2023年7月25日にGAされたようです。本記事はプレビューの時に試してみた記事であるため、現在のGA版と仕様が異なる可能性がありますのでご注意ください。
やりたいこと
Glue StudioのデータソースでSnowflakeが選択できるようになったようです(2023/6/27時点でプレビュー、米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)のみ)。以前はカスタムコネクタを作成しなくてはなりませんでしたが、接続を作成すればGlue Studioの純粋な機能だけで接続してデータをロードできるようになりました。
これを使って、データをロードしてみようと思います。
前提条件
Snowflake側にDB、スキーマ、テーブルを作成しておきます。
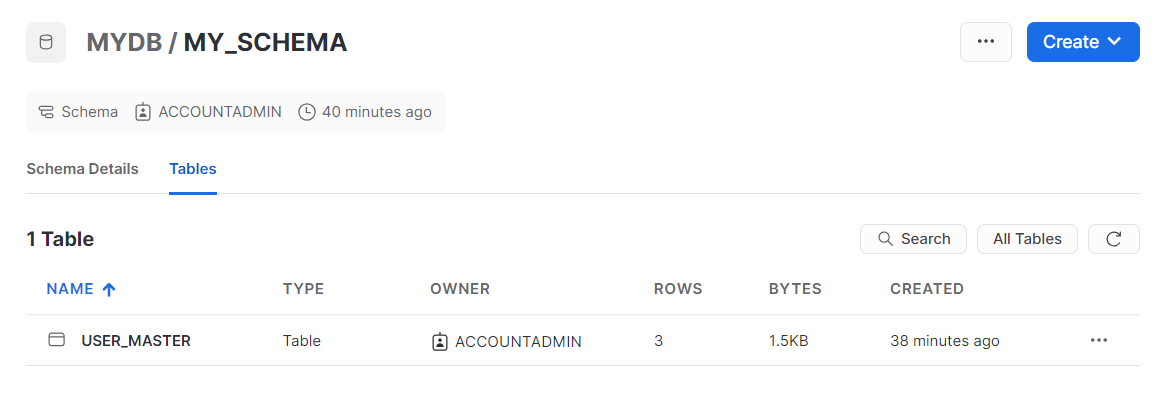
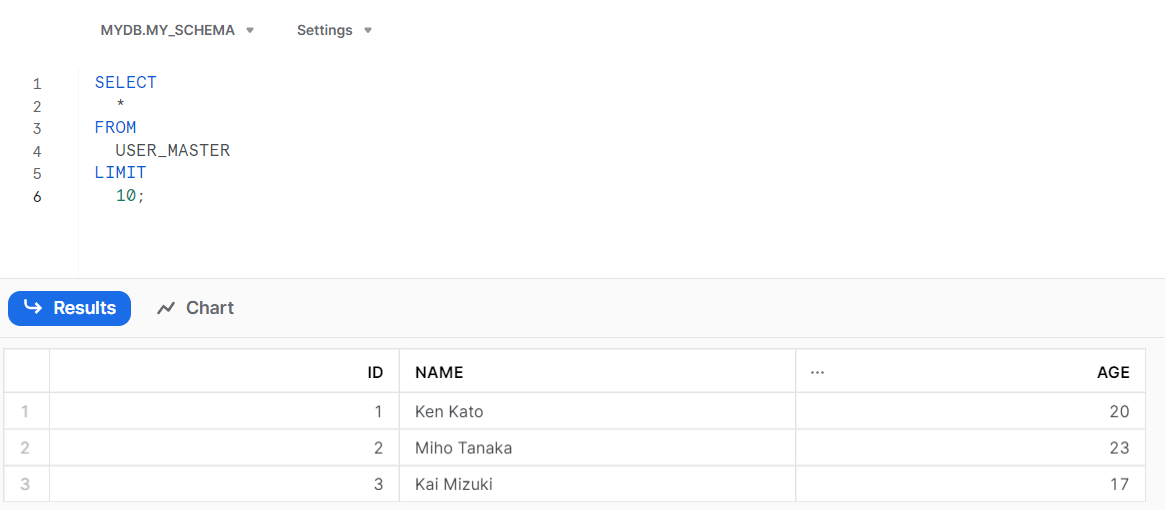
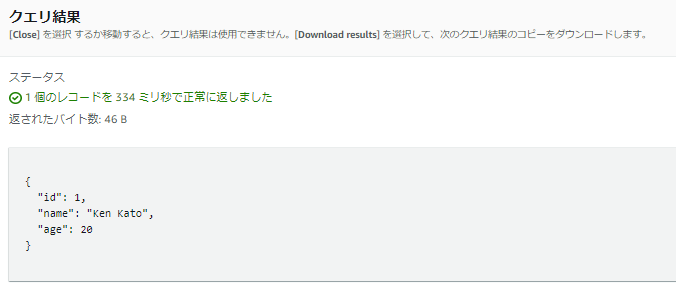
テーブルの中身は、この3行です。
また、AWSアカウントはプレビューのこの機能が利用できるバージニア北部リージョンで実施します。
やってみる
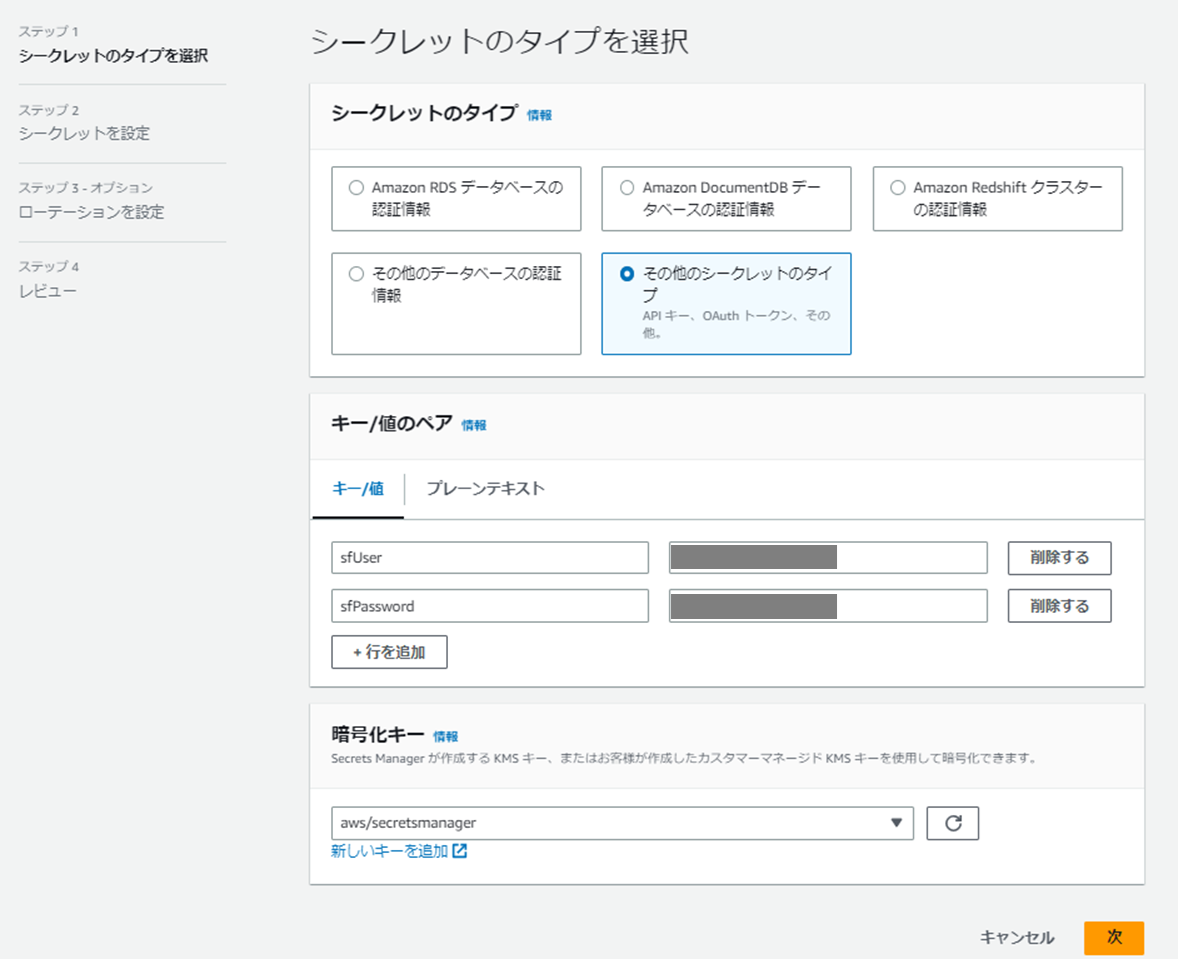
Secret Managerでシークレットの作成
Secret Managerで以下のようにシークレットを作成します。
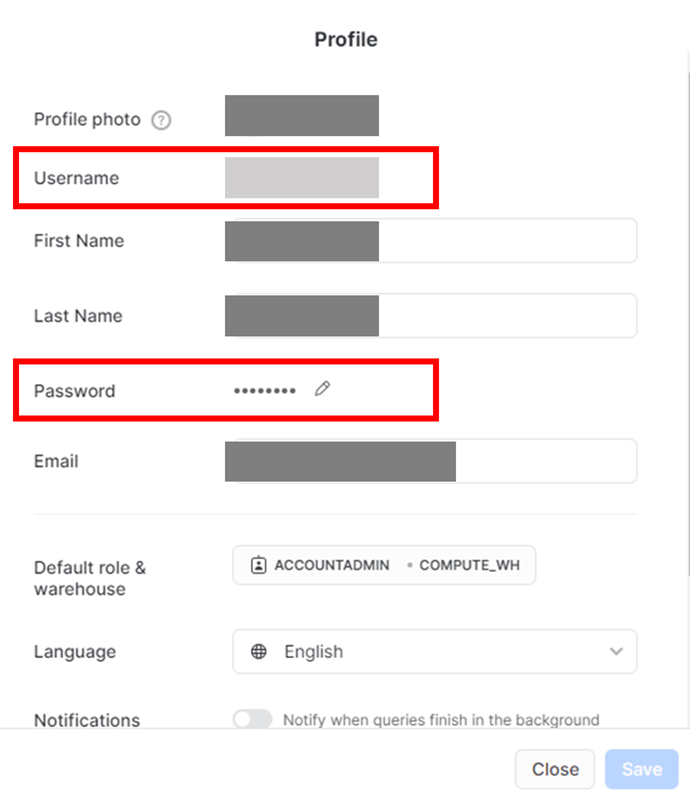
ユーザー名はsfUser、パスワードはsfPasswordがキーとなるので注意。公式ドキュメントに記載があります。
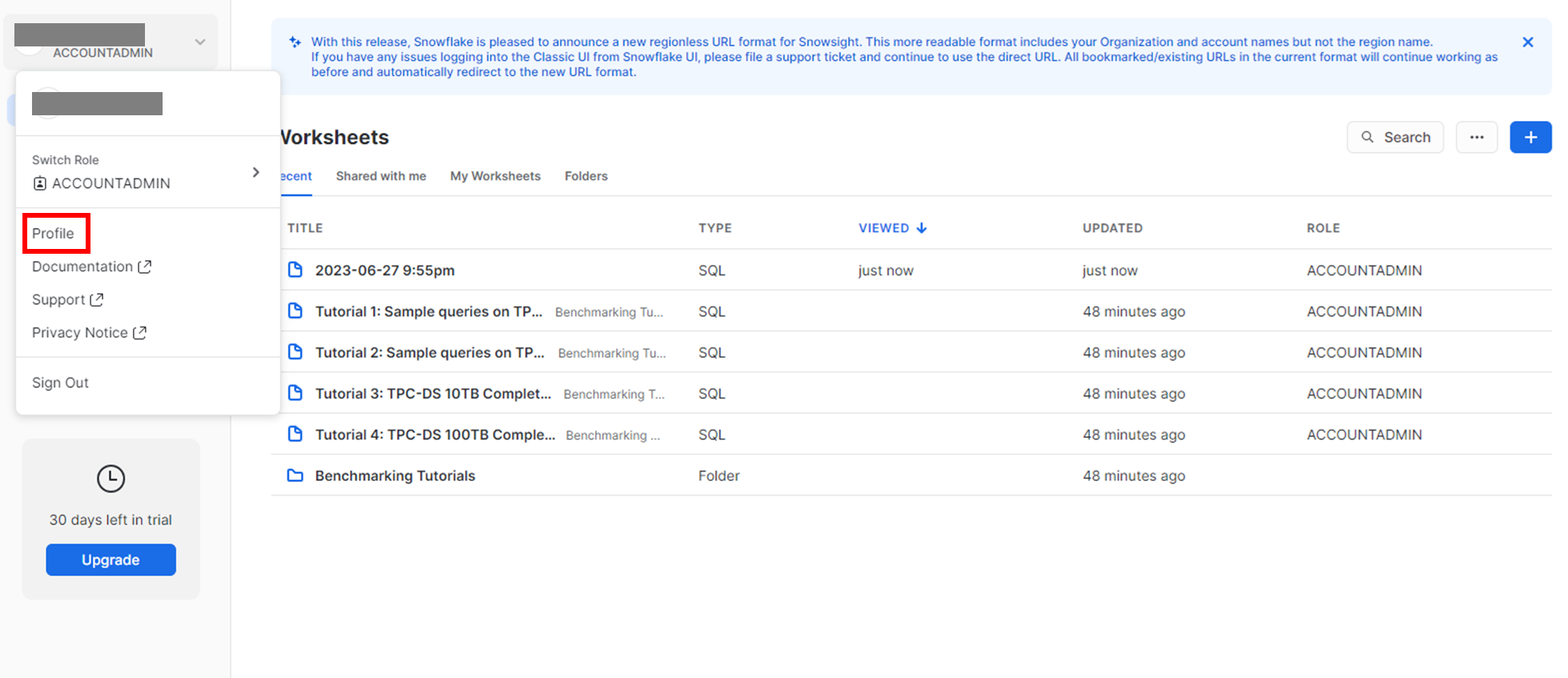
ユーザー名とパスワードですが、Snowflake側メインページの左上の自身のアイコン→Profile で確認できます。
Connectionの作成
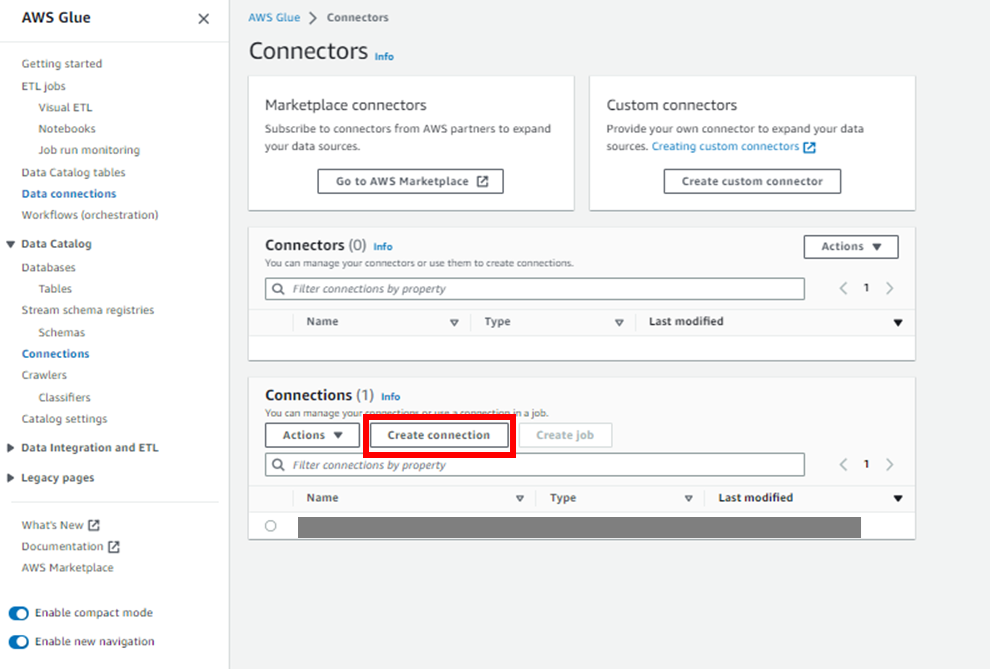
次は、GlueのコンソールからConnectionを作成します。
Connectorsのページから、「Create connection」をクリックします。
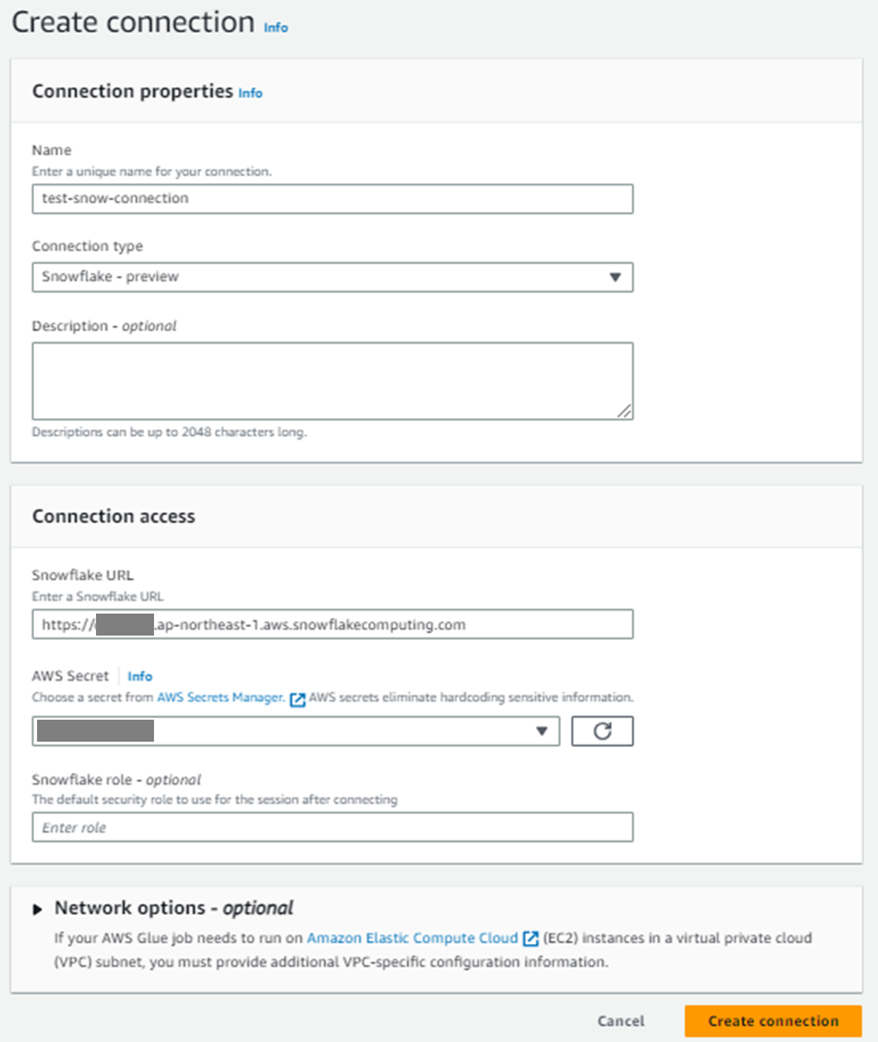
以下のように入力し、Connectionを作成します。
Connection typeのところが、今回のupdateで追加されたSnowflakeのコネクタータイプですね。
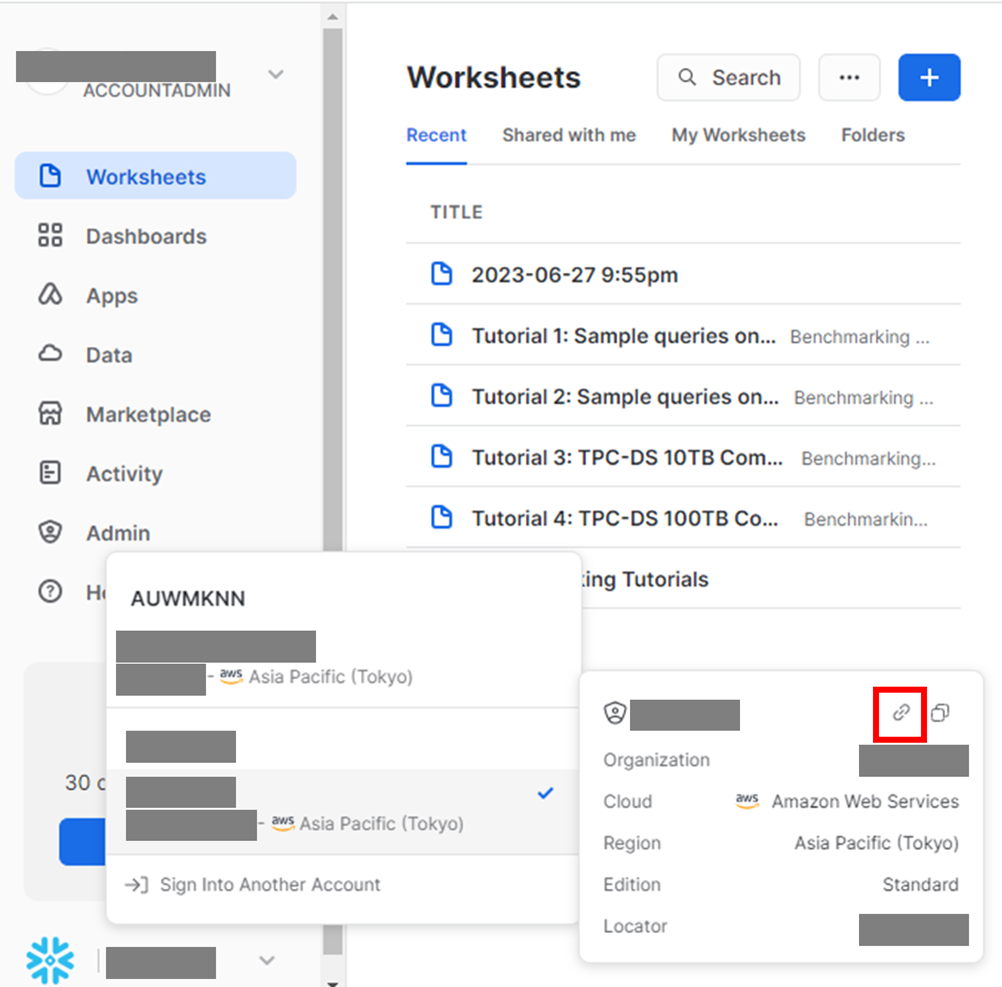
上記の中のSnowflake URLですが、Snowflakeメインページの左下から自身のアカウント識別子をクリックし、さらに画像の赤枠のクリップマークを押すとSnowflake URLがコピーされます。
ジョブの作成
いよいよジョブの作成です。
Glue StudioのSourceのノードの中にSnowflakeがいますね。これを利用してジョブを作ります。

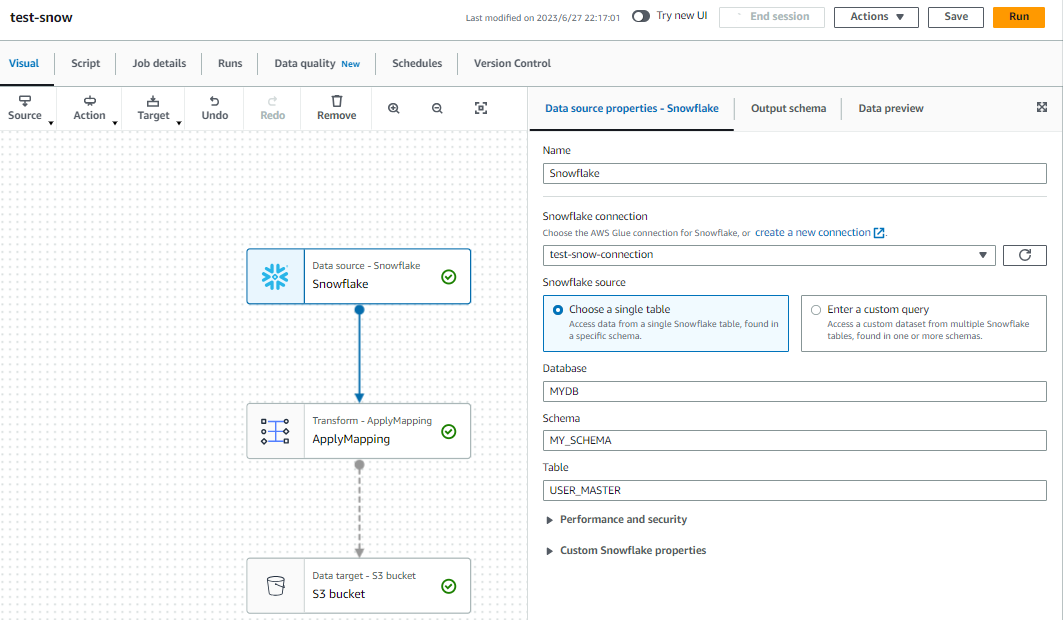
Snowflakeのノードですが、以下のように設定します。
Snowflake connectionは先ほど作成したConnectionを選択します。
Database, Schema, Tableは事前に作成したそれぞれの名前を入力します。
S3の方は、parquetでS3に出力する設定を入れています(画像は省略)。
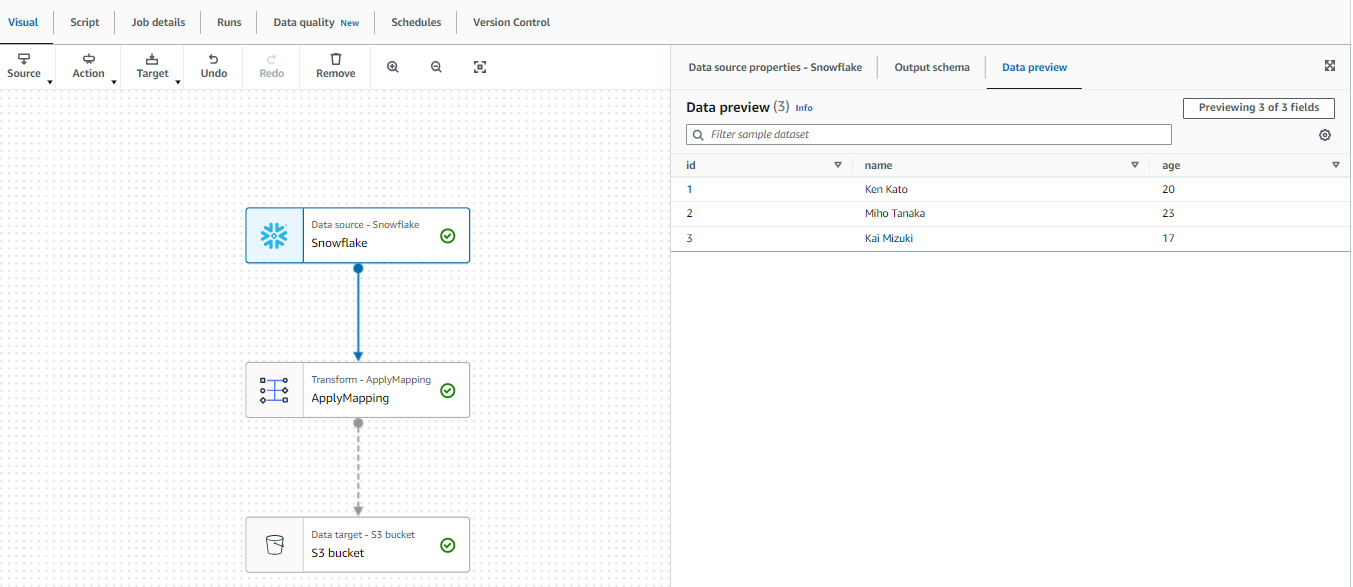
ジョブの作成中に、Data PreviewタブからSnowflakeのテーブルの値が見られました!接続に成功していますね。
作成中にこのようにSnowflakeのテーブルの値が見られるのは嬉しいですね。
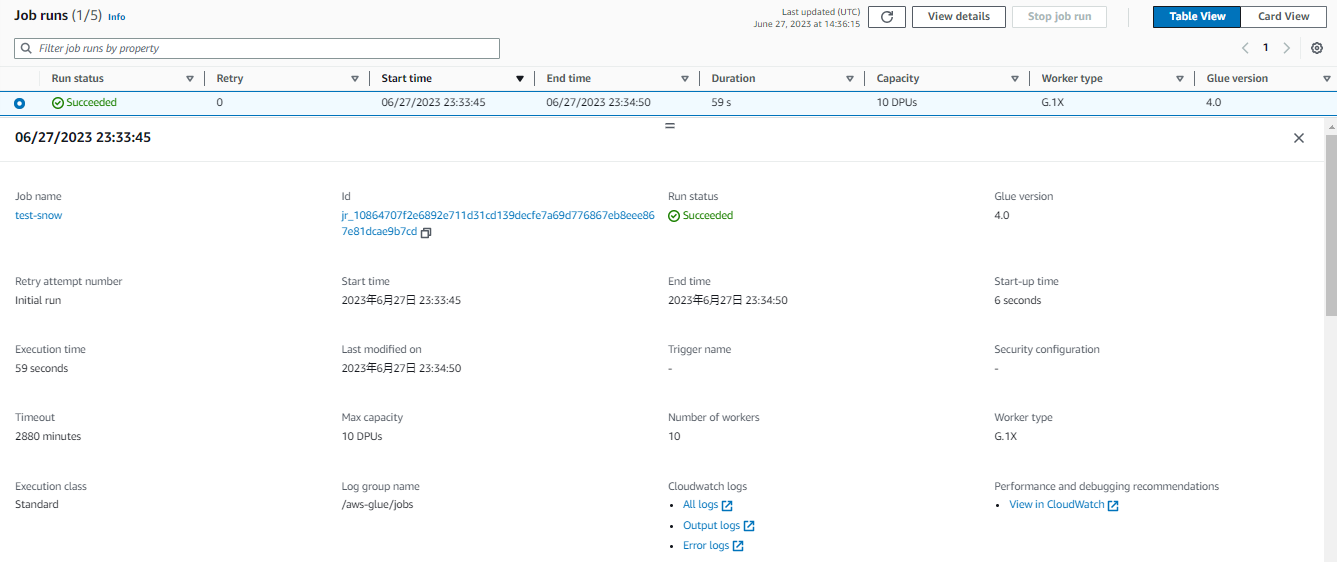
このジョブを実行してみたところ、実行は成功してS3にparquetファイルが出力されていました。
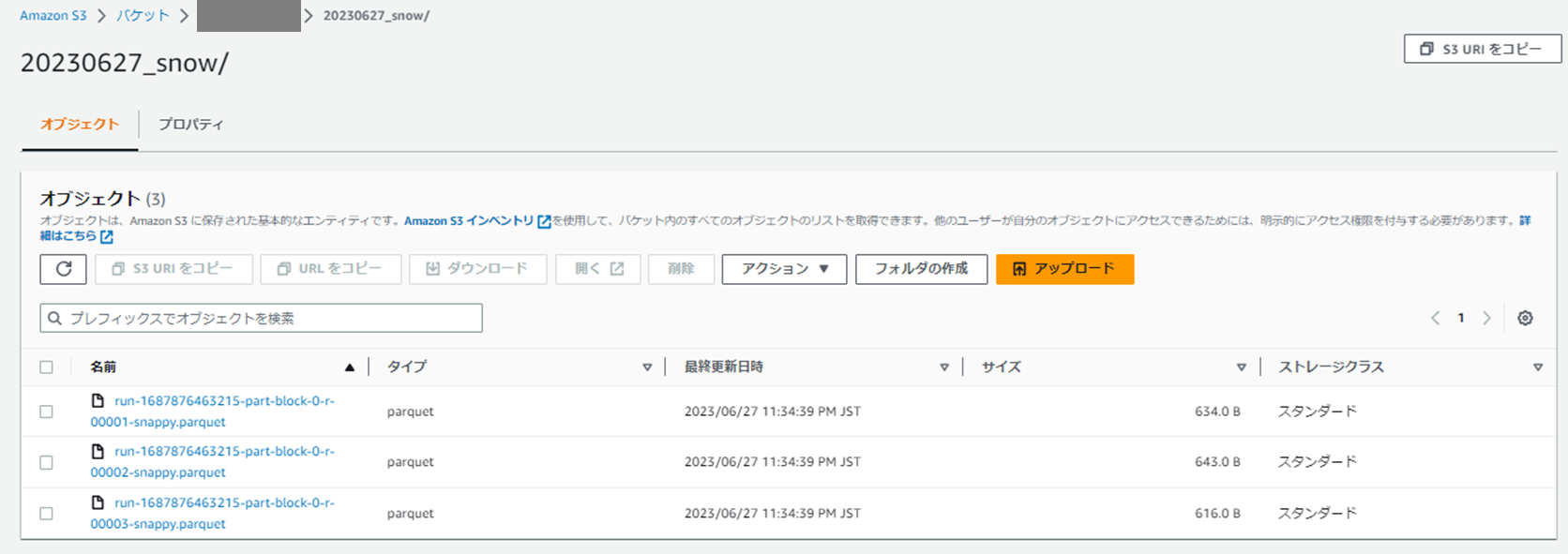
お試しで1つのparquetファイルを除いてみた結果、スキーマも無事元のテーブルのカラム名と同じになっていそうですね。
注意点
今回はSecret Managerを利用したので、Glueのジョブが利用するロールにシークレットへの読み取りアクセスの許可を付与しなくてはいけません。これをしないで、一度ジョブがエラーとなってしまいました。
今回は、公式ドキュメントを参考に以下のようなインラインポリシーを作成し付与したところ、、うまく動きました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetResourcePolicy",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"secretsmanager:ListSecretVersionIds"
],
"Resource": [
"arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecretname"
]
}
]
}
おわりに
Snowflakeからのデータロードは今までも出来てはいましたが、今回のupdateでより簡単にできるようになりました。色々なデータソースからまずはS3に持ってこれればAWS上での分析が捗るので、今後もよく使われるデータソースからのロードはどんどん簡単になっていってほしいですね。
次は、Snowflakeのテーブルに対して、ブックマーク機能を利用しての増分のみロードする方法も実施してみたいです。