本記事ではDifyのナレッジをAPI経由で更新する方法を解説します。
RAG構築は以下の記事を参考にしてください。
https://qiita.com/ogi_kimura/items/d13631b3a77e18023ef9
ナレッジ更新の自動化
通常ナレッジ更新はDifyの管理画面を通して手動で行う必要があります。更新対象が多い場合は手間になりますし、忘れてしまう可能性があります。そこで、DifyのAPIを利用してナレッジ更新を行う必要がでてきます。以下に具体的なコードも含めて解説を行います。
APIを利用したナレッジ更新
準備
以下の画面より「APIキー」と「APIサーバー」を取得します。
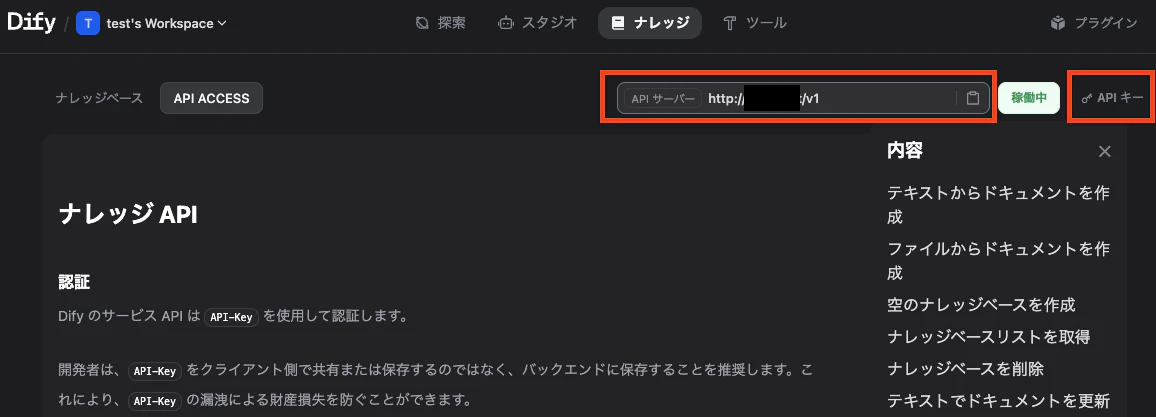
続いて更新したいナレッジベースを開いてURLから「データセットID」を取得します。

コード
ナレッジを更新するサンプルコードは次の通りです。取得したAPIキー、APIサーバー、データセットIDを設定してください。
python entry.py
import sys
import json
import requests
API_KEY = '<APIキーを設定>' # 例: dataset-abcd1234efgh5678ijkl9012
ENDPOINT = '<APIサーバーを設定>' # 例: http://localhost:8080/v1
DATASET_ID = '<データセットIDを設定>' # 例:12345abc-a123-a123-1234-a123456789ab
def main():
target_file = sys.argv[1]
url = f"{ENDPOINT}/datasets/{DATASET_ID}/document/create-by-file"
headers = {
'Authorization': f'Bearer {API_KEY}',
}
data = {
'indexing_technique': 'high_quality',
'process_rule': {
'mode': "automatic"
}
}
with open(target_file, 'rb') as f:
files = {'file': (target_file.split('/')[-1], f)}
r = requests.post(url, headers=headers, data=data, files=files)
if r.ok:
print("success:", r.status_code, r.json())
else:
print("failed:", r.status_code, r.text)
if __name__ == "__main__":
main()
上記のコードをcronなどで定期実行すれば更新ができます。
bash entry.sh
#!/bin/sh
# 更新したいドキュメントを準備する
wget https://〜/document.md
# difyのナレッジベースに更新する
python3 entry.py document.md
このままでは、APIキーを直書きしてしまうため本番環境ではos.getenvなどで環境変数から読み込むなどのアプローチを検討してみてください。
.envからの読み込みに対応したコードは以下にあります。
最後に
本来であれば、定期実行もdify内で実行できたらいいのですがdifyには定期実行できる仕組みがありません。そのため、cronなどで実行する必要があります。n8nが使える環境の場合はそちらを利用するのも良いかと思います。