はじめに
GlueからRedshiftのデータをロードしたいとき接続(connections)を作成すると思いますが、2023年10月29日時点ではユーザー名パスワードか、Secrets Managerの2つしか選ぶことが出来ません。
これを、IAM認証で接続(IAMロールを使用して、一時的なDBユーザーとパスワードを発行する)してみます。
ポイントは、Glueのジョブ内でGetClusterCredentialsを実行することです。
前提
- リージョン
- us-east-1
- Redshift
- ra3.xlplus ノード
- パブリック接続
- Glue
- Glue version 4.0
やってみる
DBユーザー作成
スーパーユーザーで以下を実行し、ユーザーを作成します。
(このユーザーを使って、後々Glueで処理を実行します)
CREATE USER glue_user1 PASSWORD 'Password01';
Redshiftはデフォルトだとユーザーを大文字で作成しても小文字となって作成されます。
以下のSQLでユーザーの一覧を確認できます。
select * from pg_user;
ちなみに、今回はユーザーにパスワードを付与しましたが、本来IAM認証であればパスワードは不要なはず(というかセキュリティリスク的につけないほうが良い)です。
PASSWORD DISABLEでパスワード無しのユーザーとして作成できます。
テーブル作成 & 権限付与
以下を実行してテーブルを作成し、レコードを追加します。
CREATE TABLE demo_a (
PersonID_a int,
City_a varchar (255)
);
INSERT INTO demo_a VALUES (1, 'Tokyo'), (2, 'Osaka');
その後、ユーザーに参照権限を付与します。
grant select on table demo_a to glue_user1;
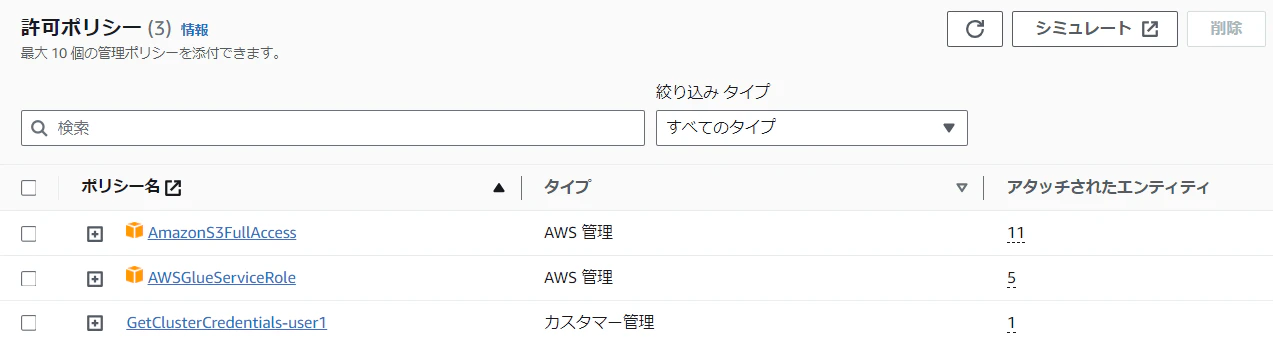
ポリシー、ロール作成
Glueに付与するロールと、それに付与するポリシーを作成します。
GetClusterCredentials-user1 という名前のポリシーを作成し、以下のように定義します。
({Account-ID}のところは適宜自身のAWSアカウントIDに変えてください。)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GetClusterCredsStatement",
"Effect": "Allow",
"Action": [
"redshift:GetClusterCredentials"
],
"Resource": "arn:aws:redshift:us-east-1:{Account-ID}:dbuser:redshift-cluster-demo/glue_user1"
}
]
}
次はrole-glue-for-redshift-access-aというロールを作成します。
そのロールに、以下3つのポリシーを付与します。
-
AmazonS3FullAccess(AWSマネージドポリシー)- Glueでcreate_dynamic_frame_from_optionsを実行する際に、S3にアクセスするため。
- オプションに"redshiftTmpDir"としてS3のパスを指定します。
- とはいえFullAccessは不要と思うので、本番ではより制限することをお勧めします。
-
AWSGlueServiceRole(AWSマネージドポリシー)- Glue connectionsを使う際に必要です。
- こちらも、本番ではより絞った権限を利用することをお勧めします。
-
GetClusterCredentials-user1(先ほど作ったポリシー)
S3とRedshiftのVPCエンドポイント作成
以下に記載のある通り、Redshiftがパブリックに配置されている場合はそのままだとGlueから接続できません。
AWS Glue は、接続のサブネットにプライベート IP アドレスを持つ Elastic Network Interface を作成します。つまり、AWS Glue はパブリックインターネットを使用してデータストアに接続できません。
ということで、S3(ゲートウェイ型)とRedshift(インターフェース型)のエンドポイントを作成します。
S3はゲートウェイ型なので、VPCのルートテーブルも書き換えることを忘れずに(エンドポイント作成するときにVPCにチェック入れれば勝手にルートテーブルも書き換えてくれます)。
ちなみに、S3、Redshiftどちらも作らないとエラーで接続できませんでした。
Glueコネクション作成
やっとGlueに入ります。
まずはコネクションを作成します。今回はDBユーザー名やパスワードについてはこのコネクション内の情報は使わないので、UsernameとPasswordはダミーの値でOKです。
ただ、サブネットの情報やセキュリティグループについてはコネクションを作成しないとジョブに紐づけられないので、今回は作成しています。
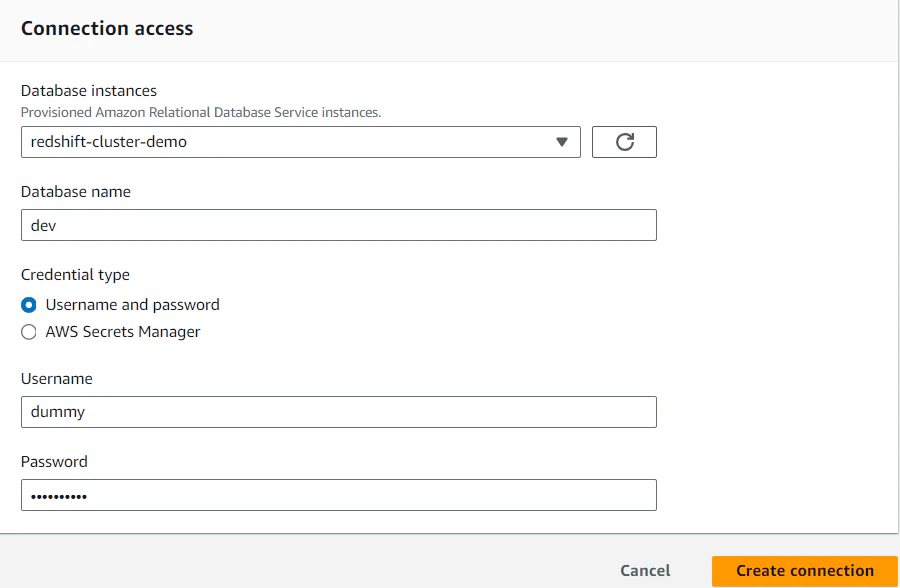
これ、ネットワーク情報は一切入力するところがないですが、おそらくRedshift側のネットワーク情報から勝手に取ってきてくれているものと思われます。GlueがJDBCを使って読み込む際は自己参照型のセキュリティグループを作成しなくてはなりませんが、今回はデフォルトのセキュリティグループを使っているので勝手に自己参照型になっています。自己参照型のところの詳細は、以下などを確認してください。
Glueジョブ作成
ようやくジョブを作成します。
以下のスクリプトを実行します。
Redshiftのクラスター名<redshift-cluster-name>、S3のバケット名<your-bucket-name>は変更してください。
get_cluster_credentialsを実行することで、既存のDBユーザーglue_user1のパスワードを一時的(900秒)に取得しています。
それをそのまま利用してconnection_optionsに設定して、Redshiftに接続しています。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
import boto3
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 処理
client = boto3.client('redshift')
response = client.get_cluster_credentials(
DbUser='glue_user1',
ClusterIdentifier='<redshift-cluster-name>',
DurationSeconds=900,
AutoCreate=False
)
connection_options = {}
connection_options["url"] = "jdbc:redshift://redshift-cluster-demo.cfoflfcudhiv.us-east-1.redshift.amazonaws.com:5439/dev"
connection_options["user"] = response['DbUser']
connection_options["password"] = response['DbPassword']
connection_options["dbtable"] = "demo_a"
connection_options["redshiftTmpDir"] = "s3://<your-bucket-name>/job-a/"
print(connection_options)
df = glueContext.create_dynamic_frame_from_options("redshift", connection_options)
df.show()
job.commit()
実行する前に、ジョブの設定から実行ロールとConnections(接続)を今回作成したものに設定することを忘れないようにしてください。
実行
ジョブを実行します。
上手くいけば、ジョブが成功して以下のようなログが出力されます(テーブル名やカラム名が記事内で作成したものと微妙に違っていますが、見逃してください)。
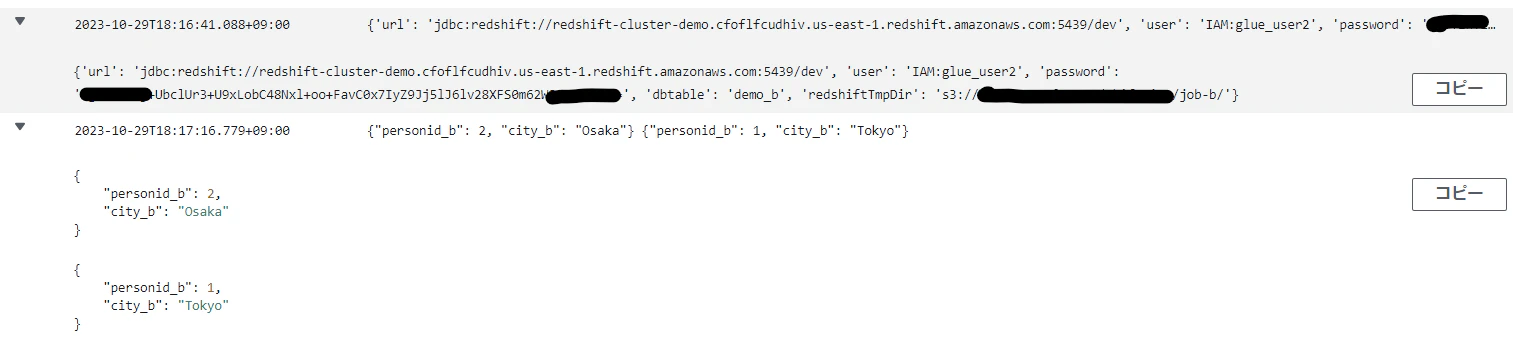
今回DBユーザーに許可しているdemo_aテーブル以外を指定した場合は以下のようなエラーが出ます。
An error occurred while calling o97.getDynamicFrame. Exception thrown in awaitResult:
また、今度はロールのポリシーで指定したDBユーザーglue_user1以外を指定すると以下のようなエラーが出ます(アカウントIDの箇所は999999999999に変更してます)。
ClientError: An error occurred (AccessDenied) when calling the GetClusterCredentials operation: User: arn:aws:sts::999999999999:assumed-role/role-glue-for-redshift-access-a/GlueJobRunnerSession is not authorized to perform: redshift:GetClusterCredentials on resource: arn:aws:redshift:us-east-1:999999999999:dbuser:redshift-cluster-demo/glue_user2 because no identity-based policy allows the redshift:GetClusterCredentials action
つまり、ロールで指定したDBユーザー、かつそのDBユーザーが参照許可されたテーブルのみがこのGlueジョブで参照できるということです。
注意事項
実際やると、最後のGlueジョブの実行が結構エラーとなります。
その場合は、まずGlue ConnectionのTest Connectionで接続チェックをすることをお勧めします。
その際は、ダミーではなくちゃんと存在するユーザーをconnectionに指定して、「まずはネットワーク的につながること」を確認しましょう。
ここがつながらない場合は、S3やRedshiftのVPCエンドポイントが作成されているか(またはNAT GWでもOK)、URLは正しいか、セキュリティグループは自己参照型になっているかなどを確認しましょう。
おわりに
RedshiftのIAM認証の方法は結構複雑ですね。
今回はRA3クラスターでDBユーザーの認証でしたが、サーバレスの場合やDBロールの場合などにどうなるかはやってみないとわかりません。ユースケースに応じて色々と検証が必要そうです(このあたりをChatGPTがすぐ出してくれると助かるんですが…)。
あとは、GlueのConnectionのユーザー名パスワードは、スクリプトの中で指定すれば上書きされる挙動になるというのも今回初めて知りました。やはり手元で動かしてみないと色々分からないですね。
参考