本記事の背景・目的・対象者
サクッとDockerでPySparkを試してみる にてPySparkを用いたETLスクリプトで解析しやすいデータを生成できるようになりました。
こうなると実際にその解析しやすくなったデータを解析したくなりますね。昨今データ解析でよく使われるのがjupyter notebookというツールです。
前回同様本記事では jupyter notebook の詳しい説明はしません。
従って、本記事の対象者はこれからデータ基盤エンジニアを目指す人や目指すかどうかはおいといてデータ基盤エンジニアの仕事に興味がある人やとにかくjupyter notebookをいじってみたい!という人を対象としています。
jupyter notebookとは
jupyter notebookは解析クエリや解析スクリプトのエディタ、解析結果のビジュアライズがセットになったWebベースのGUIを提供してくれます。
従ってどこかで jupyter notebookサーバーが動いていてそこへブラウザでアクセスして操作するという使用方法になります。jupyter notebookはあくまでGUIの提供をしているだけで実際のクエリエンジンや解析スクリプト言語の実行環境は提供しておらず jupyter notebook がそれらを使う形となります。
jupyter bookで使用できるクエリエンジンやスクリプト言語は多種多様ですが今回はPySparkを使います。
準備
jupyter notebookの公式がdockerイメージを用意してくれているのでそれをそのまま使わせてもらいます。こちらにjupyter notebookを簡単に使えるようにしたリポジトリを用意しておきました。
$ git clone git@github.com:yuma300/docker-pyspark-try.git
$ cd docker-pyspark-try
$ docker-compose up -d jupyter
これで準備完了です。あとは試してみるだけです
実行
ブラウザで http://localhost:8890 にアクセスします。すると以下の画面が表示されます
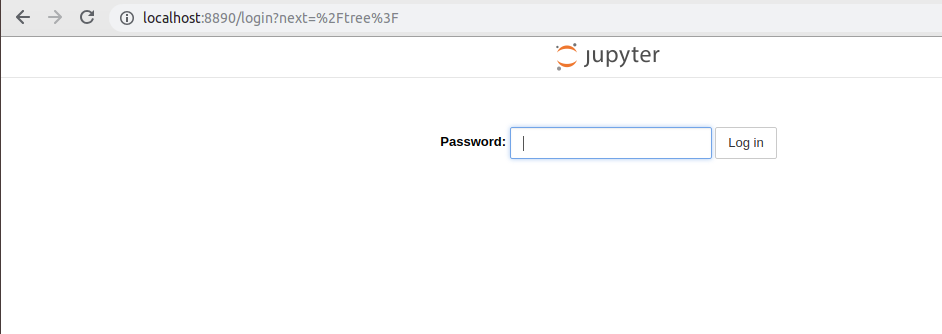
Passwordに 12345678 と入力して Loginボタンを押下します。
ログインできると以下の画面が表示されるので New ボタンを押下します。
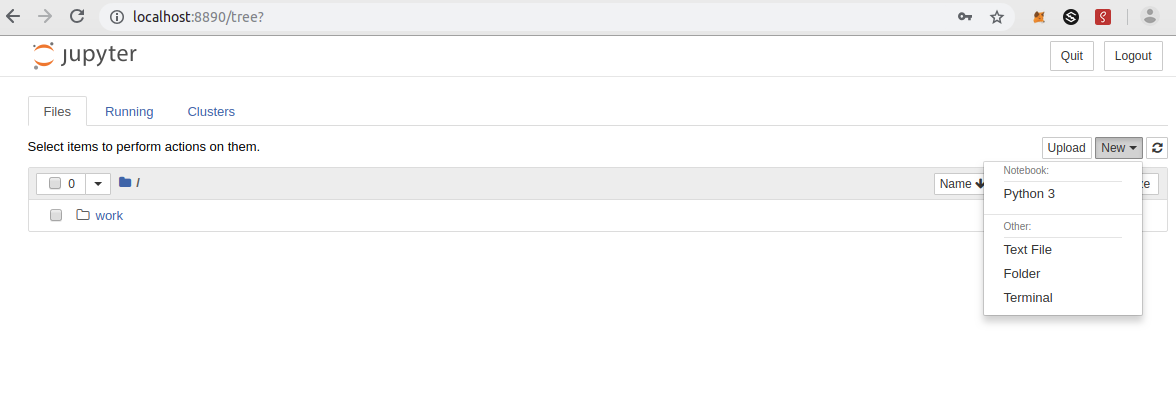
以下の画面のようにエディタが表示されます。
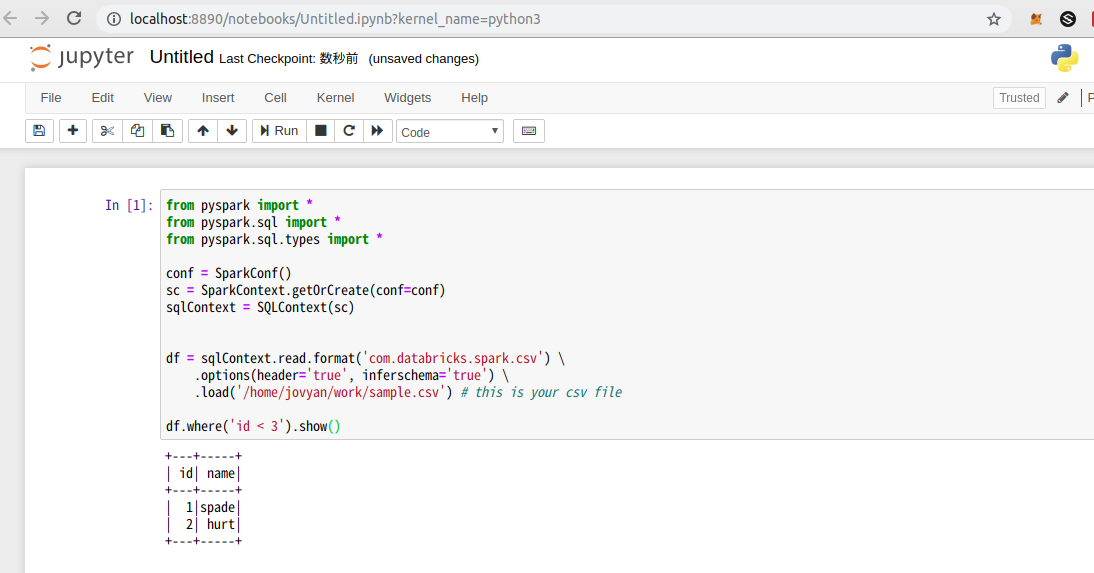
フォームに以下のスクリプトを入力して Run ボタンを押下すると結果が出力されます。
from pyspark import *
from pyspark.sql import *
from pyspark.sql.types import *
conf = SparkConf()
sc = SparkContext.getOrCreate(conf=conf)
sqlContext = SQLContext(sc)
df = sqlContext.read.format('com.databricks.spark.csv') \
.options(header='true', inferschema='true') \
.load('/home/jovyan/work/sample.csv')
df.where('id < 3').show()
.load('/home/jovyan/work/sample.csv') この部分でcsvを読み込んでいます
df.where('id < 3').show() の部分で実際に解析処理を行ってます(解析というほど大層な事はしてないですが)。
採用目的
現在私が所属するbitbankではデータ基盤エンジニアの採用を行っております。興味を持たれた方は是非下からご応募よろしくお願いします。