この記事は SB-AI Advent Calendar 2019の25日目の記事です。
この記事では、FaceboxesというDeep LearningベースのFace Detectionを利用して、カメラに映った人にサンタの帽子を被せるアプリケーションを作成します。
前半でアドベントカレンダーを書くきっかけになったSB-AI部について紹介し、後半でアプリケーションについて書きます。
ソフトバンク株式会社の社内部活SB-AI部
SB-AI部とそのミッション
著者の@yumatsuokaは今年(2019年度)の新卒エンジニアで、現在ソフトバンク株式会社公認のクラブ活動であるSB-AI部を運営しています。この部活は、__IoTやロボティクスを含むAI技術の学習・利用コミュニティとしてソフトバンク株式会社を横断して人々をつなげる__ことをミッションにしています。
つなげたい人たち:AIエンジニア-AIエンジニア
(新卒で働いてみた印象だと)
ソフトバンク株式会社は大きな組織となっていて、様々なしがらみの中で、
部署は全然異なるけれど、同じようなことをやっているエンジニアがたくさんいます。
AI技術が成熟してなく、PoCでプロジェクトを作っては潰すこの時代では、このエンジニアが技術や(特に失敗談などの)ノウハウを共有できれば、さらにスピード感を持って、より良いプロダクトを作ることができると思います。
つなげたい人たち:AIエンジニア-非AIエンジニア
__AI技術を習得したい場合、アカデミックな知識背景を要する場合があり、学習を始める際にはとっつき辛さががあります。__少しでもこの溝を埋めるために、現役のAIエンジニアのノウハウを共有したいと思っています。
つなげたい人たち:AIエンジニア-非エンジニア
現場の人が自分の作業を自動化したい場合、対象となる作業や問題点に一番詳しいのは現場の人です。__AI技術で何ができるのか?__を現場の人が知っている場合は、ニーズとソリューションのギャップが小さくなり、結果としてより良いサービスを作れます。
部のアウトプット
以上より、社内部活SB-AI部はAI技術を軸に社内を横につなげることをミッションとして活動しています。アウトプットの方法は、 社内AI技術活用事例LT会や、(最先端の知識を持つ)インターン生と社内エンジニアをつなげるMeet upの開催、 Tech Newsや知識の共有 を行っています。
Advent Calendar?
このアドベントカレンダーは、来年度入社予定の内定者がSB-AI部でやろう!と提案してくれたことにより実現しました。__年齢や入社の年度に関わらず、主体的に動く人が認められるソフトバンクのカラーが出て面白い__と思った企画です。企画ありがとうございました!
Face Detectionでサンタ帽をかぶるプログラムの実装
背景
SB-AI部のアドベントカレンダーを開いた時、初のadvent calendar参加、過去もほとんどブログを書いたことがありませんでした。事前に記事の温度感を知るために、最終日の25日を埋めることを決めました(チキンでごめんなさい)。
大学から大学院、現在の業務まで画像認識ベースのプロジェクトに関わってきたので、画像認識で何か面白いこと...クリスマス...と考えて、__カメラから顔を認識して、その顔(あたま)に帽子をつけるプログラム__を書こうと思いました。
プログラムの方針
デバイスのカメラから画像を取得し、その画像中に映る人に対してその頭にサンタ帽子を被せてその映像を出力処理を行うために、以下の方針を考えました。

- デバイスから画像を取得する
- 画像中の顔領域を認識する
- 顔領域に合わせて帽子画像をリサイズ
- 顔領域のすぐ上に帽子画像を貼り付ける(代入する)
帽子画像はいらすとやより取得しました。

帽子画像: https://www.irasutoya.com/2018/02/blog-post_728.html
それでは、それぞれの処理に分けて実装したコードを説明します。
デバイスから画像を取得する
OpenCVを利用するととても簡単。
import cv2
def main(args, config):
print("# Startng recording with a camera")
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
#################
# カメラから取得した画像frameを使って処理を行う
#################
# finish detection when you type "q" key
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# finish the detection
cv2.destroyWindow("frame")
cap.release()
cv2.destroyAllWindows()
画像中の顔領域を認識する
顔領域を抽出するために、今回は古典的な画像処理ベースの手法と、最近のディープラーニングの手法を比較しました。
OpenCVを使った(古典的な画像処理ベースの)顔領域の認識の実装例:https://docs.opencv.org/3.4/db/d28/tutorial_cascade_classifier.html
__CPUで実行することを前提とした__ディープラーニングの顔領域抽出手法は、2017年に出たFaceboxesという手法が現在のベースラインの手法となっているようなので使用しました。
実装コードのデモを見ると、細かく正確に顔領域を抽出できている様子です。良さそう。
(赤く矩形で囲われている領域が顔、青の数字が推論結果への信頼度)。

今回のこの記事ではFaceboxesの顔領域抽出の理論については触れず、純粋にエンジニアリングとしてこの手法を使用します。
顔認識手法1:OpenCVで顔領域抽出
まずは画像認識分野でデフォルトとなっているOpenCVで顔領域を抽出してみます。画像中から全ての顔領域候補を確保し、それぞれの候補ごとに顔領域を矩形で囲ったり、サンタ帽子を被せる処理を行います。
def detect_with_cascade(frame, cascade, mask_img, args):
t1 = time.time()
# get face points. return [[x, y, wigth, length], ...]
facerect = cascade.detectMultiScale(
frame, scaleFactor=1.2, minNeighbors=2, minSize=(10, 10)
)
# put rectagles along with the detected faces
if len(facerect) > 0:
for rect in facerect:
x, y, w, h = rect
left_up, right_bottom = (x, y), (x + w, y + h)
if args.rect:
cv2.rectangle(
frame, left_up, right_bottom, config.oc_color, thickness=2
)
if args.santa:
frame = combine_img(frame, mask_img, left_up, right_bottom)
t2 = time.time()
print("#### Elapsed time for detecting one frame:{}".format(t2 - t1))
# show frame
cv2.imshow("frame", frame)
return left_up, right_bottom
顔認識手法2:Deep Learningの手法(Faceboxes)で顔領域抽出
以下のFaceboxesの実装コードを利用しました。
yxlijun/Faceboxes.pytorch: https://github.com/yxlijun/Faceboxes.pytorch
以下のコードを書いて実装コードを呼び出しました。
def detect_with_faceboxes(net, frame, thresh, device, mask_img, args):
frame = np.array(frame, copy=True)
img_to_net = cv2.cvtColor(frame.copy(), cv2.COLOR_BGR2RGB)
height, width, _ = img_to_net.shape
x = FaceBoxesBasicTransform(img_to_net)
x = torch.from_numpy(x).unsqueeze(0).to(device)
t1 = time.time()
with torch.no_grad():
y = net(x)
detections = y.data
scale = torch.Tensor([width, height, width, height])
for i in range(detections.size(1)):
for j in range(detections.size(2)):
if detections[0, i, j, 0] >= thresh:
pt = (detections[0, i, j, 1:] * scale).cpu().numpy().astype(int)
left_up, right_bottom = (pt[0], pt[1]), (pt[2], pt[3])
if args.rect:
cv2.rectangle(frame, left_up, right_bottom, (0, 0, 255), 2)
if args.santa:
frame = combine_img(frame, mask_img, left_up, right_bottom)
t2 = time.time()
print("#### Elapsed time for detecting one frame:{}".format(t2 - t1))
cv2.imshow("frame", frame)
return left_up, right_bottom
顔領域に合わせて帽子画像をリサイズ
まず以下のコードで(PNGの透過情報を保ったまま)サンタ帽子画像をOpenCVで読み込み、
import cv2
# 2つ目の引数に-1を指定することで、PNGの透過情報をRGBと一緒に読み込める
mask_img = cv2.imread(config.mask_img_path, -1)
その後アスペクト比を維持したまま、
画像の幅を顔領域と同じサイズにリサイズします。
def scale_to_width(img, width):
scale = width / img.shape[1]
return cv2.resize(img, dsize=None, fx=scale, fy=scale)
顔領域のすぐ上に帽子画像を貼り付ける
カメラの画像と、サンタ帽子画像はOpenCVで読み込んだので、Numpy行列となっています。そのため、ベースとなるカメラ画像に対して、帽子を貼り付ける位置を特定したあとは、ベース画像を帽子画像の行列で代入して上書きします。
代入時にベース画像の行列からサンタ帽子領域が飛び出る可能性があるため、条件分岐で事前に代入範囲を制限しています。また、PNGの透過情報を利用して、上書きする領域にバイアスをかけています。
def combine_img(frame, mask_img, left_up, right_bottom):
face_width = right_bottom[0] - left_up[0]
mask_img = scale_to_width(mask_img, face_width)
mheight, mwidth = mask_img.shape[:2]
mask = mask_img[:, :, 3] # これでアルファチャンネルのみの行列が抽出。
mask = cv2.cvtColor(mask, cv2.COLOR_GRAY2BGR)
mask = mask / 255.0
mask_img = mask_img[:, :, :3]
frame_float = frame.astype(np.float64)
# 画像を貼り付けるときにベース画像からマスク画像が飛び出ないように条件分け
if left_up[1] - mheight <= 0:
mheight = left_up[1]
frame_float[
left_up[1] - mheight : left_up[1], left_up[0] : right_bottom[0]
] *= (1.0 - mask[-mheight:, :])
frame_float[
left_up[1] - mheight : left_up[1], left_up[0] : right_bottom[0]
] += (mask_img[-mheight:, :] * mask[-mheight:, :])
else:
mheight = mheight
frame_float[
left_up[1] - mheight : left_up[1], left_up[0] : right_bottom[0]
] *= (1.0 - mask[-mheight:, :])
frame_float[
left_up[1] - mheight : left_up[1], left_up[0] : right_bottom[0]
] += (mask_img[-mheight:, :] * mask[-mheight:, :])
frame_float = frame_float.astype(np.uint8)
return frame_float
コードの実行
-
コードのクローン
git clone https://github.com/yumatsuoka/Faceboxes.pytorch.git -
クローンしたコードのディレクトリへ移動
cd Faceboxes.pytorch/ -
実行の依存ライブラリをインストールします
pip install pytorch torchvision opencv numpy easydict -
学習済のFaceboxesの重みをREADMEに書いてあるURLからダウンロードして
weights/ディレクトリに配置
※重みがアップロードされているBaiduクラウドは、利用に少しクセがあるので気をつけてください。 -
コードの実行
python demo_santa.py --face_detector fb --rect --santa
$ python demo_santa.py -h [17:37:05]
usage: demo_santa.py [-h] [--face_detector {fb,opencv}] [--rect] [--santa]
optional arguments:
-h, --help show this help message and exit
--face_detector {fb,opencv}, -fd {fb,opencv}
choice face detector
--rect add it, surround your face
--santa add it, put santa hat on your head
実行結果
ネット上の人物の画像と一緒にサンタ帽子をかぶっています。
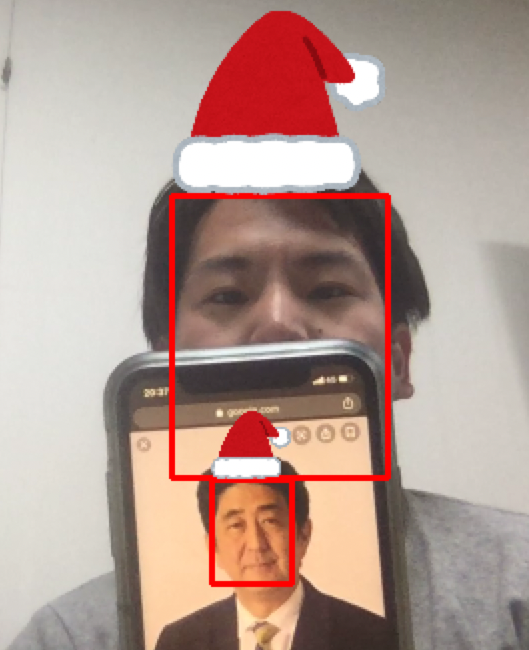
顔領域の認識に関して、
- 一般的に使われているOpenCVのHaarlike特徴量を用いたcascade_detector
- ディープラーニングベースのFaceboxes
の両方を検証しました。
詳しい結果はここで載せませんが、Faceboxesの方が優れている印象がありました。
FacdboxesはOpenCVでは認識が難しかった横顔や、半分ほど障害物で隠れている顔も認識していました。
しかしながら、ディープラーニングの問題点である処理速度に関しては、やはりOpenCVの方が優れていました。
以下のスペックのMacbookでは、
MacBook Pro (13-inch, 2017, Four Thunderbolt 3 Ports)
プロセッサ:3.1 GHz デュアルコアIntel Core i5
メモリ:16 GB 2133 MHz LPDDR3
それぞれの手法の処理速度は、
OpenCVが1フレームあたり30〜40ms
Faceboxesが1フレームあたり60〜70ms
となりました。
元々論文でも、 Faceboxesは、CPUでも動くディープラーニングベースの顔認識手法であることをアピール していましたが、今回の結果からもCPUで十分に使える処理速度だと考えられます。
Future work
顔認証を組み込みたいです。
特定の人物(例えばお父さん)のみサンタ、残りはトナカイといったアウトプット方法の応用は可能です。来年は現在のコードに顔認証を組み込んで、さらに面白いFace detectionアプリケーションを作りたいです。
まとめ・所感
ソフトバンク株式会社の社内部活のSB-AI部の紹介と、そのイベントの1つadvent calendarで、顔を認識してサンタ帽を被せるというアプリケーションを作り、記事にまとめました。
検証の中で、FaceboxesはラップトップPCのCPUでも十分に動く手法だとわかりました。
記事を書くまでに思った以上に工数を必要としたので、来年こそは早めに取り掛かり、担当の日付までに公開したいと思います(遅くなってごめんなさい)。
今回のadvent calendarを見て、SB-AI部に興味を持った社員は一緒に活動していきましょう。
社外の方も一緒に、何かしら面白いイベントを開けると思いますので、連絡をいただけると幸いです。
それでは...良いお年をお迎えください。
Reference
- Faceboxesの論文(FaceBoxes: A CPU Real-time Face Detector with High Accuracy):https://arxiv.org/abs/1708.05234
- 今回実装したコード:https://github.com/yumatsuoka/Faceboxes.pytorch
- 利用したFaceboxesの実装コード:https://github.com/yxlijun/Faceboxes.pytorch