はじめに
今回、大きく下記3つに取り組みました。
1. バナナの画像から食べごろを分類する機械学習モデルの作成
2. Flaskを利用して上記で作成したモデルを利用したWEBアプリの作成
3. AWS EC2インスタンスを利用したWEBサーバ構築〜アプリ公開
背景
私は美味しいバナナを食べるために、いわゆるシュガースポットと呼ばれる黒い斑点の量をもとに食べ頃を判断しています。下記のような写真が美味しそうなバナナと捉えていますが、同じように考えている人も多いのではないかと思います。

ただし、このシュガースポットが増えるのを待っている間にバナナが腐ってしまう場合もあるため、今後そのようなことがないようにバナナの最適な食べ頃を判定する機械学習モデルを作成することにしました。
WEBアプリ「Banana Classification」
先に実装したWEBアプリをご紹介します。
-
WEBアプリ
Banana Classification(app)
※都合によりWEBサーバを落としている場合があります。
※判定結果によって発生した腹痛など、もろもろの責任は負いかねます。
イメージ
-
初期画面
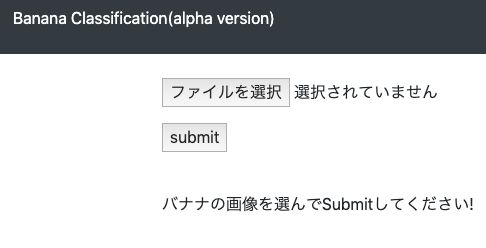
-
分類後
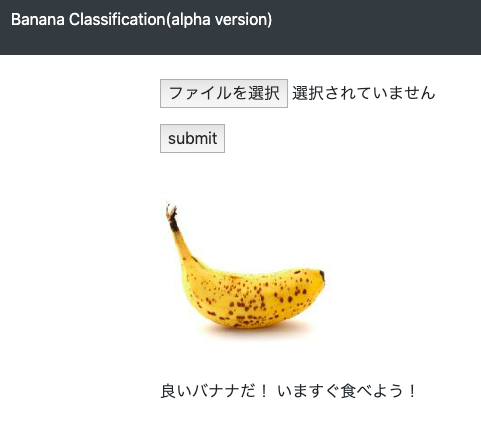
機能
- バナナの画像をアップロードすることにより、バナナが食べ頃かどうかを分類します。
- 「未熟なバナナだ。もう少し待とう!」
- 「良いバナナだ! いますぐ食べよう!」
- 「危険なバナナだ! 捨てるか、覚悟して食べよう!」
- バナナ以外の画像がアップロードされた場合、「バナナではない」と分類します。
- 「これはバナナではない!」
バナナについて
上記の機械学習モデルを作成するに当たり、まずは実際にどのようなバナナが美味しいのかを調査しました。ここは人の好みにもよるところでもあるため、今回は私のこれまでのバナナ経験と糖度計を利用して糖度を測りながらバナナの食べ頃を判定しました。
利用した糖度測定器

計測している様子

2日おき間隔で計測を行いましたが、そこまで明確な差が見て取れなかったため、あくまで参考情報として、最終的には自分の舌でバナナの食べ頃かどうかを判断し、データセットを作成していきました。その他にも、ネット上に転がっているバナナ画像も合わせてデータセットに加えていき、全体で300枚程度のデータセットを作成しました。
バナナブームの調査
先日、とあるテレビ番組でもバナナジュースをテーマに取り上げられており、昨今話題になったタピオカドリンク並のブームがやってくるのではないかと推測します。
都内でも多くはないものの、バナナジュース専門店がいくつかあり、今回のアプリ作成にあたり、調査も兼ねてバナナジュースを飲んできました。
バナナジュース専門店「BANANA JUICE」(東銀座)
こちらのお店は平日しか営業しておらず、さらにはバナナが完熟してない日にはお店をオープンしないとのこと。
今回平日のオープン12:00に合わせてお店に到着したが、すでにこの行列。

30分ほど並び、ようやくバナナジュースにたどり着くことができました。

オリジナルのバナナジュースLサイズで340円(Mサイズは260円)とお手軽な価格設定。このバナナジュースはバナナと牛乳のみで砂糖は入っていないとのこと。それでもバナナの甘味を十分に感じることができるとても美味しいジュースでした。
取り組み内容について
モデル、アプリ、インフラの詳細を記載していきます。いろいろな記事や書籍を参考にしましたので、参考にしたものも合わせて紹介します。
1. バナナの画像から食べごろを分類する機械学習モデルの作成
1-1.概要
下記にてモデル作成を行いました
- ディレクトリ配下に下記4クラス分の画像をそれぞれ約100枚ずつ準備
- 1.early
- 2.just
- 3.late
- 4.dammy
- kerasからimagenet学習済みのVGG16モデルを利用(出力層側の全結合層は含まず)
- 'block5_conv1'層以降を解凍し、それと新たに追加した全結合層にて4値分類での学習を実施
- AWS EC2インスタンス(p2.xlarge)にて約5分で学習完了
1-2.学習用コード
# モジュールインポート
import numpy as np
import matplotlib.pyplot as plt
import os
from keras import layers
from keras import models
from keras.models import load_model
from keras import optimizers
from keras import backend as K
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
K.clear_session()
# VGG16、imagenet学習済みモデルの読み込み
conv_base = VGG16(
include_top=False,
weights='imagenet',
input_tensor=None,
input_shape=(224,224,3),
pooling=None,
classes=1000
)
# モデルの構築
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(4, activation='softmax'))
# 学習対象レイヤーの解凍
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
# データセットの水増し
train_datagen = image.ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = image.ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
directory='./data/train',
target_size=(224, 224),
batch_size=10,
class_mode='categorical'
)
val_generator = test_datagen.flow_from_directory(
directory='./data/validation',
target_size=(224, 224),
batch_size=10,
class_mode='categorical'
)
# モデルのコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc']
)
# モデルの学習
history = model.fit_generator(
train_generator,
steps_per_epoch=500,
epochs=10,
validation_data=val_generator,
validation_steps=10
)
# モデルの保存
model.save('banana2.h5')
2. Flaskを利用してWEBアプリの作成
WEBアプリの知識がないため、他の記事等をかなり参考にしました。
2-1.ディレクトリ構成、ファイル内容
ローカルで作成した際のディレクトリ構成です。下記をもとに作成しました。
Flaskで簡単につくる、画像処理した結果を見るだけのWebサービス
banana/
┣api/
┃ ┣images/(upload画像保存用ディレクトリ)
┃ ┣templates/
┃ ┃ ┣index.html
┃ ┃ ┗layout.html
┃ ┗server.py
┗banana2.h5(重みファイル)
2-2.実装部分
(1)server.py
from flask import Flask, render_template, request, redirect, url_for, send_from_directory
import numpy as np
import os
import string
import random
import tensorflow as tf
import keras
from keras.preprocessing import image
from keras.applications.vgg16 import decode_predictions
# 美味しいバナナかどうかを判定するモデル
model = keras.models.load_model('../banana2.h5')
model._make_predict_function()
graph = tf.get_default_graph()
category = np.array([
'未熟なバナナだ。もう少し待とう!',
'良いバナナだ! いますぐ食べよう!',
'危険なバナナだ! 捨てるか、覚悟して食べよう!',
'これはバナナではない!'
])
SAVE_DIR = "./images"
if not os.path.isdir(SAVE_DIR):
os.mkdir(SAVE_DIR)
message = 'バナナの画像を選んで送信してください!'
app = Flask(__name__, static_url_path="")
def random_str(n):
return ''.join([random.choice(string.ascii_letters + string.digits) for i in range(n)])
@app.route('/')
def index():
return render_template(
'index.html',
message=message
)
@app.route('/images/<path:path>')
def send_js(path):
return send_from_directory(SAVE_DIR, path)
# 参考: https://qiita.com/yuuuu3/items/6e4206fdc8c83747544b
@app.route('/upload', methods=['POST'])
def upload():
if request.files['image']:
# 画像として読み込み
stream = request.files['image'].stream
# ファイル名を読み込み
filename = (request.files['image']).filename
original_path = './images/' + filename
# model読み込み用に画像ファイルを変換
img = image.load_img(stream, target_size=(224, 224))
x = image.img_to_array(img)
#一回保存
image.save_img(original_path, x)
x = np.expand_dims(x, axis=0)
# これをしないとpredict時にエラーになる
# https://github.com/keras-team/keras/issues/10431
global graph
with graph.as_default():
preds = model.predict(x)
message = category[np.argmax(preds)]
print(message)
return render_template(
'index.html',
message=message,
filename=original_path
)
if __name__ == '__main__':
app.debug = True
app.run(host='0.0.0.0', port=8888)
(2)index.html
{% extends "layout.html" %}
{% block content %}
<form action="/upload" method="post" enctype="multipart/form-data">
<input type="file" name="image" accept="image/png, image/jpg">
<p></p>
<button type="submit">送信</button>
※ボタン押下後、しばらくお待ち下さい
</form>
<div>
<img src="{{ filename }}" style="margin-top: 10px; vertical-align: bottom; width: 200px;">
<p></p>
{{ message }}
</div>
{% endblock %}
(3)layout.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Banana Classification</title>
<!-- BootstrapのCSS読み込み -->
<link rel='stylesheet' href='https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/css/bootstrap.min.css'>
<style type="text/css">body {padding-top: 80px;} p {color: #fff;}</style>
</head>
<body>
<nav class='navbar navbar-expand-md navbar-dark bg-dark fixed-top'>
<p>Banana Classification(alpha version)</p>
</nav>
<div class='container'>
{% block content %}
{% endblock %}
</div>
</body>
</html>
2-3.実行時
- server.pyと同ディレクトリ内で下記コマンドを実行する
python server.py
- 起動完了後、下記にアクセスすると、ローカル上でのWEBアプリが開く
http://0.0.0.0:8888/
3. AWS EC2インスタンスを利用したWEBサーバ構築〜アプリ公開
全体像を絵にしてみました。
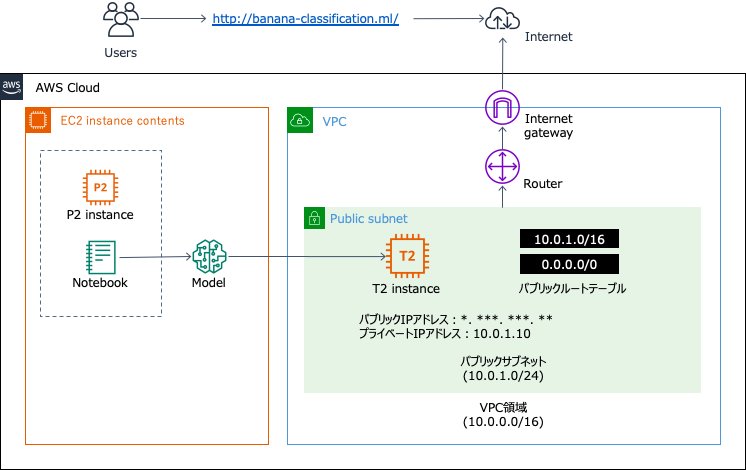
3-1.サーバ構築
AWSでのサーバ構築関しては、下記書籍を参考にしました。ので、詳細はここでは割愛。
Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版
特記事項
今回利用したインスタンスに関して、AWS無料利用枠のt2.microではメモリ不足(1GiB)でモデル読み込みが不可能であったため、t2.small(2GiB)を利用。これでもギリギリ。
3-2.インストール
(1)Python環境の作成
$ sudo yum -y update
$ sudo yum install python36-devel python36-libs python36-setuptools
$ mkdir banana
$ python -m venv banana
$ source banana/bin/activate
(2)ライブラリのインストール
今回必要なライブラリは下記の通り。
(banana)$ pip install --upgrade pip
(banana)$ pip install flask
(banana)$ pip install numpy
(banana)$ pip install tensorflow
(banana)$ pip install keras
(banana)$ pip install pillow
3-3.作成したモデルの実行
ここまでモデルとアプリを動かすためのファイルはローカル上にありますので、ターミナルを利用してサーバにアップロードします。
(1)アップロード
$ scp -i /User/keys/banana.pem banana2.h5 user@ec2-xxxx.com:/home/ec2-user/
(2)実行
(banana)$ nohup python server.py &
- Python環境作成時に新たに作成されたファイルを除き、ローカル上と同様のディレクトリ構造にする。
- server.pyと同ディレクトリにて下記を実行する
- sshログアウト後もpyファイルを実行するため、nohupを利用する
- 実行後、下記にアクセス可能なことを確認する
http://[パブリックIP]:8888/
3-4.独自ドメインの作成・設定
(1)パブリックIPアドレスを固定化する
インスタンスに割り当てられるパブリックIPアドレスは、起動・停止するたびに別のIPアドレスが割り当てられます。今回のこのIPアドレスを固定化するためにAmazon EC2の「Elastic IP」という機能にて設定します。
【手順】
- Elastic IPメニューより新しいアドレスの割当を行う
- 確保したIPアドレスを作成済みのインスタンスに対してアドレスの関連付けを行う
(2)独自ドメインの取得
下記サイトにてほしいドメイン名が利用可能か検索の上、無料で購入。
- 利用サイト
Freenom - 誰でも利用できる名前
(3)パブリックIPアドレスと購入ドメインの紐付け
ここに記載の通り進めました。
AWS Route 53を使って独自ドメインのWebページを表示させてみよう
ここまでApacheを利用していなかったため、ここでインストールもしています。
Apacheとは?Webサーバーの仕組みと人気サーバーソフトを徹底解説
(4)プロキシパスの設定
設定したドメインからPythonで動かしている8888ポートにパスを設定しました。
- confファイルを修正する
$ sudo vi /etc/httpd/conf.d/vhost.conf
- 修正内容
NameVirtualHost *:80
DocumentRoot "/var/www/html/"
ServerName banana-classification.ml
ProxyRequests Off
ProxyPass / http://localhost:8888/
ProxyPassReverse / http://banana-classification.ml/
- httpd再起動
$ sudo service httpd restart
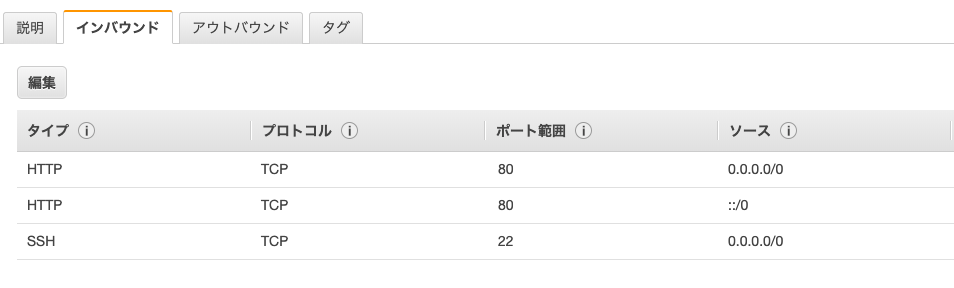
(5)8888ポートを閉じる
任意で指定していた8888ポートを閉じます。(セキュリティ上)
- AWSインスタンス設定画面よりセキュリティグループのインバウンドより、指定のポートを削除する。
まとめ
今回、機械学習モデルの作成・WEBアプリの作成・インフラ構築を一気通貫での開発を経験することができました。それぞれの技術レベルとしては深いものではないですが、ここからいろいろな応用によりさまざまなアプリ開発をたのしむことができるのではないかなと思います。今後もなにか機会があれば作って行きたいですね。