概要
1. Embeddingsとは
Embeddingsとは単語やテキストをベクトルデータとして表現する技術
2. よくある要望
ChatGPTが知らないドメイン知識をベースとした回答をさせたい
3. Embeddingsを使ったソリューション
- あらかじめドメイン知識をEmbeddingsでベクトルデータにしてDBに保存する
- ユーザの質問に答える前に、関係のありそうなドメイン知識をDBから取得して、プロンプトに加える
- ChatGPTがそれをもとに回答するので、ドメイン知識に即した回答をしてくれる
4. このソリューションの課題
以下のような問題で正しくない回答をする可能性がある。
- 関連するデータが取れないから答えも違う
- 取得された関連データが不十分で答えが不十分
- 関連情報は取得できたが、答えが違う
※ 詳細は本文で記載しています。
実装方法
2ステップで実装をすることができます
1️⃣ ドメイン知識のデータベースを作る
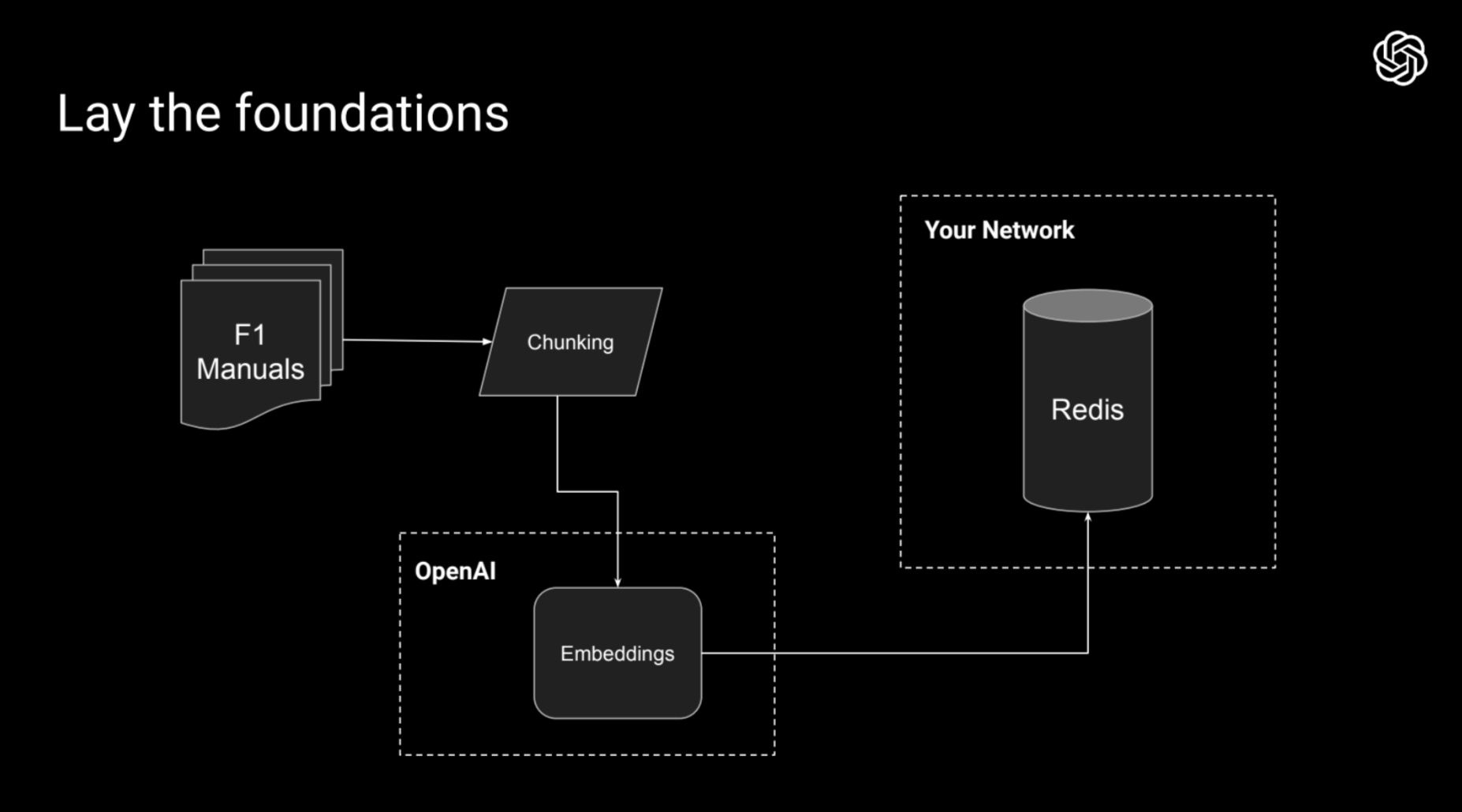
- ドメイン知識が記載されたテキストデータを用意する
- Chunkingで短い文章に区切る (100文字で区切る、文章で区切る、ずらしながら区切るなど工夫可能)
- Embeddings APIで文章をベクトル化させる
- ベクトルデータをDBに保存する
2️⃣ プロンプトにドメイン知識を追加する
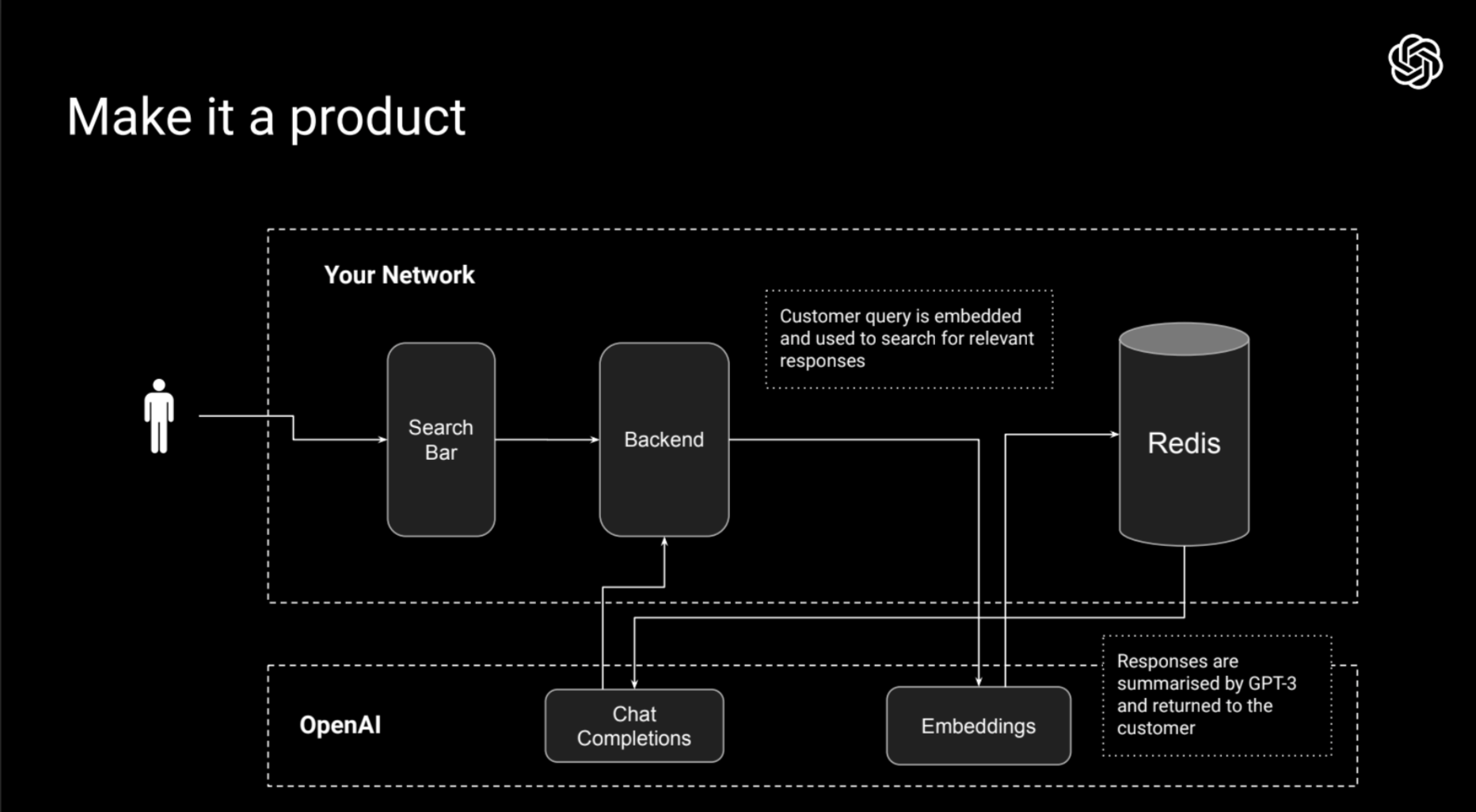
- ユーザ入力をEmbeddingsでベクトル化
- ベクトルのコサイン類似度の高いデータをDBから複数件取得する
- プロンプトの末尾に取得したデータを追加する
- プロンプト内に「以下の情報を使って回答してください。もし関連する情報がなければ回答できないことを伝えてください」等の文章を加える。
課題

正しい回答をするためには、「正しくドメインデータを取得できて」「正しくそこから答えを作る」ができて初めて達成できます(画像の右上)。どちらかをミスると正しくない回答になります。
-
関連するデータが取れないから答えも違う
- 関連情報の検索部分を改善必要
- 具体例: QAシステムに導入したが、ユーザ自身検索ワードが分かっていないので、曖昧な入力をしてしまい、関係ない情報を引っ張ってきてしまう。
- 具体例: 住宅レコメンドシステムに導入したが、家賃15万円以下という明確な要望があるのにベクトル検索では明確な条件検索ではないため、家賃20万円の家も出してしまう
- 関連情報の検索部分を改善必要
-
取得された関連データが不十分で答えが不十分
- 不完全なデータ取得になっているのでChunkingを改善する
- 具体例: ニュース記事の分析システムにおいて、記事の全文を分析すべきなのに、システムが一部の段落しか取得していないため、その情報だけでは結論を導き出せない状況が発生する。
- 不完全なデータ取得になっているのでChunkingを改善する
- 関連情報は取得できたが、答えが違う
- プロンプトの改善が必要
- 具体例: 関連情報を使って回答を作成する部分のプロンプトがイマイチだと、勝手にAIが解釈を加えたり、関連情報を掛け合わせて嘘を作り出してしまうことがある。
- プロンプトの改善が必要
やってみた (そして皆さんもやってみよう!)
LangChainなどのライブラリを活用して上記を実装するのが一般的だが、自分はStateful APIで利用可能なEmbeddingのシステムを作ってみました。
インフラ不要でEmbeddingsを試せるので、ぜひ使ってみてください(╹◡╹)
使い方
1️⃣ ドメイン知識のデータベースを作る
テキストデータとグループ名をAPIで登録する。
import axios from "axios"
const apiKey = "sk-XXX(OpenAI APIKey)"
async function addEmbedding() {
const inputList = ["LangCoreは2023年設立", "LangCoreはChatGPTをレベルアップさせる"]
const groupName = "default_group"
for (const text of inputList) {
const url = "http://langcore.org/api/embeddings"
const headers = {
Authorization: `Bearer ${apiKey}`,
"Content-Type": "application/json",
}
const data = {
input: text,
groupName: groupName,
}
const res = await axios.post(url, data, { headers })
console.log(res.data)
}
}
addEmbedding()
上記のコードでは、適当なテキストを学習させていますが、自分は自社のテーブル定義を学習させてデータベースを作りました。
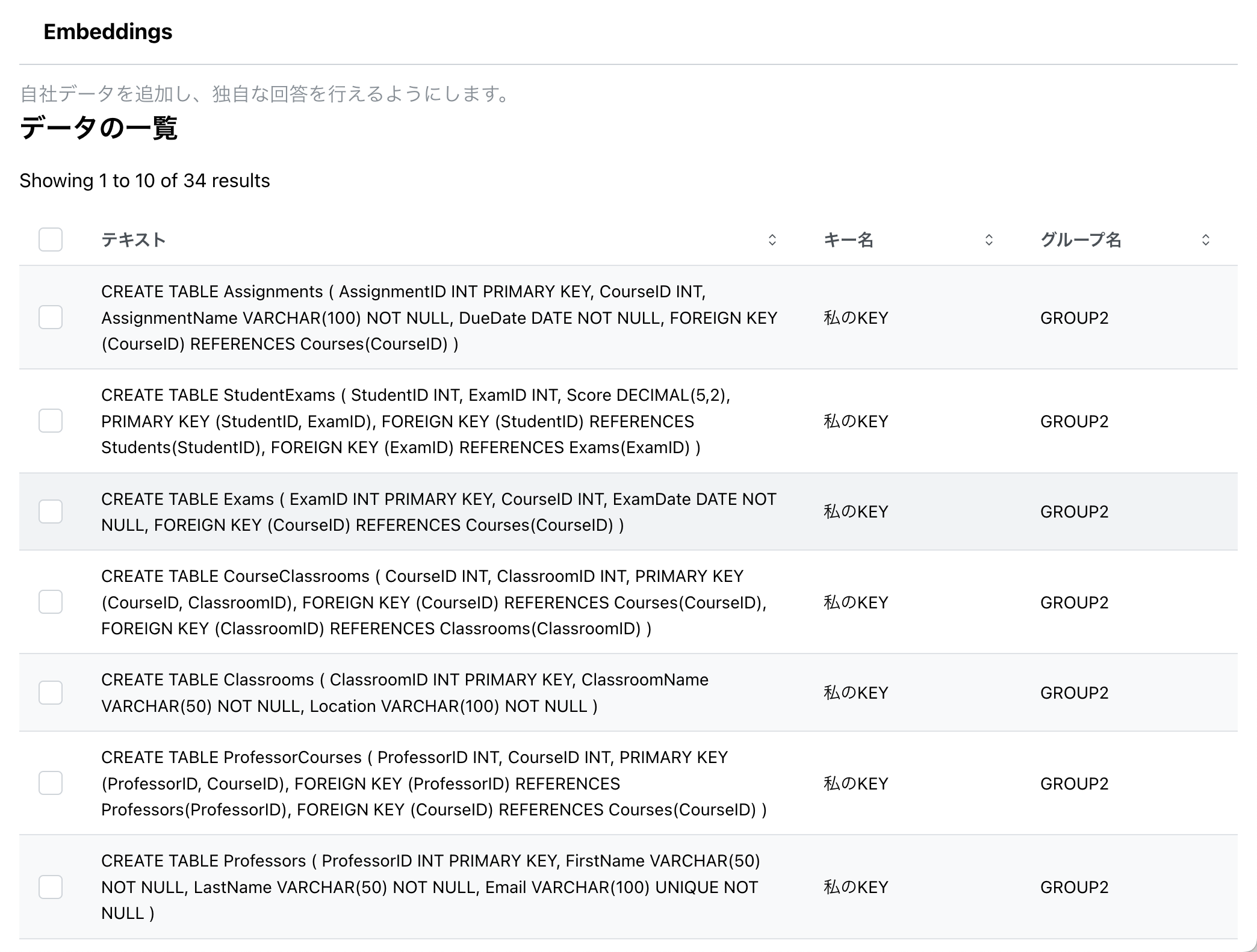
※保存したデータは LangCore で管理することができます。
2️⃣ プロンプトに関連する知識を追加する
- queryに質問を入れる
- プロンプトに{{EMBEDDINGS_CONTEXT}}を入れるとそこにqueryに関係するドメイン知識が自動で入る
import axios from "axios"
const apiKey = "sk-XXX(OpenAI API Key)"
async function injectEmbeddings() {
const url = "http://oai.langcore.org/v1/chat/completions"
const headers = {
Authorization: `Bearer ${apiKey}`,
"Content-Type": "application/json",
"LangCore-Embeddings": "on",
"LangCore-Embeddings-Match-Threshold": "0.5",
"LangCore-Embeddings-Match-Count": "2",
}
const data = {
query: "LangCoreって何?",
messages: [
{
role: "user",
content: `
独自データを使って、以下の質問に答えてください
[質問]
{{EMBEDDINGS_QUERY}}
[独自データ]
{{EMBEDDINGS_CONTEXT}}
`,
},
],
groupName: "default_group",
model: "gpt-3.5-turbo",
}
axios
.post(url, data, { headers: headers })
.then((response) => {
const messageContent = response.data.choices[0].message.content
console.log(messageContent)
})
.catch((error) => {
console.error(error)
})
}
injectEmbeddings()
3️⃣ 実際に実行されたリクエストを見てみる
LangCore で実行されたログが保存されているのでみてみると、{{EMBEDDINGS_CONTEXT}}を書いていた場所に関係するテーブル定義のドメイン知識がきちんと入っています。
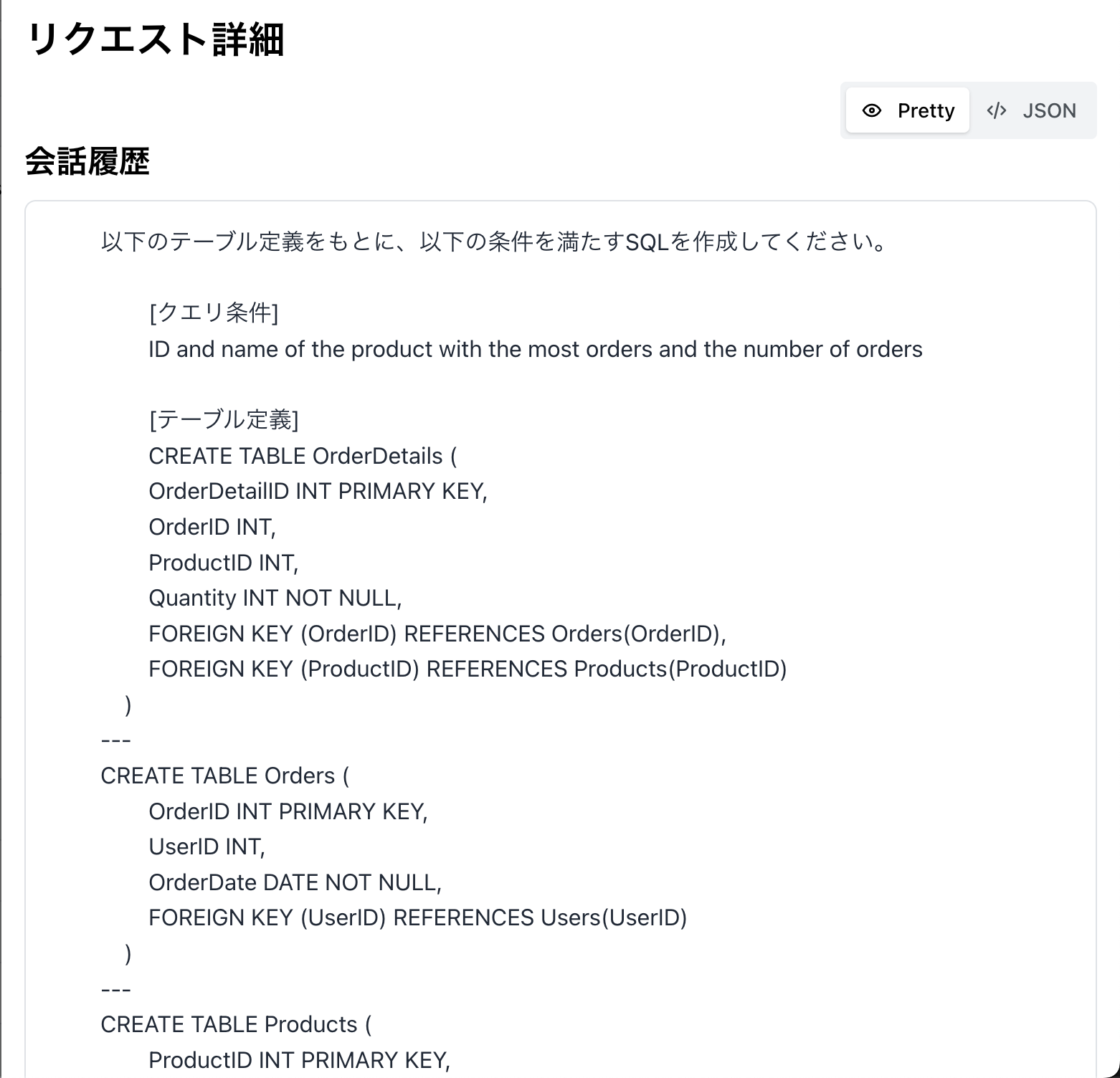
OpenAIのレスポンスを見ると、きちんとテーブル定義を意識してSQLが作成されていました。

まとめ
Embeddingsを使ってドメイン知識をChatGPTが扱えるようになると、ユースケースがグッと広がります。
Githubレポジトリのコードを理解するChatbotや、マニュアルをベースとしたQ&Aシステムなども作れます。
皆さんも良きChatGPTライフを!