概要
本記事の目的は、バックエンドにDjangoを用いたコンテナアプリケーションのロギングインフラ構築に関する知見の整理です。「コンテナアプリケーション」「Django」それぞれのロギングに関する記事はそれなりにあるものの、それらを全体的にまとめてアーキテクチャレベルで扱ったものはあまりないなと感じたのと、自分がまだ理解しきれていないことや、どういうことを考えて現状のアーキテクチャになったのか、参考にした記事等、備忘録がてら残しておこうという感じです。嘘や間違い「もっとこうしたら」等ありましたら優しくご指摘いただけると幸いでございます。かなり他力本願です。
完成したアーキテクチャ
以下がひとまず完成している「ログの出力から検知」までを扱ったアーキテクチャです。AWSサービスをメインに構築しています。
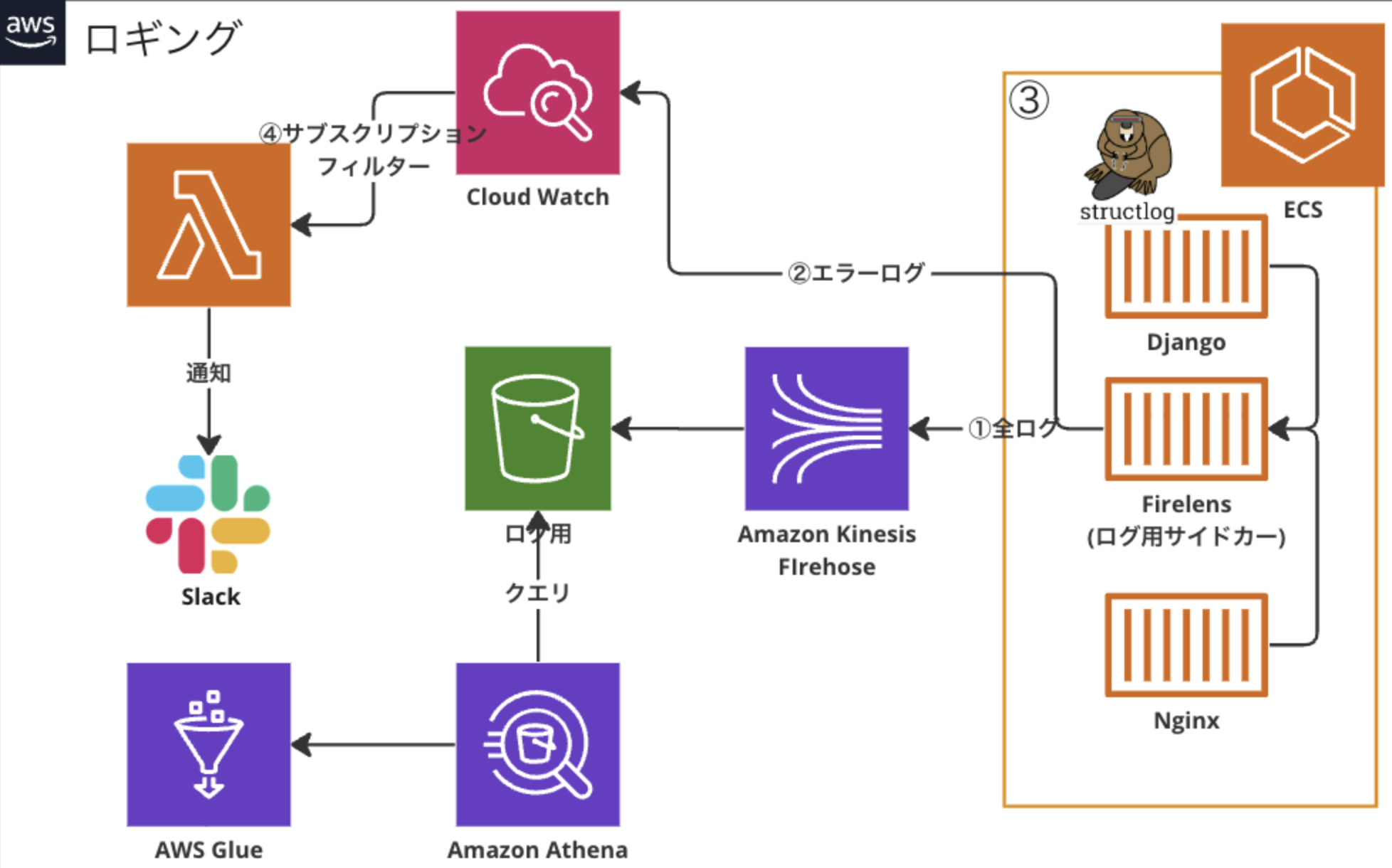
前提
バックエンドにdjango,そしてwebサーバー(Nginx)というおそらく割と一般的であろうアプリケーション構成になっています。今回はとりわけ「Djangoコンテナアプリが出すログ」をどうやって上手く扱ってやろうかというのが主なテーマになります。以下、どういうことを考えて上記構成になったかをつらつらと書きます。かなりアバウトな説明になってしまっている点ご容赦ください。
コンテナアプリケーションには「状態」を持たせられない
djangoとNginx(ンぎんくす)は割とみたことあるけれど、Firelensって何?という方もいらっしゃるかもしれません。これを理解するには「ステートフル」なサーバー環境とは違った、「ステートレス」なコンテナアプリ特有のロギングの課題について理解していただく必要があります。
二つのサーバー環境を更新する際の違いを考えてみます。従来型のいわゆる自分でホストするアプリの更新は、元あったものの一部分を更新します。したがってその他の更新に関係ない部分に関しては、その状態を保持したまま残ります。一方でコンテナで構築されたアプリケーションの更新は、基本的にベースの設計図(Dockerfile)のようなものがあり、それを元に更新差分を含め全取っ替えします。ギターの弦交換に例えると、最初の頃はチョーキング(1,2弦を酷使する奏法)が下手くそで1,2弦とか一部の弦がすぐ切れます。本当によく切れるので、いちいち全ての弦を新しいものに変える金銭的余裕がなくなり、切れた弦だけを交換していました。(「ステートフルな更新」)しかし、上手になってくると不自然なサイクルで一部の弦が切れることがなくなり、大体切れる時には「他の弦もそろそろ変えたほうがいいな」という頃合いになっています。すると一定の期間が過ぎて全部の弦を一斉に張り替えることが多くなります。(「ステートレス」なアプリの更新)要は更新のたび、元の状態にリセットされるのです。特に、どちらが優れているという話ではないですが。
ログに話を戻します。「ステートフル」な環境では、ログ(交換しない弦のサビ)を更新後に残すことができますが、「ステートレス」なコンテナアプリでは、アプリケーション内に残しておいたログ(状態)は更新のたび、リセットされて消えてしまうのです。「ログ」は基本的に後から忘れた頃に見たいものなので、見たい時になって消えてしまっていたら大変困ります。人が寝て起きたら大抵の出来事を忘れてしまうことを憂い、日記を書くなり記憶を外部化するように、出力されたログをどこか記録・保存用の場所に移さねばなりません。(ログルーティング)そういった仕組みを担っているのが、AWSがFargateを用いたアプリのために提供しているFirelensとなります。
Firelensに関する技術的な詳細は、下記のDeNAのエンジニアの方々のBlogが大変参考になりましたので、ご参照ください。
記憶の外部化に失敗する
「そうか、外部ストレージにログを転送してやる必要があるのだな」と理解したところで方法を探っていたところ、以下の記事に出会いました。
本記事の構成もかなりこの方のブログを参考にさせていただいております。CDKをある程度触ったことがある方なら、実際にコードサンプルも載せていただいていますし、参考にしていただけるといいと思います。
しかし、困った問題が一つ。実際にこの記事ではAWSが管理しているfluent-bit(実際にログ用コンテナ内でログルーティングを実現している本体)の公式のDockerイメージを使用しているのですが、その管理すらもめんどくさいと感じてしまい、何か他に方法はないかと探っていたところ、どうやらECRのパブリックギャラリーに公式のものが落ちているらしいことを知り、それを使おうとなりました。以下のクラメソさんのブログみたいな感じです。
すると横着したのが良くなかったのか。。。
なんかmultilineのpython parserがうまく動かないな...となり、ちょっと長めのログがこんな感じでちょちょぎれた状態で、S3に送られてしまうようになりました。

なんか微妙ですよね。Djangoで出たTracebackとかもこんな感じで切れて送られちゃうので、ちょっととてもじゃないけど見やすい状態とは言えない感じで、悩んでいました。
ここで本当ならfluent-bitの方の設定を真面目にやらなきゃいけなかったのですが、なんとなく敬遠してしまって、他の方法を探すことに。
structlogとの出会い
先に述べたように、fluent-bitの設定を頑張るのはログをどう受け取るかに対するアプローチだと思うのですが、その前にログの出し方を変えたらどうかというところで「構造化ロギング」というものに出会いました。ざっくり説明するとログとしてただのテキストデータを出力するのではなく、keyとvalueのセットでもって、構造化した上で改めてjson形式でログを出力するというものです。本当にざっくりとした感覚ですが「一個一個途切れ途切れで送るのではなくて、まとめてくれるのでいけそう」となり、実際に頑張って設定してみました。実際の設定内容に関しては、以下記事の設定をほぼ流用させていただき、オリジナリティといったら、日本標準時のタイムスタンプ入れるためにJST変換するプロセッサを組んだくらいでしょうか。
使い方そのものに関しては以下が詳しいです。
一応、設定も載せておきます。
LOGGING = {
"version": 1,
"disable_existing_loggers": False, # デフォルト設定を無視
"formatters": {
"colored_console": {
"()": structlog.stdlib.ProcessorFormatter,
"processor": structlog.dev.ConsoleRenderer(colors=True),
},
"json_formatter": {
"()": structlog.stdlib.ProcessorFormatter, # フォーマットに使用するクラス
"processor": structlog.processors.JSONRenderer(ensure_ascii=False), # ログをjsonフォーマットへ変換
}
},
"handlers": {
"console": {
"class": "logging.StreamHandler",
"formatter": "colored_console",
},
"json": {
"class": "logging.StreamHandler",
"formatter": "json_formatter",
"stream": "ext://sys.stdout", # 標準出力へ
},
"null": {
"class": "logging.NullHandler",
},
},
"loggers": {
# アプリケーション内のログ
"apps": {
"level": DJANGO_LOG_LEVEL,
},
"django_structlog": {
"level": DJANGO_LOG_LEVEL,
},
# structlogミドルウェア
"django_structlog.middlewares": {
"level": DJANGO_REQUEST_LOG_LEVEL,
},
"jobs_aggregator": {
"level": DJANGO_LOG_LEVEL,
},
# DBログ
"django.db.backends": {
"level": DJANGO_DATABASE_LOG_LEVEL,
},
# structlogのmidlewareを使うので純正のdevサーバ,requestログは捨てたい
"django.server": {
"handlers": ["null"],
"propagate": False,
},
# Use structlog middleware
"django.request": {
"handlers": ["null"],
"propagate": False,
},
},
"root": {
"level": "WARNING",
"handlers": ["console"]
}
}
def jst_timestamp_formatter(_, __, event_dict):
tz = pytz.timezone('Asia/Tokyo')
event_dict["timestamp"] = datetime.now(tz).strftime("%Y-%m-%d %H:%M:%S.%f %z")
return event_dict
base_structlog_processors = [
structlog.contextvars.merge_contextvars, # 実行中のコンテキストから変数をマージ
structlog.stdlib.filter_by_level, # ログレベルのフィルタリング
structlog.processors.TimeStamper(fmt="iso"),
structlog.stdlib.add_logger_name,
structlog.processors.add_log_level, # ログエントリにログレベルの情報追加
structlog.processors.CallsiteParameterAdder( # フォーマットかける前に必要
{
structlog.processors.CallsiteParameter.FILENAME,
structlog.processors.CallsiteParameter.FUNC_NAME,
structlog.processors.CallsiteParameter.LINENO,
}
),
jst_timestamp_formatter, # 日本標準時へ変更
structlog.stdlib.PositionalArgumentsFormatter(), # 変数、文字列連結できる(format関数)
structlog.processors.StackInfoRenderer(), # スタックトレースの追加
structlog.processors.format_exc_info, # 例外発生時の詳細情報(例外の種類、メッセージ、スタックトレース)を追加
structlog.processors.UnicodeDecoder(), # バイト列→Unicode(Python3ではデフォルトでUnicodeとして扱う)
]
base_structlog_formatter = [structlog.stdlib.ProcessorFormatter.wrap_for_formatter] # python標準のloggingモジュールとの互換性維持
# ログイベントを渡すprocessorの設定(順番に渡される)
structlog.configure(
processors=base_structlog_processors + base_structlog_formatter,
logger_factory=structlog.stdlib.LoggerFactory(), # python標準のloggingモジュールとの統合
cache_logger_on_first_use=True, # ロガーインスタンスをキャッシュし、パフォーマンス向上
)
ログとしては、こんな感じで出ます。
{
"container_id": "id[自分のコンテナ]",
"container_name": "django",
"source": "stderr",
"log": "{\"code\": 500, \"request\": \"GET /path/to/edit/3\", \"event\": \"request_failed\", \"ip\": \"\", \"user_id\": 1, \"request_id\": \"81618510-4482-48a2-b847-fa5debb3a60f\", \"timestamp\": \"2023-12-20 16:05:21.408228 +0900\", \"logger\": \"django_structlog.middlewares.request\", \"level\": \"error\", \"func_name\": \"process_exception\", \"filename\": \"request.py\", \"lineno\": 103, \"exception\": \"Traceback (most recent call last):\\n "}",
"ecs_cluster": "クラスタ",
"ecs_task_arn": "arn:aws:ecs:ap-northeast-1:????????:task/hoge",
"ecs_task_definition": "task:rev"
}
見やすいかと言われると微妙ですが、まぁ切れて送られてくることは無くなりました。structlogの設定には、そもそもPythonのロギングモジュールを気合い入れて理解しないといけないみたいなところがあるので、structlog頑張る前にそっちを理解したほうがいいかもしれません。参考リンク置いておきます。
本当はfluent-bitの設定ちゃんとやるべきだと思うんですけどね...
エラーをslackに流す
AWSでSlack連携で通知流そうと思った時にChatbotが最初に浮かびました。
というのもCodePipelineの通知はChatbot経由でやっていたので、なんとなくサブスクリプションフィルタ設定してフィルタリングされたものをSNSTopicに渡し、そのままSlackへgoかなと思っていたら、なんとChatbotの対象サービスにLambdaが含まれておらず、通知が行きませんでした。
結果的にはSlackのwebookを使用して直接Lambda内でSlackのAPICallするような実装になりました。
参考はこの辺です。
→この例の受け取り元をSNSではなくCloudWatchイベントに変えている感じです。
まとめ
自分自身、さまざまなソースを探りながらbetterなものを選んでいったので、次同じような構成を作るタスクをもらった人が、この記事をみて少しでも調べる手間を省けたり、気をつけるべきポイントを早く抑えられるといいなと思います。あと要件がエラー検知だけかつ4000円/月くらい許せる場合、Sentryで間に合うだろうなと思いました。ただケースとして、何かしら監査用のログを残さなければいけなかったり、CloudWatchに直流しするのはお財布が許さなかったり色々あると思うので、今回の構成でしっかりと監査ログ等残しつつ、Sentryを便利に使用して障害時のdebug速度を早めるという選択肢は全然アリだなと思いました。
参考