1.そもそも分散システムとは?
働いている会社で、ビックデータを扱う機会が増えている人もいるのではないでしょうか?
数百GB、TBレベルの大量のデータを1つのコンピューターで処理することはかなりの時間を要してしまいます。
そこで、複数のコンピューティングを使って分散してデータを処理するシステムのことを分散システムと総称していいます。
上記資料参考サイト:
分散システムの中にApache Sparkというものを聞いたこともある方はいるかと思います。
HadoopとSparkは対の関係ではなく、
Hadoopの一部にSparkがあるのです。
なので、Sparkの構成を知りたい方はまずHadoopとはなんなのかを学習するところから始まります。
2.Hadoopとさまざまな分散システム
分散システムを学習したい方はまず初めにHadoopというシステムを学習する、ないしは聞いたことがある人が多いかと思います
Hadoopは
2006年には単体のプロジェクトとして独立し、Apache Hadoopとしてリリースされました
Hadoopは1つのソフトウェアではなく、複数のソフトウェアを組み合わせたものになります。
なぜ今1系の勉強をするのか?
2023年12月現在、Hadoopは3系まで存在しています。
まずは1系のシステム構成から学習した方が基礎が分かるので
吸収が速いかと思い、まずは1系から説明いたします。
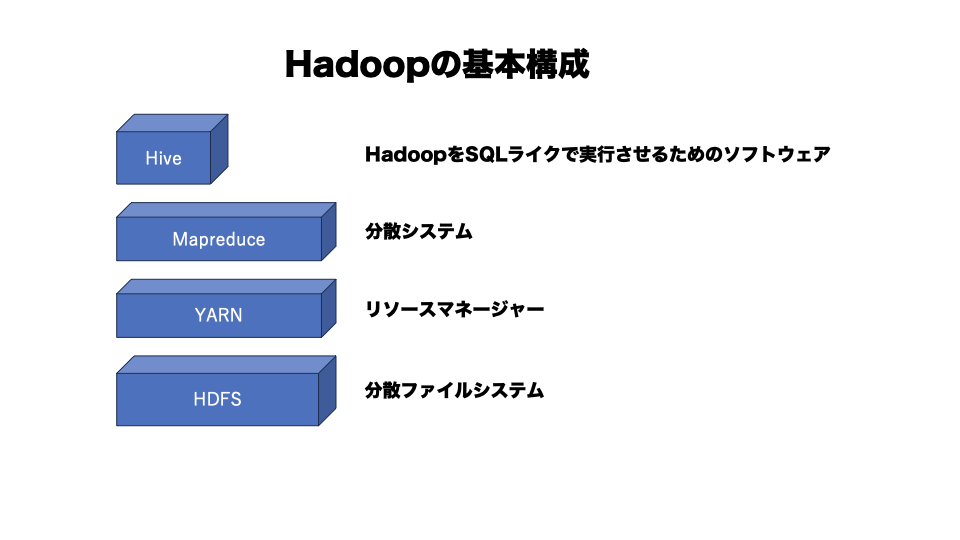
以下の画像はとりあえず今のところは
『こんな構成してるんだー』くらいの認識でOkです。
個別に見ていきましょう。
HDFS
Hadoop Distributed File System
分散ファイルシステムといいます。
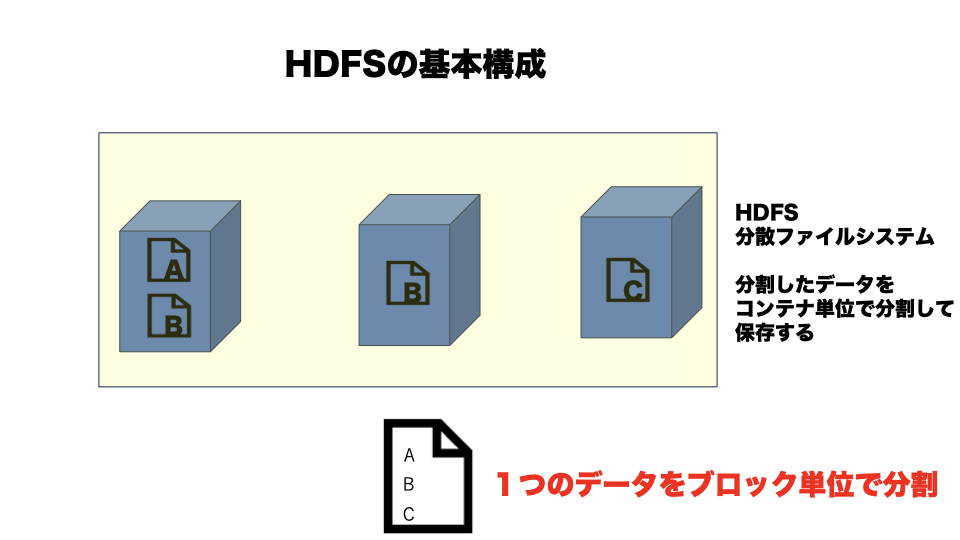
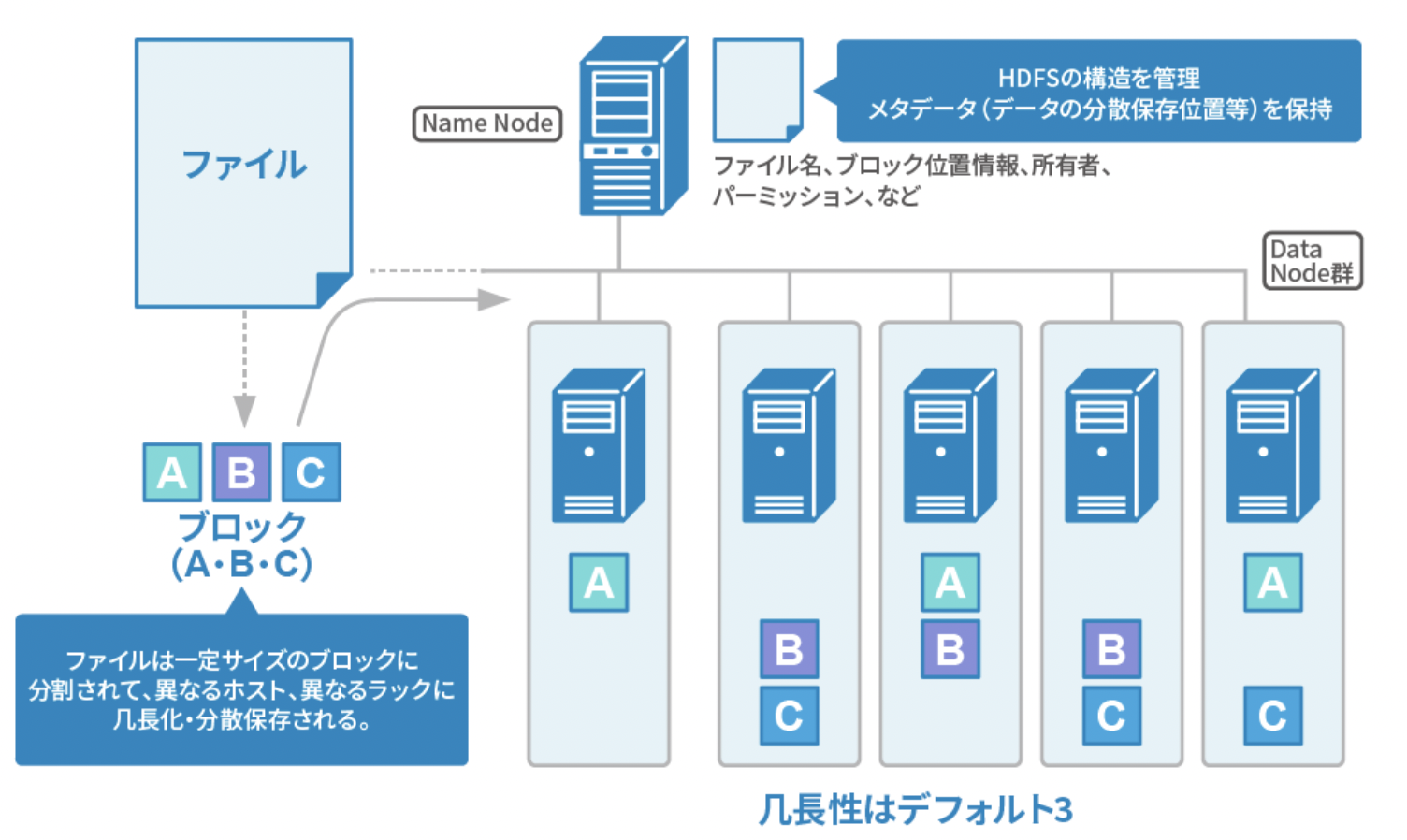
1つのデータをブロック単位でまずは分割します。
時系列のデータあれば
13:00~15:00の50万行のデータを分割
15:00~17:00の50万行のデータを分割
みたいに一定サイズで分割していきます。
コンテナという複数の入れ物みたいなものに分割したデータを格納します。
HDFSの細かな構成
コンテナ単位で分割されるのはわかりました。
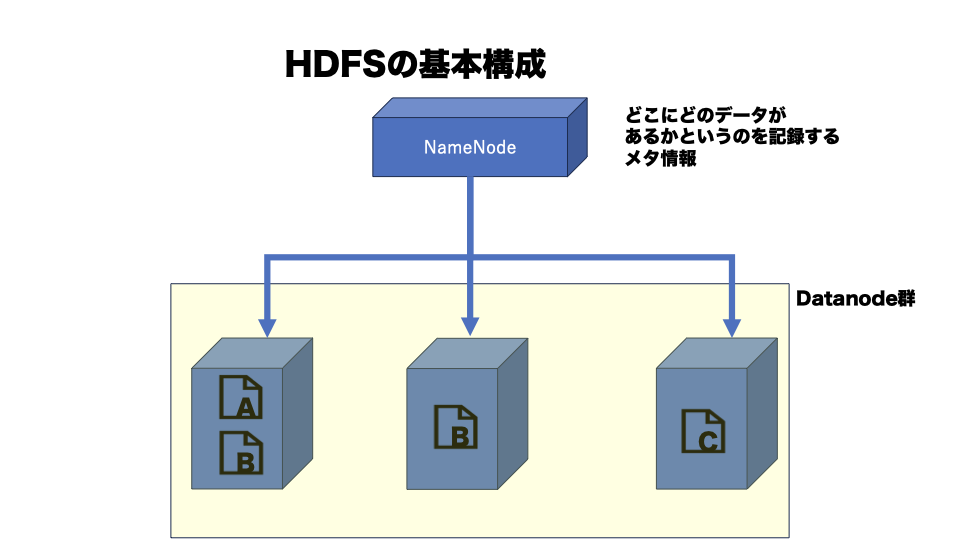
イメージですが、どのデータがどのコンテナに格納されているか管理しないといけません。
それにNameNodeというものがあり、まだ、コンテナの集団をDataNodeといいます。
DataNodeにはデータの実態が存在します
ここで、DataNodeが故障したらどうなるでしょうか?
これがデータを分割させた理由になります。
Bのみを保存していた部分が壊れていても、他にBが格納されているので、問題なく稼働することができます。
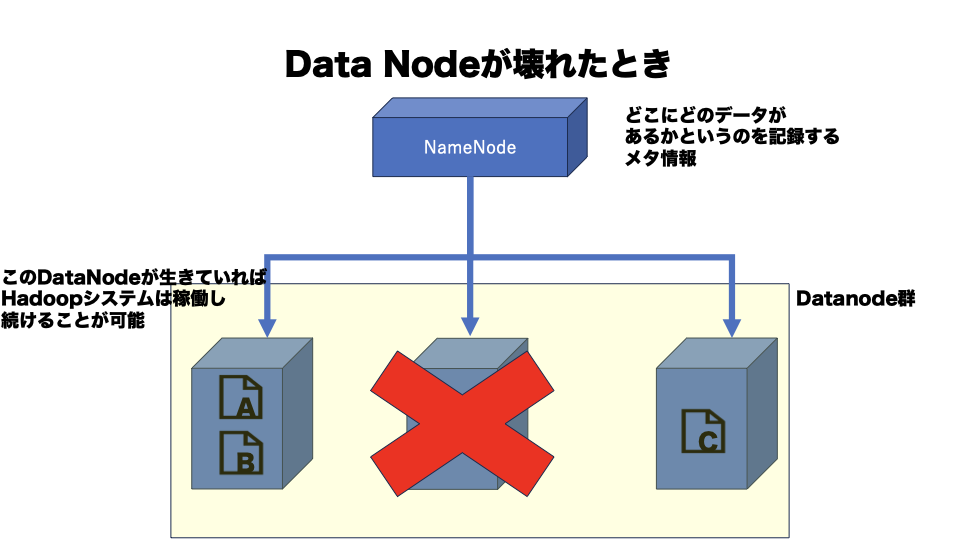
Name Nodeが壊れた場合は?
図で分かる通り、Name Nodeが壊れた場合は、単一障害点としてHadoopシステムが動かなくなってしまいます。
NameNodeのサービスを維持する仕組みとして、Apache ZooKeeperの分散ロック機構を利用した、Active-Standby構成のNameNode-HAが開発されました。 このNameNode-HAにより、Active側のNameNodeが故障した場合に、ダウンタイムなしでStandby側のNameNodeにサービスを引き継げることが可能になりました。
Mapreduceのシステム構成
Mapreduceは実際にデータを処理するソフトウェアになります。
Hadoop MapReduceは、マスターノードであるJobTrackerとスレーブノードであるTaskTrackerで構成されています。 JobTrackerは、MapReduceジョブの管理やTaskTrackerへのタスクの割り当て、TaskTrackerのリソース管理を役割としています。 TaskTrackerは、タスクの実行を役割としています。
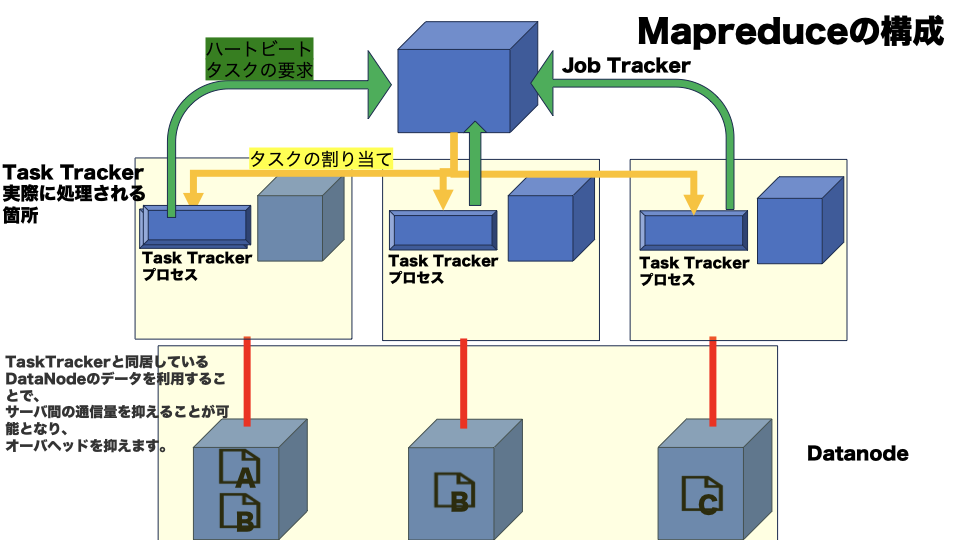
上のTask Trackerの1つをクラスタと呼びます。
もし仮にどこかのTaskTrackerが故障した場合は、クラスタを引き離し、別のTask Trackerで再試行されるような設計になっています。
Hadoop2系の登場
Hadoop2系では、分散処理フレームワークHadoop MapReduceの仕組みが変更となり、分散リソース制御機構 Hadoop YARNとMapReduce ApplicationMasterの2つに分離されました。 YARNの登場により、MapReduceに適していない処理については、各自が仕組み(ApplicationMasterとアプリケーション制御)を実装することでMapReduceと同様にYARNの仕組みによって分散処理が可能となりました。 YARN上でのMapReduce以外のアプリケーションでは、Apache Tez、Apache Sparkなど活発に開発されています。
ここからようやくSparkが出てくるわけですね。
次の記事はHadoop2系の説明とSparkのシステムをしたいと思います。