Cloudera Manager Advent Calender 2015 の15日目です。
目的
HadoopクラスタでHiveやImpalaを運用中には、様々なユーザがクエリを実行します。
その際にユーザによっては、、、
- Impalaのメモリを食い尽くすクエリが投げられる。
- 1ヶ月は終わりそうにない規模のデータを対象としたHiveクエリが投げられる。
- エラーが返ってくるんだけど!1日経っても終わらないんだけど!とオフィスに怒号が響く。
- これどうなってんのなんとかしてよ、と運用者が責められる。
……という事態が発生します。
リソースプールやアドミッションコントロールやクエリ実行者への教育という対処はありますが、
まずは対処以前に問題の発見が必要です。
ここではClouderaManagerを使って問題となったクエリを素早く見つけ出し、
そのクエリの中から原因を特定していく流れを紹介します。
- 画面はClouderaManager5.1.5のものです。
- Impalaのクエリ検索を対象に紹介します。
Impalaのクエリを検索する
- ホーム画面から「Impala」を選択します。
- 「クエリ」タブをクリックすると、多くのクエリが表示されます。
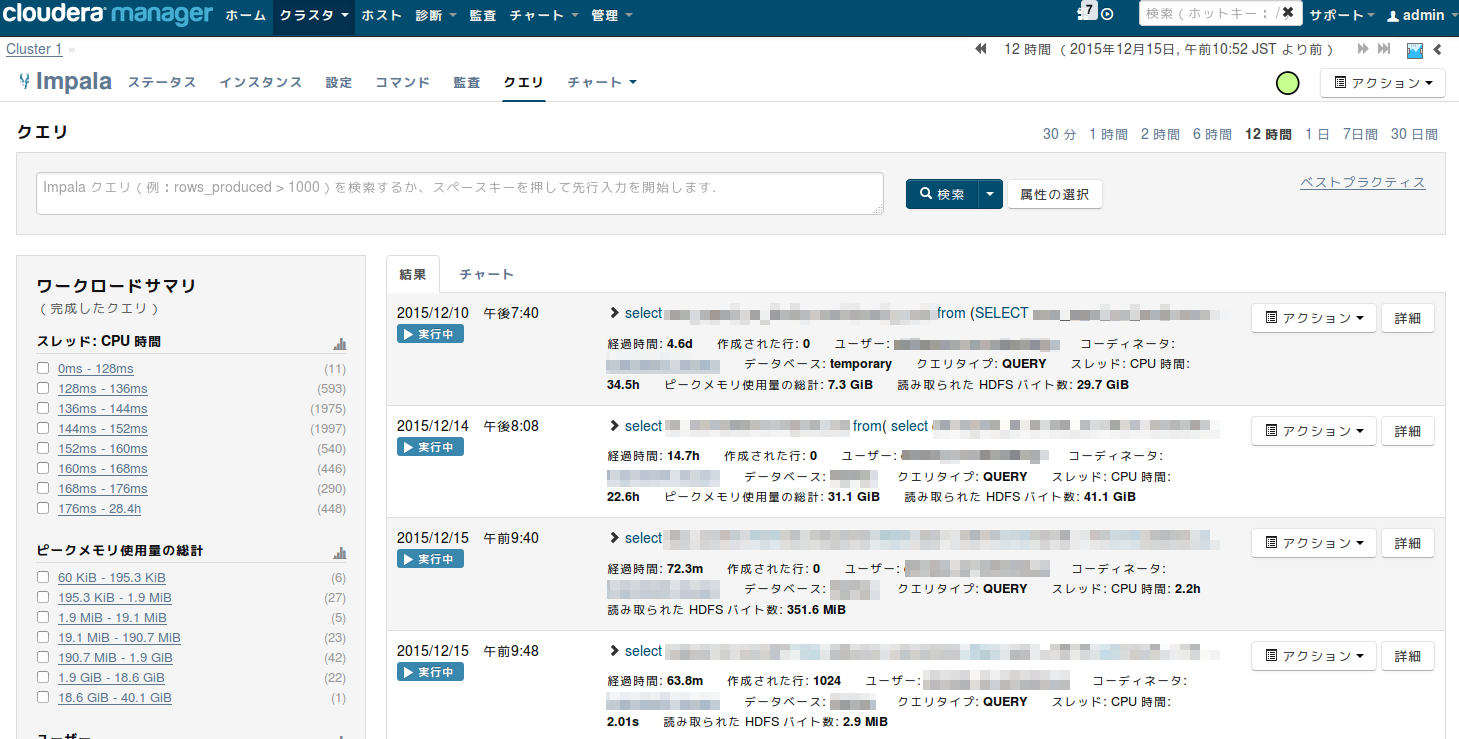
フィルター条件の入力
- 今回は何か問題のあったクエリを検索することが目的なので、フィルター条件の入力エリアで表示をフィルタリングしてみます。
- 記法はシンプルで、SQLのwhere条件を書くだけのようなものです。
-
補完機能が充実しているので、ほぼ何も知らなくても容易に書けます。
- 例えばquery_duration(クエリ実行時間)で絞り込む場合で補完の様子を見てみます。
- 上述の画面の「クエリ」のすぐ下にあるフィールドに入力していきます。
query_durationを使いたい場合、duraと入力すると補完候補が出現します。
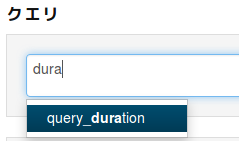
query_durationを選択すると、 次の比較演算子の候補まで出現してくれます。
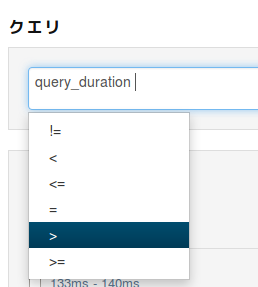
比較演算子を選択すると、 指定できる時間の記法もサンプルが候補に上がります。だいたいこれで解りますね。
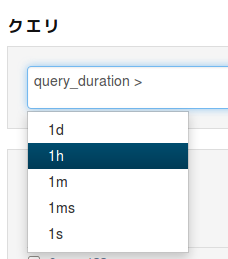
そして、一つの条件を入れ終わると 論理演算子の候補まで上がってきます。運用者に対する学習コストほぼ0です。
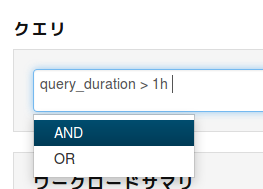
- 上述の例の様に、最初に使うフィルター属性(この場合はquery_duration)さえわかれば、後は細かい記述方法を全て補完で何とかなってしまいます。便利。
- 以下、フィルター属性名を直接使う方法と使わない方法の両方で、幾つか検索方法を紹介します。
1. 推奨の検索条件を使う
検索ボタンの右側の逆三角形をクリックすると、推奨の検索条件が用意されています。便利。
例えば「失敗したか、キャンセルされました」を選択してみます。
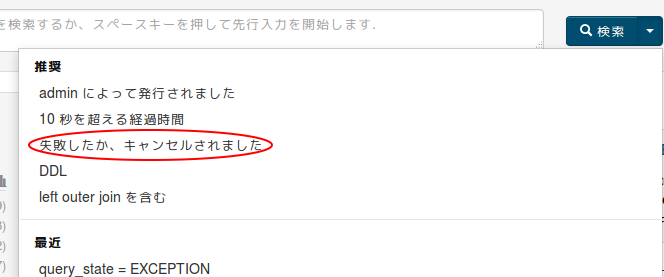
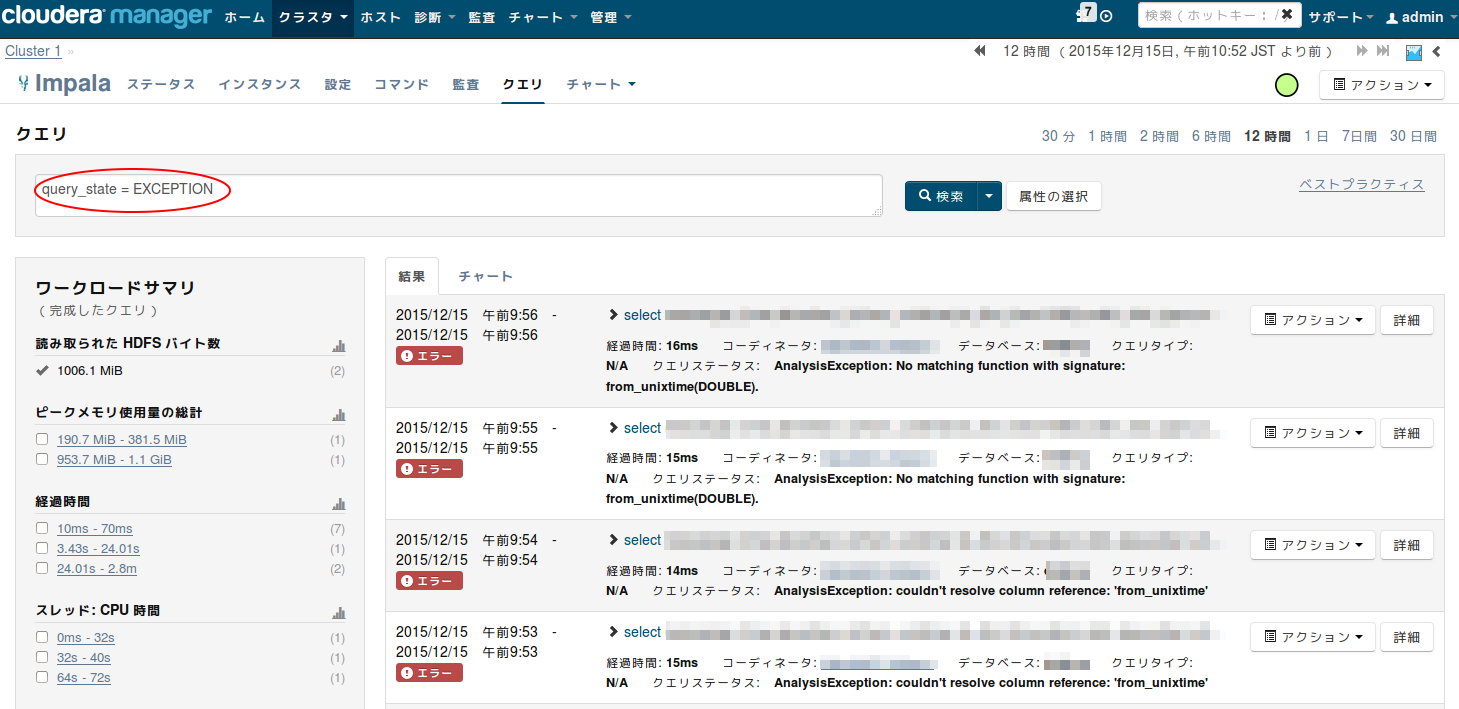
エラーとなったクエリを探索する条件が自動的に入力され、結果が表示されます。
2. ワークロードサマリを使う
クエリ表示画面の左側には、幾つかのカテゴリ毎にサマリが表示されていて、
クリックすることでそのカテゴリに合致するクエリに絞り込むことが可能です。
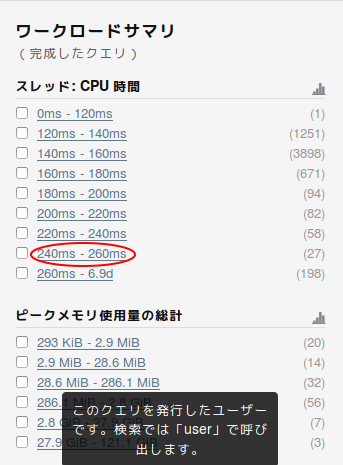
この例では240ms-260msを選択することで、同様に自動的にフィルター属性名を使った条件が入ります。

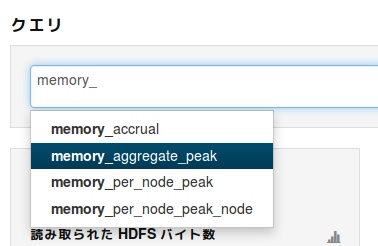
3. 適当に当たりをつけて補完機能を使う
大体クエリ実行時間ならdurationだろ 、と考えてdurationと打てば補完されますし、
memory関連が怪しいとわかっているならmemoryと打ってみて補完候補を見る 、というやや適当な方法でもなんとかなる……場合もあります。
(測定値の名称が直感的に大きく異なるものはそうはありません)
4. 公式のドキュメントを見る
指定できるフィルター属性名が全てリストされています。
この方法を最後にするのはよろしくないですね。最初に見ましょう。
(これはClouderaManager latestバージョンのドキュメントです。自分の使用しているバージョンを指定するには、urlのlatest部分を「5-1-5」の様にしましょう。
バージョン毎にドキュメントを残していただいているため過去バージョンを参照できます。何気にとてもありがたいです。)
クエリの検索から原因特定へ
- 問題となるクエリを検索し、原因箇所を特定するまでの流れを紹介します。
- 問題設定
- ユーザー「Impalaのクエリがエラーで返ってこないんだけどー、2015/MM/DD HHくらいに投げたクエリがエラーになったー。はやく直してー。」
- 運用者「クエリ長い……どこが原因かぱっと見じゃ判らん」
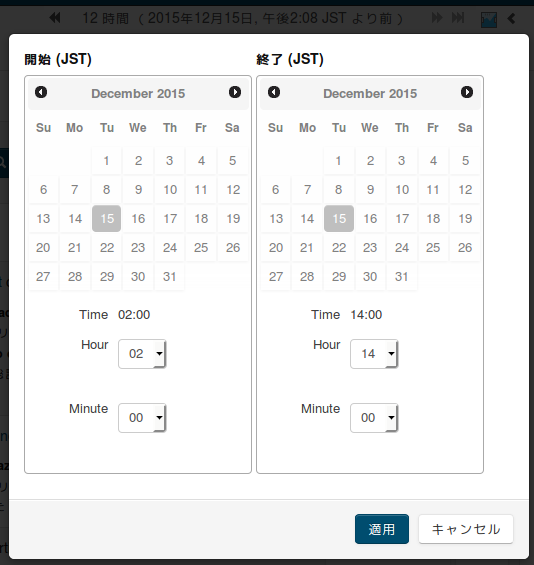
1. 時間を絞る
直近から近いなら、画面右上アクションの下にある時間帯(直近からいつまでを表示するか)をクリックするだけです。簡単ですね。

しかし7日や30日を使うと母数によっては重くなります。そんな時はその少し上のにあるカレンダーからstart/endを詳細に絞りこみましょう。
2. フィルター属性って絞り込む
今回はステータスとクエリ本文で絞ってみます。
クエリ本文のフィルター属性名は「statement」です。
(時間帯とステータスとユーザで絞れる時もありますが今回はクエリ本文を教えてもらった想定で)
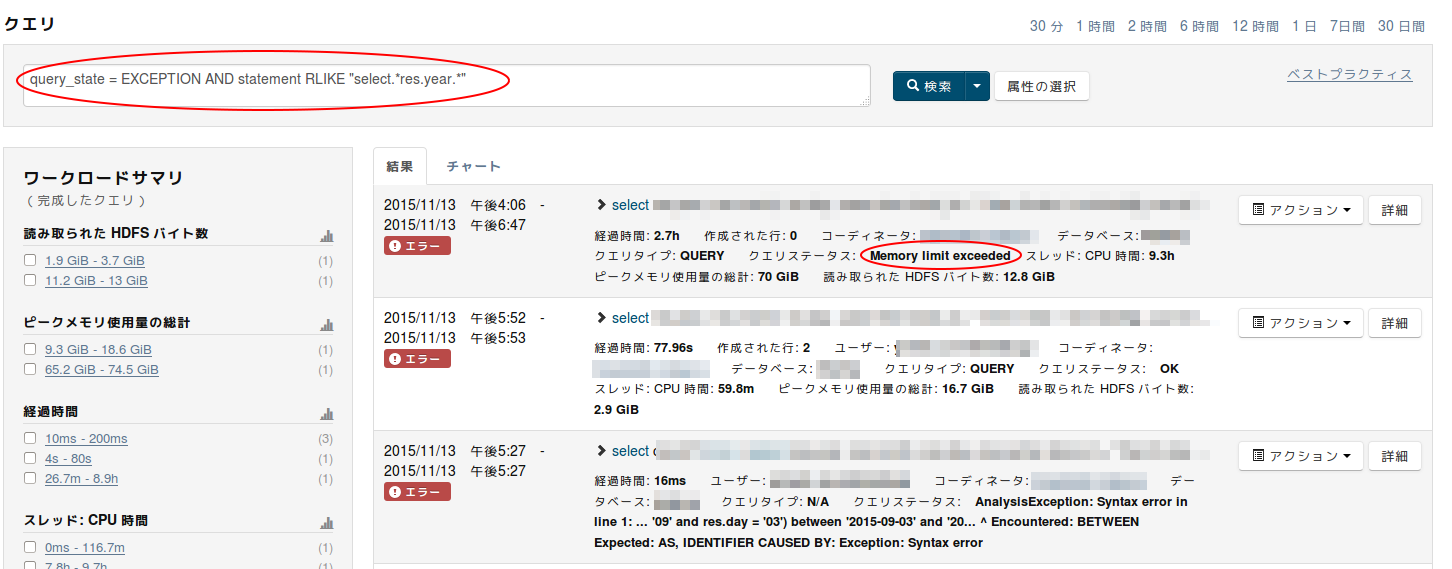
すると、何やら「Memory limit exceeded」という嫌なメッセージがあるクエリが出てきました。
3. 詳細を追う
先ほどのクエリの右にある「詳細」ボタンを押します。
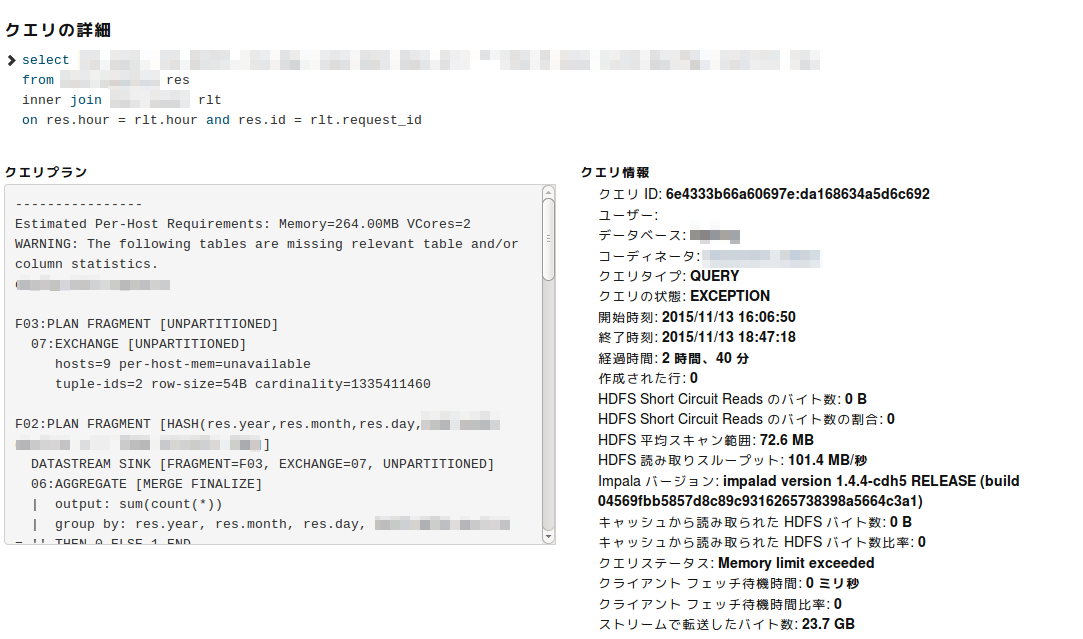
クエリ本文の全体、クエリプラン(EXPLAINで取れる情報)、またクエリ情報(PROFILEで取れる情報)が参照できます。
4. フラグメントを見る
Memory limit exceededなのでどこでメモリを消費したのか見るため、詳細画面を下ってフラグメントを見てみます。
(こちらもPROFILEで見ることができる情報です)
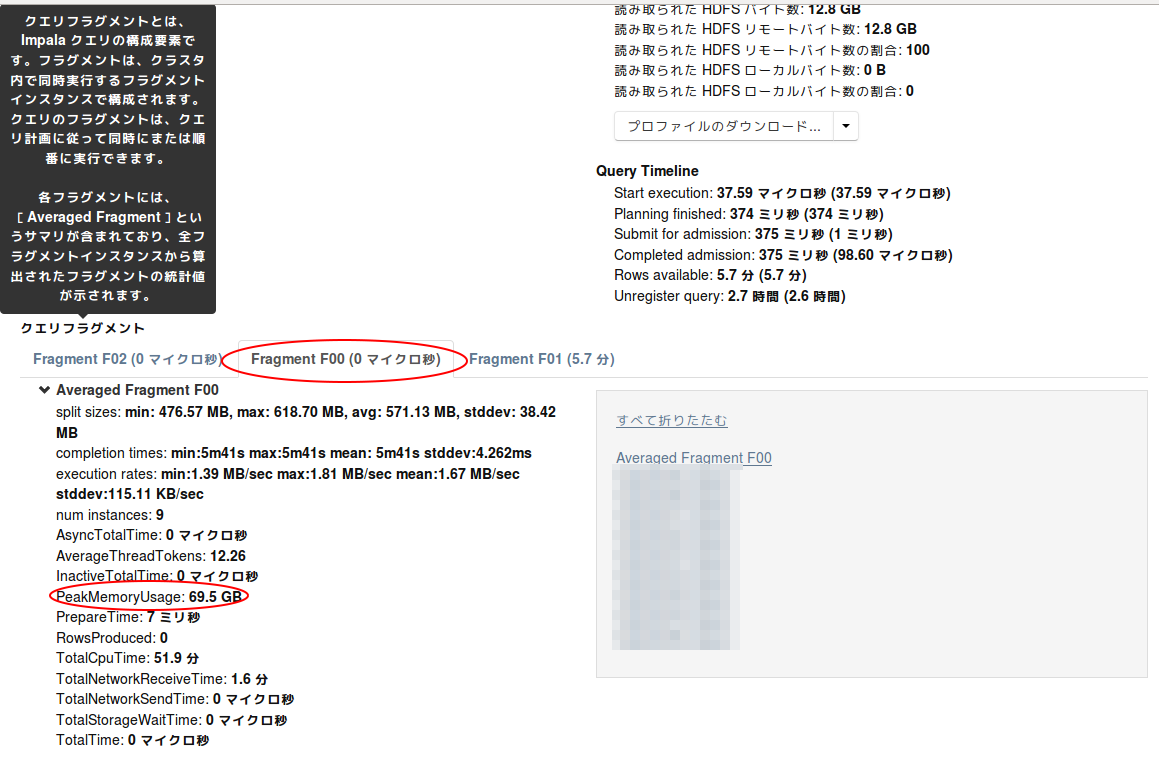
FragmentはF00、F01、F02の3つのタブがあります。
今回はF00のPeakMemoryUsageが他よりも高いので、恐らくこれが原因です。
さらにこのFragmentを下ると、
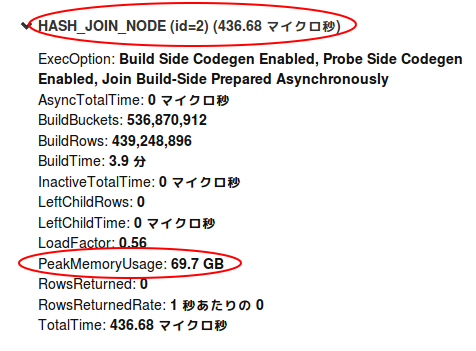
ほとんどのMemoryUsageはHASH_JOINで消費されているということがわかりました。
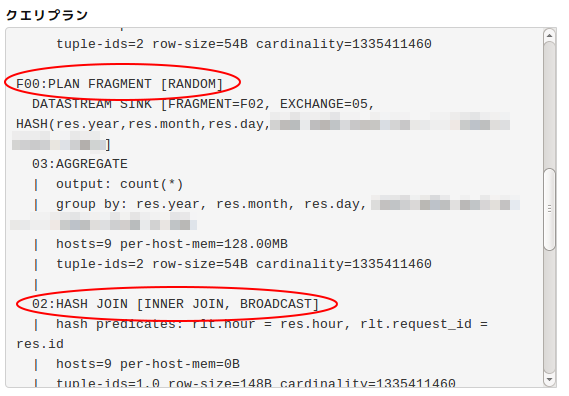
クエリプランに戻る
画面を上に戻ってクエリプランを、先ほどの「Fragment00」の中のHASH JOINで見てみると、
このJOIN条件が原因に近いということに辿りつけました。
その他
- YARNアプリケーションも大体同じようにして検索できます。きっとSparkもできるはずです(試してません…)
- この手の問題への対処としてResource Poolの設定をしよう!となった場合も、ClouderaManagerでは非常に解りやすいUIで設定が可能です。便利。
- Impalaのクエリ実行履歴(PROFILE情報、クエリプラン含む)のデータ保持期間については、ClouderaManagerの設定で変更できます。
- 今回の例はImpalaのバージョンが1.4.4なのでHASH JOIN時のメモリ超過でエラーになりましたが、、最近のバージョンではディスクにspillする機能があるのでこの原因では落ちないと思われます。。。
- また、統計情報を取っていなかったので適切なJOIN方法を選択できなかったということも。。。
まとめ
ClouderaManagerを使うとImpalaクエリの検索から原因特定までがとても簡単になります。
デフォルトのImpala WebUIでもクエリの一覧やProfileを見たりすることが可能ですが、
検索できない、Impaladノード毎にWebUIが分割しているなど今回のオペレーションに対しては不便な点があります。
そして、ここまでの機能は何もしなくても ClouderaManagerのデフォルトで情報が収集されており、
後から「スロークエリー増えたなーこんな運用の課題があるんだけどログ取ってデータ収集して検索できるようにしないとなー」という場合の対処が要りません。
ぜひ運用の助けにしていただければ幸いです。