最近、因果推論・因果探索について勉強したので、
DeepLearning・GANを使用した因果探索の手法であるSAM(Structural Agnostic Modeling)[2018]のPython実装例を記載します。
最も有名であろうベイジアンネットワークについては別記事にて後日実装例を公開してみたいと思います。
本記事はSAMのみになります。
データはTitanicデータを使用しました。
#目次
#1. ゴール
ゴールは下図のように、データから因果関係の有無・方向性を算出することです。
これを因果探索と呼びます。
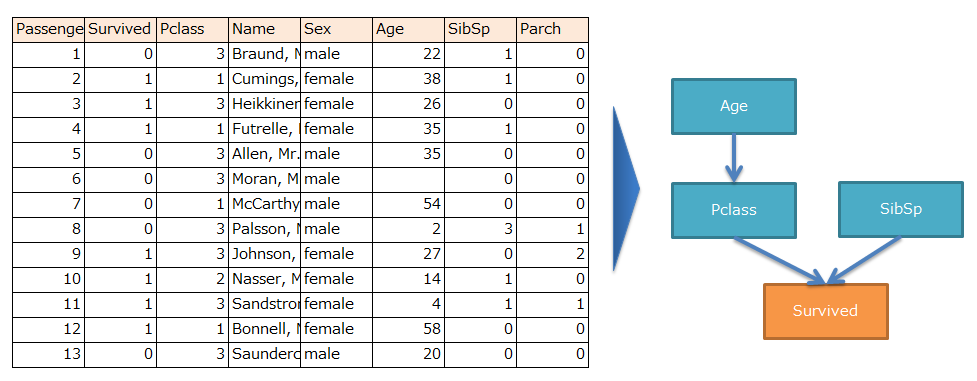
一方、これらの因果関係(矢印)の大きさを推定することを因果推論と呼びます。
#2. 因果関係とは
そもそも、因果関係とは何かを簡単に説明します。
「ある変数Xを大きくしたらある変数Yも大きくなる」傾向になる場合、
変数Xから変数Yへの因果関係があると言います。
この言葉を聞くと、相関係数と何が違うの?という疑問を持つ方がいらっしゃるかもしれないので違いを説明します。
有名な話として**「国民のチョコレートの消費量が多くなるほどノーベル賞受賞者が増える」という言葉を聞いたことがあるかと思います。
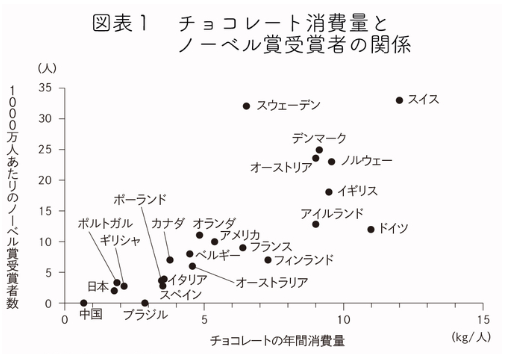
図を見ると、これら2つの変数間に相関関係はありそうです。
ただ、これら2つの変数間に因果関係**があるかどうかは別の話になってきます。
一般的に、チョコレートは嗜好品であり、裕福な国ほど消費量が多くなると考えられます。
また、裕福な国ほど教育にもお金をかけられるようになり、ノーベル賞受賞者を輩出できる可能性は上がると考えられます。
したがって、下図のように、裕福さを表す指標である「1人あたりGDP」のような変数が関係していると考えられます。
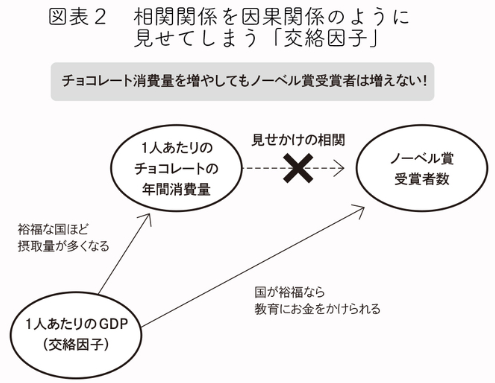
このような見せかけの相関を擬似相関といい、疑似相関を生み出す変数を交絡因子と呼びます。
擬似相関関係にある変数同士は因果関係があるとは言いません。
ただ、相関係数を計算するとそこそこ大きな正の値になると思うので、相関関係はあることになります。
ここで改めて用語についてまとめておきます。
- 相関関係がある:変数Xの値が大きいとき、変数Yも大きい傾向にあること
- 因果関係がある:変数Xの値を大きくすれば、変数Yも大きくなる傾向にあること
- 擬似相関がある:変数XとYに相関関係はあるが、因果関係はないこと
因果関係では、Xを大きくすればYも大きくなる、というところがポイントになります。
また、いずれの関係にある場合も相関係数の絶対値は大きい値を取るので、
相関係数だけではこれらの区別はつきません。
参考:チョコレートの消費量が増えるとノーベル賞受賞者が増える?
#3. SAMとは
これまでの内容を踏まえた上で、因果関係の有無・方向性を探索する手法について説明します。
本記事ではDeepLearning・GANを使用した因果探索の手法であるSAM(Structural Agnostic Modeling)[2018]について超簡単に説明致します。
最も有名であろうベイジアンネットワークについては別記事にて説明したいと思います
##3-1. 概要
SAMはDeepLearningのGAN(Generative Adversarial Network)の技術を用いて因果探索を実現する手法です。
一般的にGANは大きく生成器・識別器から構成されており、それぞれ以下の役割を持ちます。
- 生成器:ノイズを入力とし、学習させたデータに近い偽物データを生成する
- 識別器:入力データが本物か偽物かを識別する
SAMでは説明変数数×説明変数数の因果を表すマトリクスを生成器のforward関数に与え、生成器の学習時にこのマトリクスも学習させます。
マトリクスは0から1の値を持ち、閾値以上の値を持つ部分を因果があると判定します。
以下のようなイメージとなります。(閾値は0.9)
※対角成分は0とします。
※上で使用した数値は学習済みのものではなく乱数を使用しています。
かなりざっくりとした説明ですが、詳細について知りたい方は以下文献をご参照ください。
- SAM(Structural Agnostic Modeling)[2018]
- SAM著者らのGithub
- 作りながら学ぶ!Pythonによる因果分析(小川雄太郎 著 2020)
#4. 実装例
SAM(Structural Agnostic Modeling)[2018]のPython実装例を記載します。
##4-1. コードとデータのダウンロード
下記GitHubからSAM_titanic.ipynbとtitanic.csvをダウンロードしてください。
https://github.com/yuomori0127/SAM_titanic
GoogleColabでコードを見てみたい方はコチラ
##4-2. 環境準備
環境はGoogleColabを使用しました。
使用方法は以下の記事をご覧ください。サーバ代は無料です。
Google Colabの使い方まとめ
GooleDriveの任意のフォルダに先程ダウンロードした2ファイルを入れてください。
##4-3. コード実行
GooleDriveからSAM_titanic.ipynbをGoogleColabで開いてください。
※初回はインストール的なのが必要だった気がします。
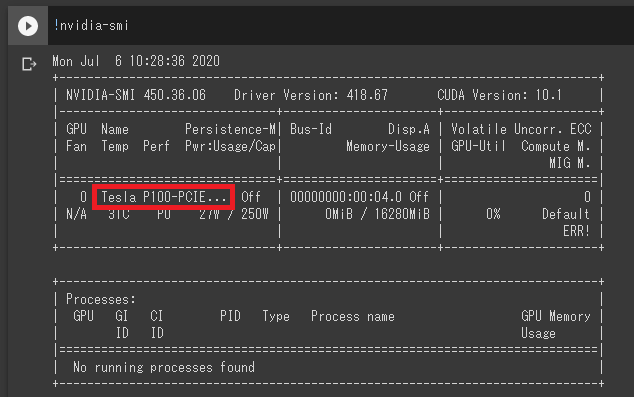
まずはGPUのリセマラが必要です。
一番上の!nvidia-smi を実行(Shift + Enter)し、Tesla P100が出るまでリセマラしてください。
大体5回以内で引けます。
リセットは以下からできます。
以下コードのフォルダ名(causal_book部分)をGoogleDrive上の.ipynbとcsvが置いてあるフォルダ名に変更してください。
import os
os.chdir("./drive/My Drive/causal_book/")
ランタイム->すべての処理を実行を実施すると全て実行してくれます。
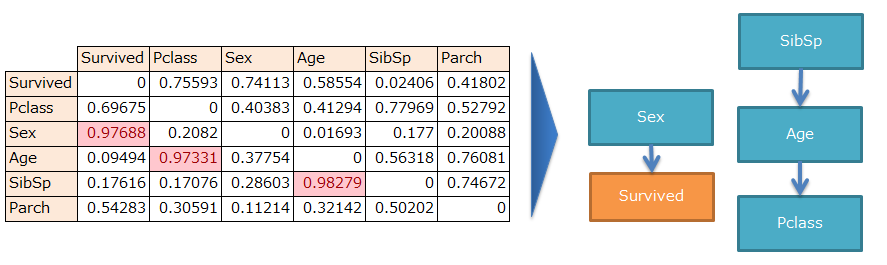
実行結果をまとめると、以下のようになります。(閾値0.6)
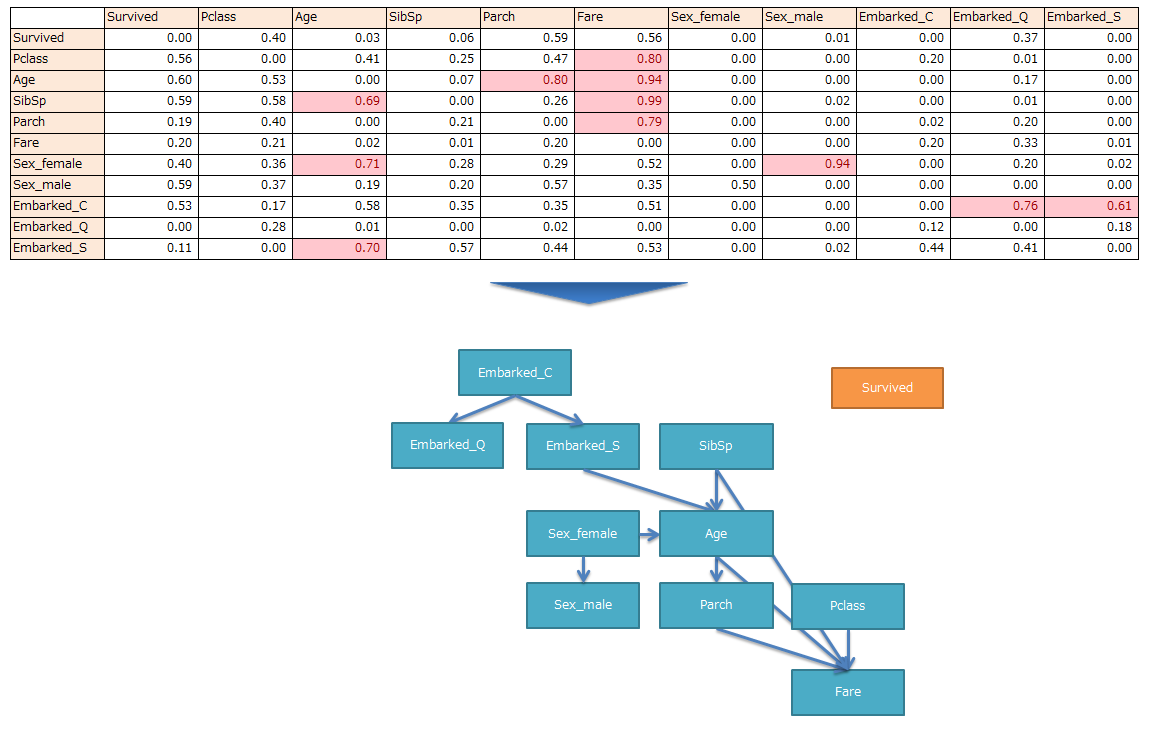
※コードから出力されるのはマトリクス部分だけです。
目的変数であるSurvivedが浮いてしまう(どの説明変数とも因果がない)という結果となりましたw
#5. 最後に
一応DeepLearning・GANを用いた因果探索を行うことはできたのですが色々問題点はあります
・SAMはランダム性が非常に高く学習結果が全く安定しない
実行例は5回実行した結果の平均値をとっています。論文では16回の平均を取っていました。
・出力結果の評価が出来ない
論文では正解がある前提でAPやハミング距離を用いて評価していたが、実運用上それはできない。
perprexityみたいなものがあれば良いのだが。
・離散値がそのまま使えないのでget_dummies後の説明変数で因果を出すことになる
これはもしかしたら私の勉強不足かもしれません。
このように実運用を考えるとなかなか難しい点が多いです。
まだまだこれから発展していく分野なのかもしれません。
#参考文献
- チョコレートの消費量が増えるとノーベル賞受賞者が増える?
- SAM(Structural Agnostic Modeling)[2018]
- SAM著者らのGithub
- 作りながら学ぶ!Pythonによる因果分析(小川雄太郎 著 2020)
- 効果検証入門(安井翔太 著 2020)