無音区間が邪魔だから削除したい
DNNに音声データを与えるにあたって無音区間は大敵なようです。特に今私が取り組んでいるリアルタイム音声変換では邪魔です。なのでそれを取り除きます。
修正記録
5/22: コードを、median/2以下を削除するものからmaxが定数以下のところを削除する方法に変更。こちらのほうがブレが少なかった。
方法
無音区間の削除自体はpydubだとpydub.silence.split_on_silence、librosaだとlibrosa.effects.splitを使えばできます。
しかしこれらの手法は
- db単位で無音区間を定義するため、子音まで削除されてしまう
- まとめてFTなどするときに誤差部分も考慮されて変換されてしまう
といった問題点があります。どちらもできる限り避けたいです。
なので私は先に離散コサイン変換 -> そのまま無音区間削除といった形をとりました。
コード
sound = np.array(sound.get_array_of_samples()).astype('f')
sound = sound[:2 ** 18].reshape((-1, 2 ** 9))
convert = dct(sound, norm='ortho')
abs_c = np.abs(convert)[:, :comp//2]
where = np.where(np.max(abs_c, axis=1) < 512)[0]
convert = np.delete(convert, where, axis=0)
離散コサイン変換したものを絶対値にして足し合わせます。無音は基本的に低周波の方にエネルギーを持たないので省けます。
256までを使っているのは、子音は低周波にエネルギーを持たないからです。32など、もっと低い数値でしてしまうと普通の手法と同様に子音が消えてしまいます。
中央値を2で割っているのはそのままでは消えすぎ感があったからです。もうちょっと工夫の余地があるかも。
前の方法だと状況に左右されすぎていたのでもっと単純にmaxで考えることにしました。これだと声が小さいデータの場合ほとんど残らなくなってしまうので、そこそこのボリュームで録音する必要があります。
結果
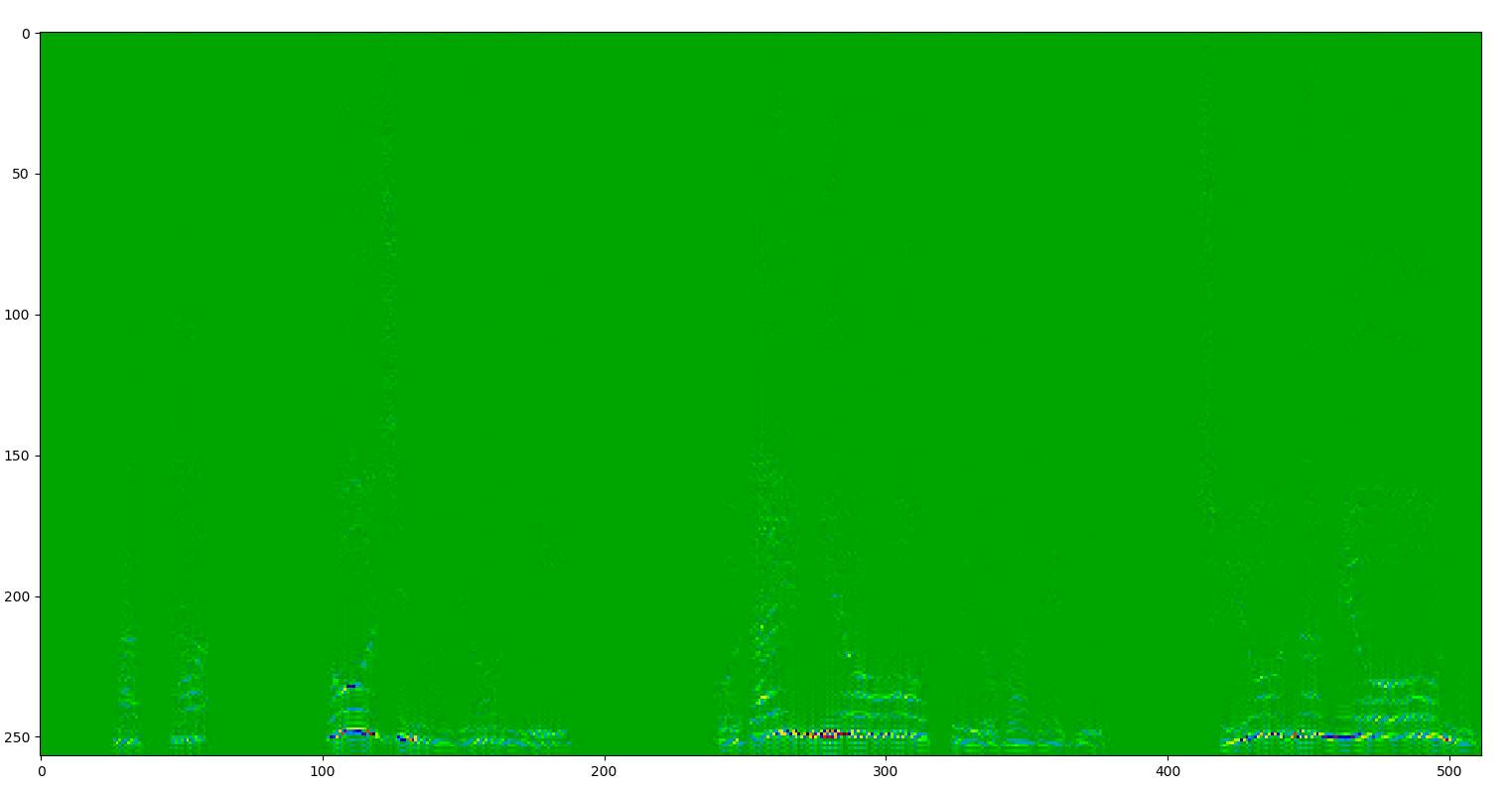
スペクトルを載せときます。
before
after
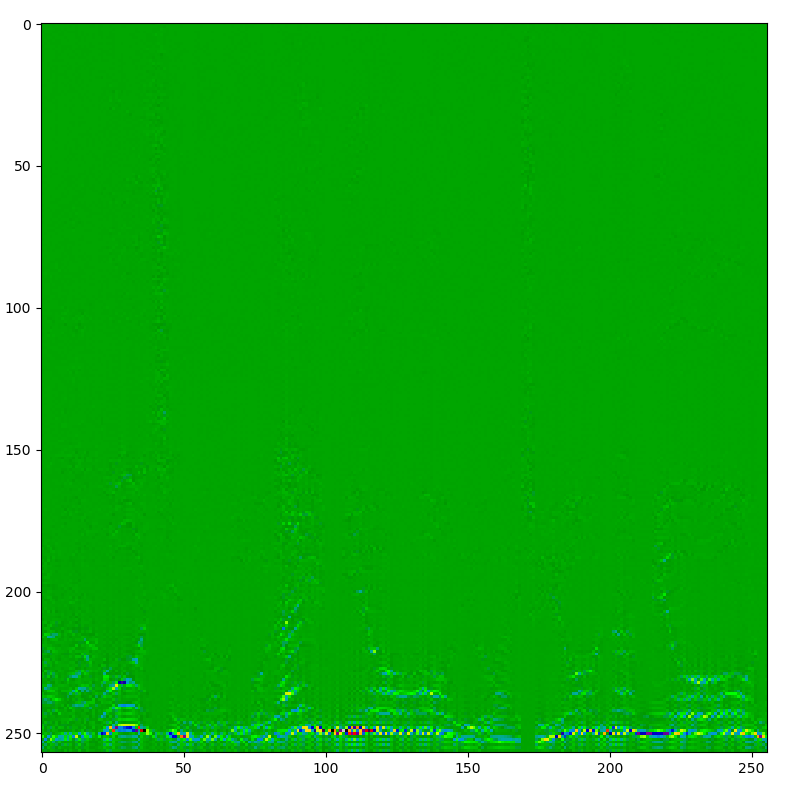
(高周波帯は出力していません)
しっかり削除されているのがわかります。音をチェックしても消えすぎずちょうどいい具合でした。
もっと普遍的な感じのやり方があればいいなあ