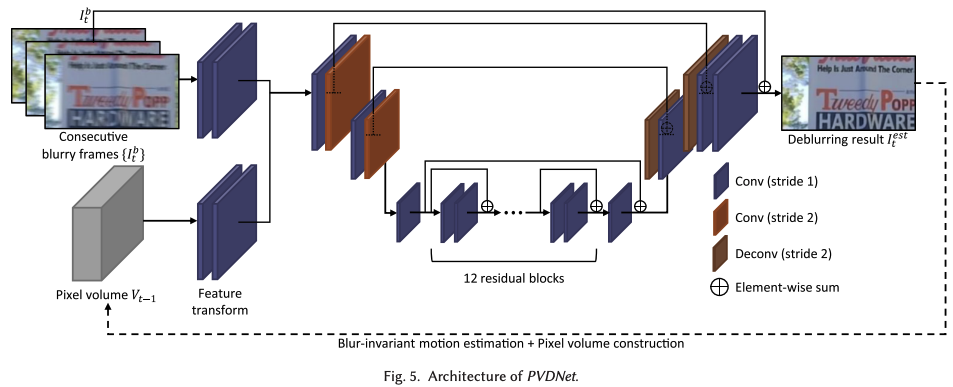
この手法では、ブレ画像の連続画像からOptical flowを推定することを行なっています。しかし、一般的なdeep learningのOptica flow手法では、鮮明な画像を用いて学習されているため、ブレ画像では精度が出ないです。そこで、既存のモデルで学習されたモデルを用いて自己教師あり学習でブレ画像での精度を向上させています。具体的には、ブレ画像とシャープ画像のペアを使って、既存のモデルを使ってシャープ画像のOpitcal flowを計算し、その結果を教師データとして、ブレ画像で学習します。このようにすることで、学習コストを抑えつつ精度向上を図っています。
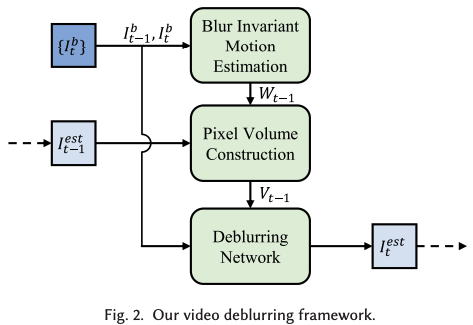
ただし、Optical flowの結果だけでは、精度が振るわないため、Pixel Volume Constructionと呼ばれる複数のピクセルの情報を使って移動量を計算しています。下図がその概念図で、ある赤のピクセルにおけるflowを算出するとき、周辺のピクセルの先flowの結果を統合して扱うことで、ロバスト性を向上させるといったイメージです。
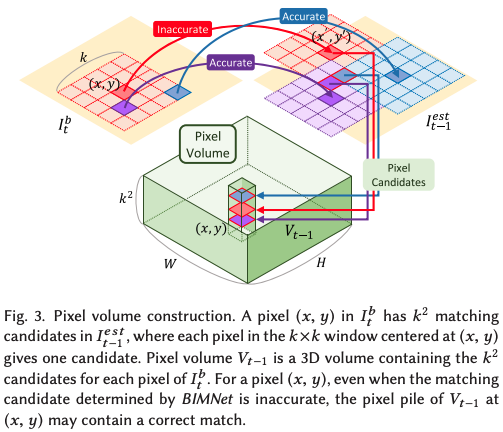
Real-world Video Deblurring: A Benchmark Dataset and An Efficient Recurrent Neural Network (2023)
連続する5枚のフレームから、RNNベースでResidual dense block (RDB) cell、Global average pooling (GAP) fusionを用いた手法です。
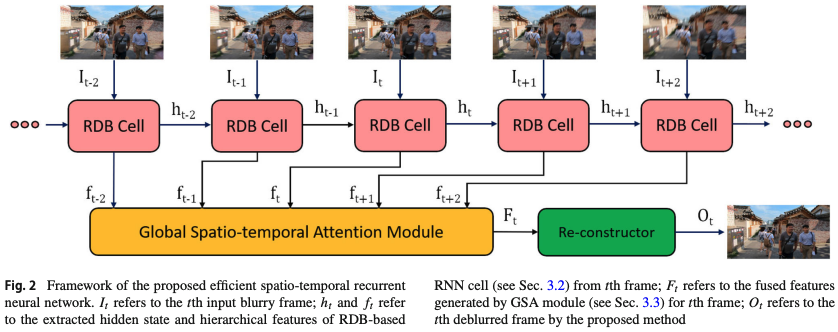
この手法は、本物のブレ画像シャープ画像で学習データ(BSD)の利用の有効性も示しています。
また、損失関数には、Charbonnier loss
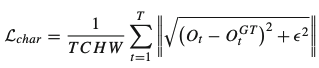
が使われ、$\epsilon\ll 1$の項が入ります。Charbonnier lossは、平方根内の第一項の差分が$\epsilon$より小さい場合はL2 lossのように振る舞い、一方で$\epsilon$より大きい場合はL1 lossのような挙動をします。
L1, L2, Charbonnier lossのどれがよいかは、学習データモデルなどの要因などもあり一概には言えないです。
Appendix
Single-Image Deblurringの古典的手法
Wiener deconvolution
Wiener deconvolutionは、ノイズを考慮した撮像画像を最適化された逆フィルタ$G(u,v)$(Wiener filter)で畳み込むことでシャープ画像を推定する手法です。
詳しくは以下がよくまとまっているのでご覧ください。
Richardson-Lucy deconvolution (1972, 1974)
Richardson-Lucy deconvolution(RL法)は、ベイズ推定によって反復的にシャープ画像を推定する手法です。
詳しくは以下をご覧ください。
この手法の通常一つのPSFを用いることが多いですが、場所毎の複数のPSFを取り込んだ場所依存型のRL法もあります (e.g., Richardson-Lucy Deblurring for Scenes underProjective Motion Path (2010))。
Blind Image Deblurring Using Dark Channel Prior (2016)
ブレ画像とシャープ画像を局所領域毎に平均化したときの輝度の暗いピクセルの分布の特性に基づいて、シャープな画像を推定する手法です。
Image Deblurring via Extreme Channels Prior (2017)
Blind Image Deblurring Using Dark Channel Prior (2016)が暗い輝度値に着目していましたが、この手法では明るい輝度分布を基にして推定する手法です。