本記事は OpenShift Advent Calendar 2024 の 12/16 の記事です。
時の流れはあまりに早く、気づけば本来の投稿日を大幅に過ぎてしまっておりました。
OpenShift のモニタリングダッシュボード?何それ?
OpenShift 上で動かしているアプリケーションに何か問題が起こったとき、どのように原因を突き止めるか悩んだ経験はありませんか。Podの状態やログ、アラート、イベント等いろいろな手がかりがありますが、手がかりの一つとしてWebコンソールにモニタリングダッシュボードが用意されています。
OpenShift ではデフォルトで Prometheus が動作しており、OpenShift を構成するコアプラットフォームコンポーネントのメトリクスを取得しています。PromQL クエリを自分で書いてメトリクスを分析することもできるのですが、一からクエリを書くのは簡単ではありません。モニタリングダッシュボードはデフォルトで用意されており、Prometheus のメトリクスを主にグラフとして表示することで、クラスターの状態を素早く視覚的に把握することができます。
モニタリングダッシュボードは、Webコンソールの管理者向け画面の左側のメニューから、モニタリング -> ダッシュボード (英語UIの場合:Observe -> Dashboards) と選択することで表示できます。

クラスターインストール後のデフォルトでは以下のダッシュボードが用意されています。

それぞれのダッシュボードでどんなことがわかるか
それぞれのダッシュボードの概要について説明します。
API Performance
Kubernetesクラスターの中核となるコンポーネントであるkube-apiserverや、OpenShift 特有のリソースのAPIサーバーであるopenshift-apiserver、OpenShift の OAuth 認証機能を提供するopenshift-oauth-apiserverのそれぞれに関して、API リクエストの性能や負荷状況を表示できます。
etcd
クラスターの状態を管理する etcd に関して、その動作状況、バックエンドストレージへのコミットにかかった時間、リソース使用量、リーダーの再選出の回数などを表示できます。
Kubernetes / Compute Resources / から始まるダッシュボード
Kubernetes / Compute Resources / Cluster
Kubernetes / Compute Resources / Namespace (Pods)
Kubernetes / Compute Resources / Namespace (Workloads)
Kubernetes / Compute Resources / Node (Pods)
Kubernetes / Compute Resources / Pods
Kubernetes / Compute Resources / Workload
クラスターのコンピュートリソース (CPU、メモリ、ネットワークトラフィック、ディスクI/O) の使用量 について、クラスター全体、各Namespaceごと、ノードごと、Podごと、Workload(DeploymentやStatefulset等) ごとに表示できます。
Kubernetes / Networking / から始まるダッシュボード
Kubernetes / Networking / Cluster
Kubernetes / Networking / Namespace (Pods)
Kubernetes / Networking / Pod
クラスター内のネットワーク状況 (受信/送信のデータ量やパケット数、ドロップやTCP再送したパケットの割合) が、クラスター全体、Namespaceごと、Podごとに表示できます。
Networking / Infrastructure
Podの作成/削除におけるレイテンシ、Pod間やPodから外部への接続におけるTCPのレイテンシ等を表示できます。
Networking / Ingress
Ingress (HAProxyなど) を経由する HTTP リクエストのトラフィック状況、エラー率や応答のレイテンシなどを可視化し、Ingressの負荷状況や健全性を確認できます。
Networking / Linux Subsystem Stats
ネットワークにおける送受信量やエラー・ドロップ数をノード単位・インターフェース単位で可視化し、ネットワークの負荷や異常を監視できます。
Node Cluster
クラスターの各ノードの稼働状況とリソース利用状況をモニタリングし、異常や過剰な負荷が発生していないかを監視します。具体的には、ノードの Ready ステータスや、コンテナランタイム CRI-O におけるOOM 発生件数、イメージプルの失敗率、また各ノード上で動作するシステムサービス (kubelet や CRI-Oなど)が利用しているメモリとCPUの割合を可視化し閾値を超えていないか確認します。
Node Exporter / USE Method / から始まるダッシュボード
Node Exporter / USE Method / Cluster
Node Exporter / USE Method / Node
システムの性能の問題を特定するための USE Method (U:Utilization, S:Saturation, E:Errors) を用いて、ノードのリソース不足や性能上のボトルネックの兆候を把握できます。具体的には、CPU利用率(Utilization)、CPUコアあたりのロードアベレージ(Saturation)、メモリ使用率(Utilization)、メジャーページフォールトの発生率(Saturation)、ネットワーク受信/送信量(Utilization)、ネットワーク受信/送信ドロップ数(Saturation)、ディスクI/O時間(Utilization)、キューでの待機時間を含めたディスクのI/O時間(Saturation) を確認できます。
Prometheus / Overview
メトリクスの取得を行うPrometheus自体を監視できます。監視対象の同期にかかる時間や監視対象の数、スクレイピングの失敗や、新しいデータポイント(サンプル)が書き込まれる頻度などを表示できます。
実際にモニタリングダッシュボードを眺めてみる
実際にダッシュボードを見てみましょう。今回は特定のノードで動くアプリにおいて一時的に応答が遅い問題が起こっていたとします。Node Exporter / USE Method / Node を見ると、10:30-10:50 頃にかけて CPU 利用率が 100% に張り付いており、CPUコアあたりのロードアベレージも3前後だったことがわかります。
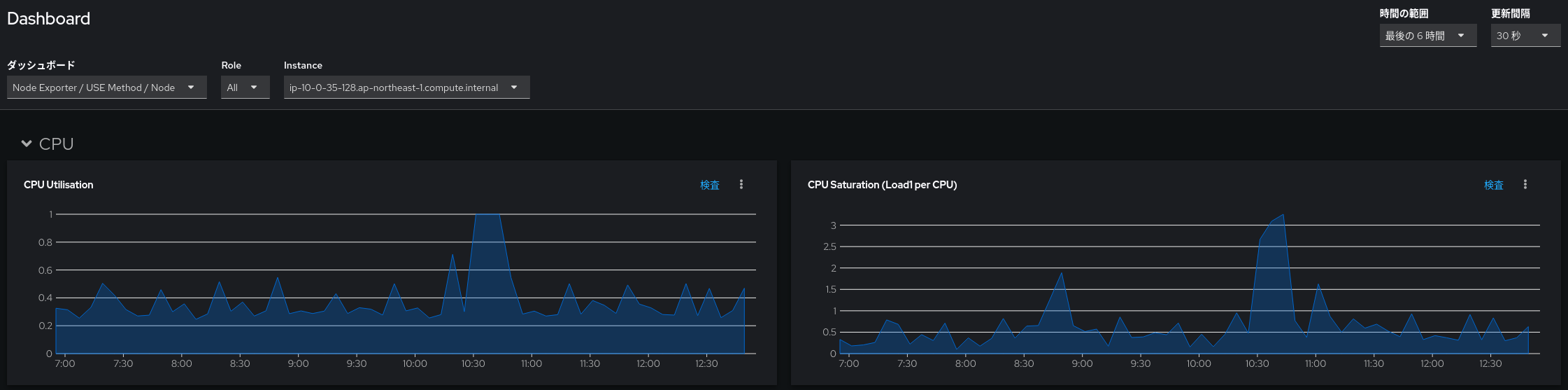
グラフの縦軸の値が何なのかより詳細を知りたい場合、グラフのもとになる PromQL クエリを各グラフ右上の「検査 (inspect)」 から確認できます。「検査」をクリックして表示されるのが以下の画面です。例えば CPU Saturation (Load1 per CPU) というグラフは以下の PromQL クエリをもとにしていることがわかります。
instance:node_load1_per_cpu:ratio{job="node-exporter", instance="<ノード名>", cluster=""} != 0

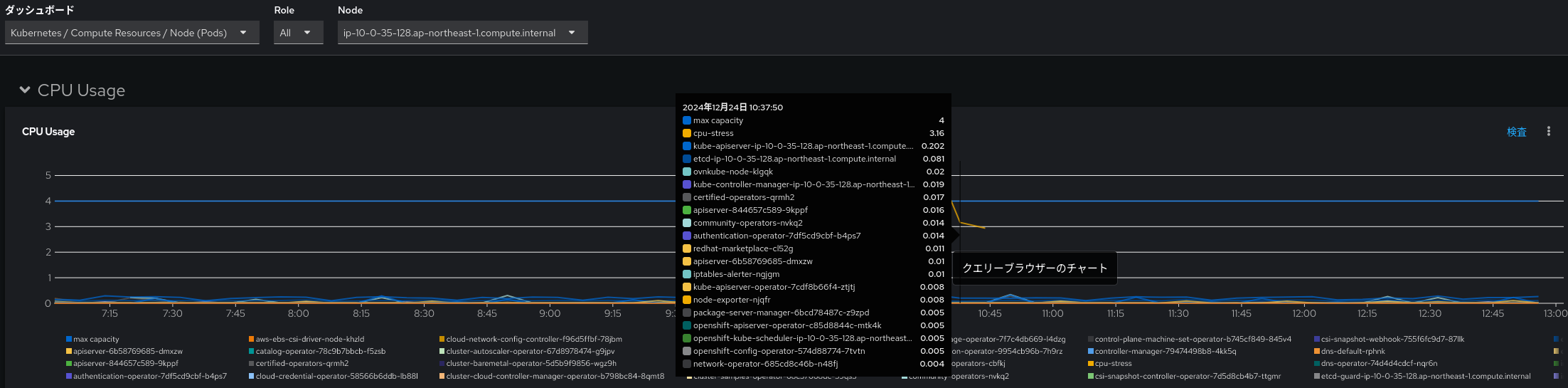
続いて、さきほどの Node Exporter / USE Method / Node のグラフにおけるCPU利用率の高騰やロードアベレージの上昇は何に起因しているのかも見てみます。特定のノードにおける問題ということがわかっているので Kubernetes / Compute Resources / Node (Pods) のダッシュボードを表示し対象のノードを選択します。CPU Usage のグラフ上で、問題が起こっていた時間帯のグラフにマウスオーバーすると cpu-stress という Pod が多く CPU を使っていたことがわかります。テスト用に while true; do :; done & というコマンドを多重で実行する Pod を動かしていたのでした。
その他 Tips
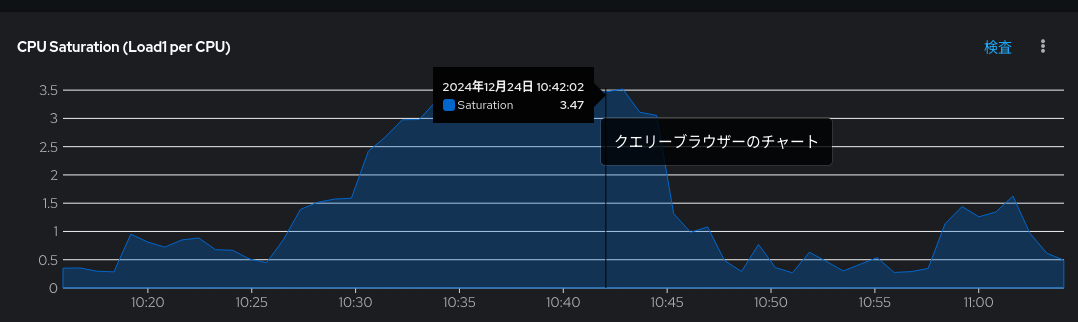
- ダッシュボードの画面右上の「時間の範囲(Time Range)」から「カスタム時間範囲(Custom time range)」を選び表示したい時間の範囲を選択したり、単に表示したいグラフの範囲をマウスカーソルで選択したりすると、より短い時間幅で拡大されたグラフを見ることができます。


-
「検査(inspect)」の右側にあるメニューボタンを押すと、Export as CSV と表示され、ダッシュボードのグラフの元となるデータを CSV 形式でダウンロードすることができます。外部ツールでのより詳細な分析も可能となります。こちらは OpenShift 4.17 で追加された機能です。
-
ユーザー定義のプロジェクトのメトリクスはデフォルトでは取得されません。追加設定により取得できます。
-
コアプラットフォームコンポーネントのメトリクスの保存期間はデフォルトで15日間です。保存期間は変更可能です。
さいごに
今後もし OpenShift 環境で何か問題が起きたとき「そういえばモニタリングダッシュボードってのもあったな...」と思い出していただければ幸いです。それではよいお年を!