バイク川崎バイクというお笑い芸人をご存じでしょうか。
簡単に紹介しますと、頭文字が「B」「K」「B」となるような文章を作って「BKB!ヒィーア!」と叫ぶのが特徴的なお笑い芸人です。
(私の文章力ではバイク川崎バイクさんの魅力を伝えられないので気になる人は動画を探してみてください)
なぜバイク川崎バイクさんの話をしたのかと言いますと、記事「ゴー☆ジャス(宇宙海賊)をつくる」に感銘を受け、私もバイク川崎バイク生成プログラムを作ってみましたので今回はそちらを紹介したいと思います。
作ったもの
今回作ったものは、1単語与えるとそれに続く頭文字が「K」から始まる単語と、その次に続く「B」から始まる単語を生成するものです。
イメージとしてはこんな感じです。
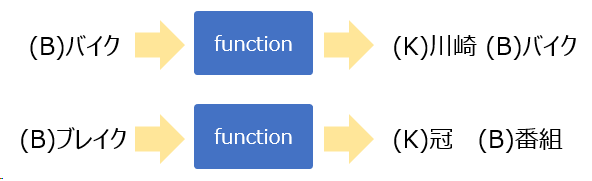
ポイントとしては、自然言語処理モデルGPT-2を使うことで、ランダムな頭文字「K」「B」の単語ではなく、文脈を意識したような単語が出力されることを期待しています。
コード
学習済みモデル読み込み
import numpy as np
from transformers import T5Tokenizer, AutoModelForCausalLM, top_k_top_p_filtering
from janome.tokenizer import Tokenizer
gpt2_tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
gpt2_model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-medium")
学習済みモデルを読み込みます。
今回はrinna社が公開している日本語に特化したGPT-2の学習済みモデルを使います。
次の単語予測
# GPT-2を使った次の単語の予測
def get_next_token_logits(word):
input_ids = gpt2_tokenizer.encode((word), return_tensors="pt")
next_token_logits = gpt2_model(input_ids)[0][:, -1, :]
filtered_next_token_logits = top_k_top_p_filtering(next_token_logits, top_k=100, top_p=1.0)
return filtered_next_token_logits
GPT-2を使って次にくる単語を予測する関数です。
この関数の出力結果はすべての単語の予測確率となるので、ここから対象となる単語を抽出していく必要があります。
対象単語抽出
# 対象となる単語の候補を抽出
def filter_word(next_token_logits, initial_char_type):
if initial_char_type == 'k':
initial_char = ('カ', 'キ', 'ク', 'ケ', 'コ')
elif initial_char_type == 'b':
initial_char = ('バ', 'ビ', 'ブ', 'ベ', 'ボ')
token_indexes = []
for idx in np.where(next_token_logits > 0)[1]:
word = gpt2_tokenizer.decode([idx])
t = Tokenizer()
token = t.tokenize(word).__next__()
if not token.part_of_speech.startswith(('名詞', '動詞', '形容詞')):
continue
if not token.reading.startswith(initial_char):
continue
token_indexes.append(idx)
return token_indexes
GPT-2の予測結果から対象となるものを抽出する関数です。
今回対象とする単語は品詞が"名詞"、"動詞"、"形容詞"のいずれか、且つイニシャルが「K」もしくは「B」になる単語です。
イニシャルの判定は日本語読みで頭文字が「'カ', 'キ', 'ク', 'ケ', 'コ'」(もしくは「'バ', 'ビ', 'ブ', 'ベ', 'ボ'」)のいずれかに該当するものというルールで判定しています。
日本語読みの頭文字で判定しているため、単語が英語であった場合実際の単語のイニシャルがK始まりでない場合も出てくると思うのでこの辺りは改善の余地があるかもしれません。(例えばQuickや、Cardなどです)
次の単語選択
def softmax(x):
f_x = np.exp(x) / np.sum(np.exp(x))
return f_x
# 次の単語を選択
def select_word(token_indexes):
prob = filtered_next_token_logits_np[:,token_indexes]
next_token = np.random.multinomial(1, softmax(prob)[0], size=1)
next_word = gpt2_tokenizer.decode([token_indexes[np.argmax(next_token)]])
return next_word
候補の単語から次の単語を選択します。
ランダムに単語を選択するのではなくGPT-2の予測値を使って、予測確率が高いものほど選ばれる確率が高くなるようにします。
BKB作成
ここまでで定義した関数を使ってBKBを作ります。
first_word = 'バイク' #1単語目
まずは、1単語目を指定します。今回は バイク を1単語目に指定します。
(1単語目の入力チェックは入れていないのでB始まりの単語でなくても指定できてしまいます)
# 2単語目出力
next_token_logits = get_next_token_logits(first_word)
filtered_next_token_logits_np = next_token_logits.to('cpu').detach().numpy().copy()
token_indexes = filter_word(filtered_next_token_logits_np, 'k')
second_word = select_word(token_indexes)
# 3単語目出力
next_token_logits = get_next_token_logits(first_word + second_word) # 1単語目と出力した2単語目を連結
filtered_next_token_logits_np = next_token_logits.to('cpu').detach().numpy().copy()
token_indexes = filter_word(filtered_next_token_logits_np, 'b')
third_word = select_word(token_indexes)
2単語目と3単語目を出力します。
3単語目の出力時の入力は最初に指定した1単語目と2単語目を連結させて入力させます。
それでは結果を見てみましょう。
print(f'{first_word} {second_word} {third_word}')
> バイク 車 ビッグ
**「バイク」 「車」 「ビッグ」!**BKB!ヒィーア!
残念ながら「バイク川崎バイク」にはなりませんでしが、無事BKBにはなりました。
もう一個くらい出してみましょう。次は最初の単語に「バランスボール」を指定してみます。
first_word = 'バランスボール'
next_token_logits = get_next_token_logits(first_word)
filtered_next_token_logits_np = next_token_logits.to('cpu').detach().numpy().copy()
token_indexes = filter_word(filtered_next_token_logits_np, 'k')
second_word = select_word(token_indexes)
next_token_logits = get_next_token_logits(first_word + second_word)
filtered_next_token_logits_np = next_token_logits.to('cpu').detach().numpy().copy()
token_indexes = filter_word(filtered_next_token_logits_np, 'b')
third_word = select_word(token_indexes)
print(f'{first_word} {second_word} {third_word}')
> バランスボール 体 ボール
**「バランスボール」 「体」 「ボール」!**BKB!ヒィーア!
BKBの作成に成功しました。
最後に
BKBの作成には成功しましたが、正直3単語続けて読んでもよく意味が分からないBKBが出力されているように思えます。
GPT-2を使うことでもう少し意味のあるBKBが作成されることを期待しましたが、入力が1単語であり文脈が存在しなかったことが意味のないBKBとなった原因ではないかと思います。
自然言語処理は初心者ですので、おかしな点などありましたら指摘していただけると幸いです。