はじめに
AIスタートアップでWEBアプリ開発をやりながら、pythonとAIを勉強中です。
画像認識でやりたいことがあり、まずは開発環境の構築とアルゴリズムを使ってみるところまでを実践しました。
今回やりたいこと
- YOLOv3を使う
- 無料でGPUを使う
YOLOとは
物体検出アルゴリズムのうちの1つです。(物体検出は他にFaster R-CNNやSSDなどのアルゴリズムがあります。)
YOLOの特徴は、速くて高精度なことで、現在v3が最新バージョンです。
今回ニューラルネットフレームワークはDarknetを使ます。(フレームワークは他に、TensorflowやChainer、Caffeなどがあります。)
ちなみに、YOLOはYou only look onceの略で、You only live once(人生一度きり)をもじっているそうです。
YOLOで物体検出する
Darknetのインストール
git clone https://github.com/pjreddie/darknet
cd darknet
設定
Makefileで下記をはじめとする設定を変更できます。
GPU=0
CUDNN=0
OPENCV=0
OPENMP=0
DEBUG=0
実行
設定を変更したら、実行します。
make
weightsのダウンロード
今回は学習済みモデルを使用するので、ダウンロードします。
v2: https://pjreddie.com/media/files/yolov2.weights
v3: https://pjreddie.com/media/files/yolov3.weights
wget https://pjreddie.com/media/files/yolov3.weights
物体検出
それでは物体検出してみます。
v2の場合
./darknet detect cfg/yolov2.cfg yolo.weights ./data/dog.jpg

./data/dog.jpg: Predicted in 8.501023 seconds.
dog: 82%
truck: 64%
bicycle: 85%
v3の場合
./darknet detect cfg/yolov3.cfg yolov3.weights ./data/dog.jpg

./data/dog.jpg: Predicted in 19.580538 seconds.
bicycle: 99%
truck: 92%
dog: 100%
v2とv3は今回2倍以上時間はかかったけど、確実に精度が上がっていることがわかりました。
| 物体検出 | YOLO v2 | YOLO v3 |
|---|---|---|
| 自転車 | 82% | 99% |
| トラック | 64% | 92% |
| 犬 | 85% | 100% |
| 時間 | 8.5秒 | 19.6秒 |
無料GPU環境の構築
YOLOを使うことができたので、早速学習させたいのですが、大量データを学習させる時はGPUを使いたいと思いました。
調べたところ、無料で簡単にGPUが使えるGoogle Colaboratory(グーグル・コラボレイトリー)が最強のようです。
Google Colaboratoryは、クラウドのJupyterノートブック環境です。
ここから使えます。
https://colab.research.google.com/notebooks/welcome.ipynb
GPU有効化
ColaboratoryでGPUを使う場合、タブの
「ランタイム」→「ランタイプのタイプを変更」→「ハードウェア アクセラレータ」→「GPU」
で保存します。

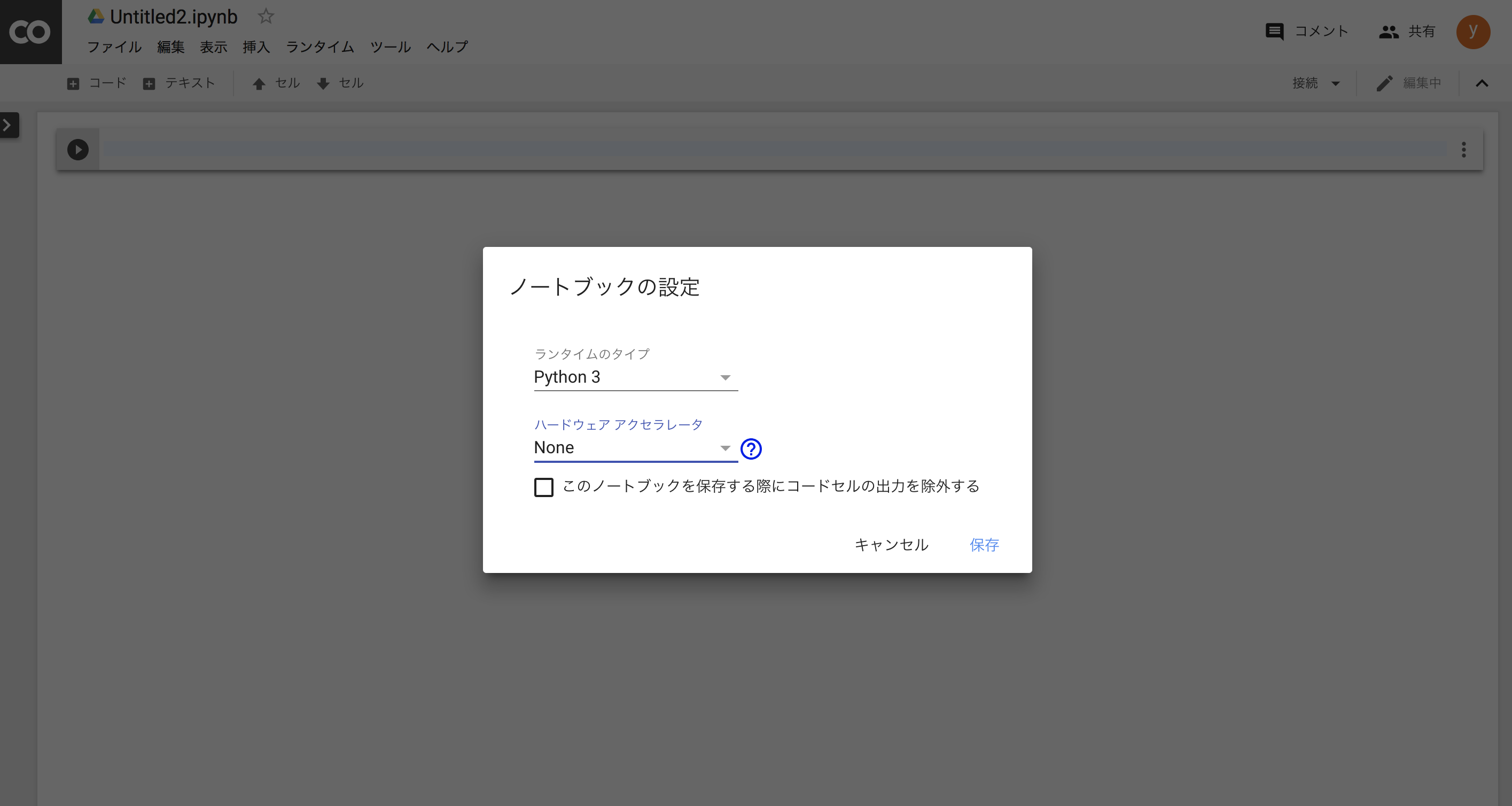
以上でGPU環境が整いました。なんて簡単!
注意
ただし、Google Colaboratoryでは、下記の条件でインスタンスが全てリセットになってしまうので注意が必要です。
- 12時間ルール:新しいインスタンスを起動してから12時間経過
- 90分ルール:ノートブックのセッションが切れてから90分経過
対策はこちらの記事にも書かれていました。
https://qiita.com/enmaru/items/2770df602dd7778d4ce6
環境が整ったので、次回は実際にYOLOを使って学習させてみます!