iOSDC2018に以下のタイトルで登壇しました。
iOSと(深層)強化学習
スライドはこちらです。
(Speaker Deck) iOSと(深層)強化学習
動画はこちら。
https://youtu.be/7iVXEn99-aw
内容は4章仕立てで、強化学習の概要の解説から、Swiftによる深層強化学習の実装までお話ししました。
以下は発表原稿の全文になります。スライドを前提にした解説の箇所があるのはご容赦ください。
プロローグ
ご紹介を有難うございました、我妻と申します。
本日は、iOSと深層強化学習というタイトルで発表します。
それではまず自己紹介から始めたいと思います。
私の名前は我妻(あづま)と申します。
ネット上ではこのチンアナゴのアイコンと、@yuky_azのアカウントで活動しています。
今年の2月にSAI-Lab株式会社という会社を設立しました。
ヒトとAIの共生がミッションで、AI関係の教育と研究活動に従事しています。
オンライン教育プラットフォームUdemyでAI関連の講座を複数展開しているのですが、受講生の数が2万近くになりました。
あと、最近よく言われることですが、AIの事ばかり考えているせいか「話し方がAIに似てきたね」と言われたりします。
ところで、皆様にご報告があります。
昨年も今年と同様に、iOSDC2017に登壇する機会をいただきました。
その際はAI関連の発表をしたのですが、発表を見た方から様々な縁がつながって、本の出版につながりました。
「はじめてのディープラーニング」というディープラーニング初心者向けの本ですが、SBクリエイティブより8/28に発売したばかりです。
320ページに及ぶ大作ですが、ディープラーニングの原理をフレームワークを使わずに1から解説しています。
このように、iOSDCが様々な機会を生む場であることを、改めて実感します。
それではここで、本日の発表の流れを説明したいと思います。
全部で4つのセクションでお送りします。
Section1、強化学習とは?では強化学習全般の解説を行います。
Section2、Swiftで強化学習では、実際にSwiftで強化学習を実装します。扱う問題は、強化学習の古典的な問題であるCart Pole問題です。
Section3、Accelerate Frameworkによるニューラルネットワークでは、深層強化学習に用いるニューラルネットワークの構築方法を解説します。
そして、Section4、Swiftで深層強化学習では、iOSにおける深層強化学習のデモを行います。
さて、今回の発表にはテーマがあります。
それは、「iOSに深層強化学習は実装できるのか?」になります。
深層強化学習はAlphaGoが囲碁チャンピョンを破ったことやゲームの自動攻略などで有名ですが、iOSでそれは実装可能なのか、そして実装したらどのように振る舞うのか、検証するのが今回の発表の目的になります。
それでは、Section 1から始めていきましょう。

Section 1では、強化学習の概要をまず解説します。
そして、強化学習に必要な各概念と、強化学習の代表的なアルゴリズムであるQ学習を解説します。
また、強化学習とディープラーニングを組み合わせた深層強化学習についても概要を解説します。
まず、人工知能、すなわちAIと機械学習、強化学習について概念を整理したいと思います。
この中で一番広い概念は人工知能です。
そして、この人工知能は機械学習を含みます。
強化学習は、この機械学習の一分野です。
この機械学習の中には、近年注目を集めているディープラーニングもあります。
それではまず、強化学習の概要を解説します。
強化学習では、「環境において最も報酬が得られやすい行動」を「エージェント」が学習します。
すなわち、エージェントが行動した結果、環境から報酬が得られると、エージェントはその報酬がより多くゲットできるように行動のルールを改善していくことになります。
ここで、強化学習の応用例をいくつか挙げてみます。
まず、一番有名なのはゲームの攻略かと思います。
AlphaGoのAIは深層強化学習をベースにしていますし、深層強化学習がブロック崩しやスペースインベーダー、ルービックキューブなどのゲームを攻略した例も報告されています。
そして、ロボットの制御にも使われています。二足歩行ロボットの歩行や、産業用ロボットの動作制御などで、強化学習は有効に働きます。
また、データセンターの電力削減に使われた例も報告されています。
気候やサーバーの稼働状況に合わせて、空調を最適化するために、深層強化学習が活用されました。
その他、ビルの地震対策にも深層強化学習が使われた例があります。
このように、強化学習は様々な分野で活用され始めています。
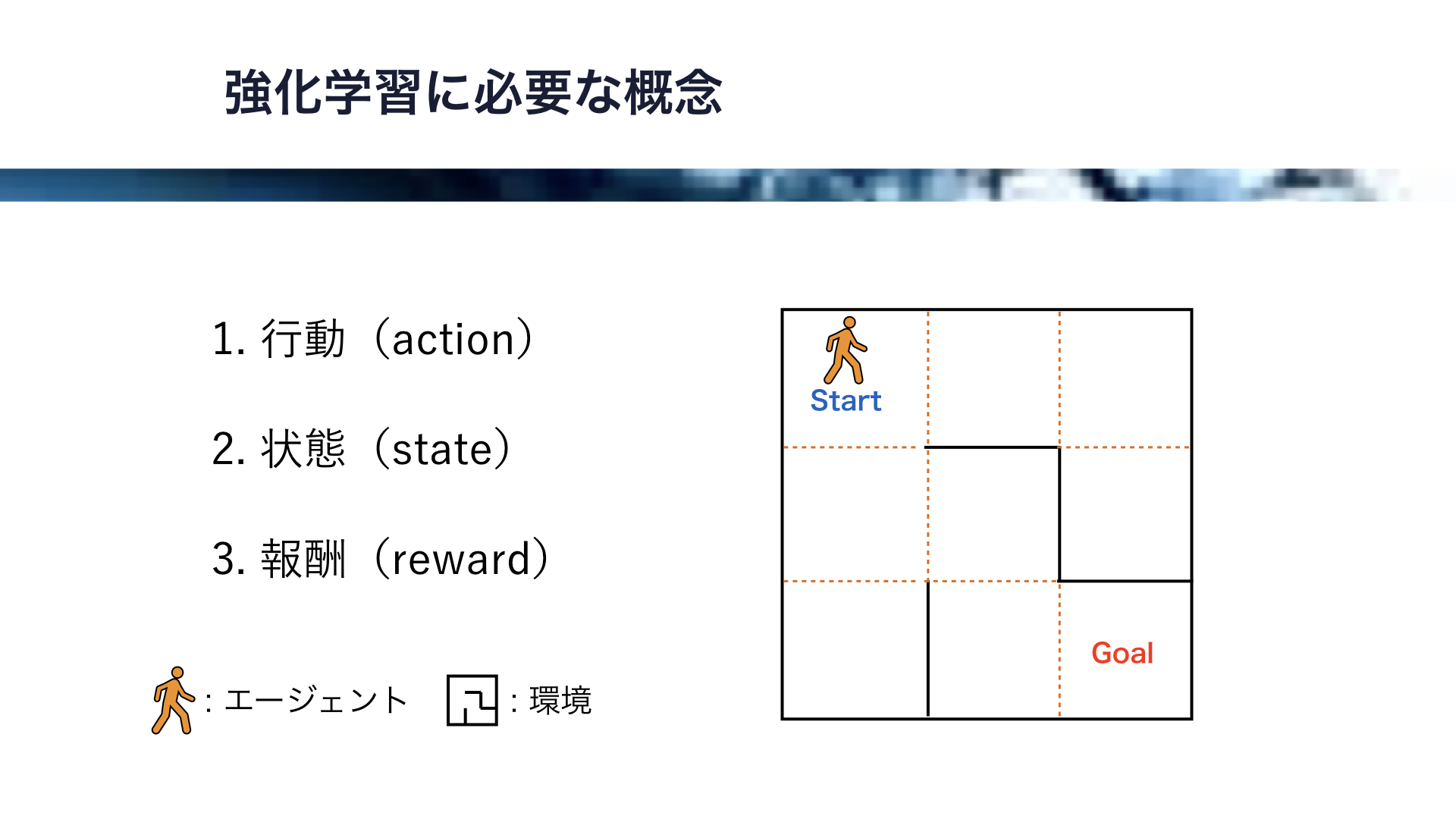
それでは、ここで強化学習に必要な概念を紹介します。
そのために、ここに示すような迷路の問題を考えましょう。
この迷路自体が環境で、この人型のアイコンがエージェントです。
エージェントは隣り合うマス目に移動できますが、壁を抜けることはできません。
この迷路で、エージェントがゴールまで最短でたどり着くために必要な強化学習のアルゴリズムを考えます。
このために必要な概念は、行動(action)と、状態(state)、報酬(reward)の3つになります。
それではまず、行動から解説します。
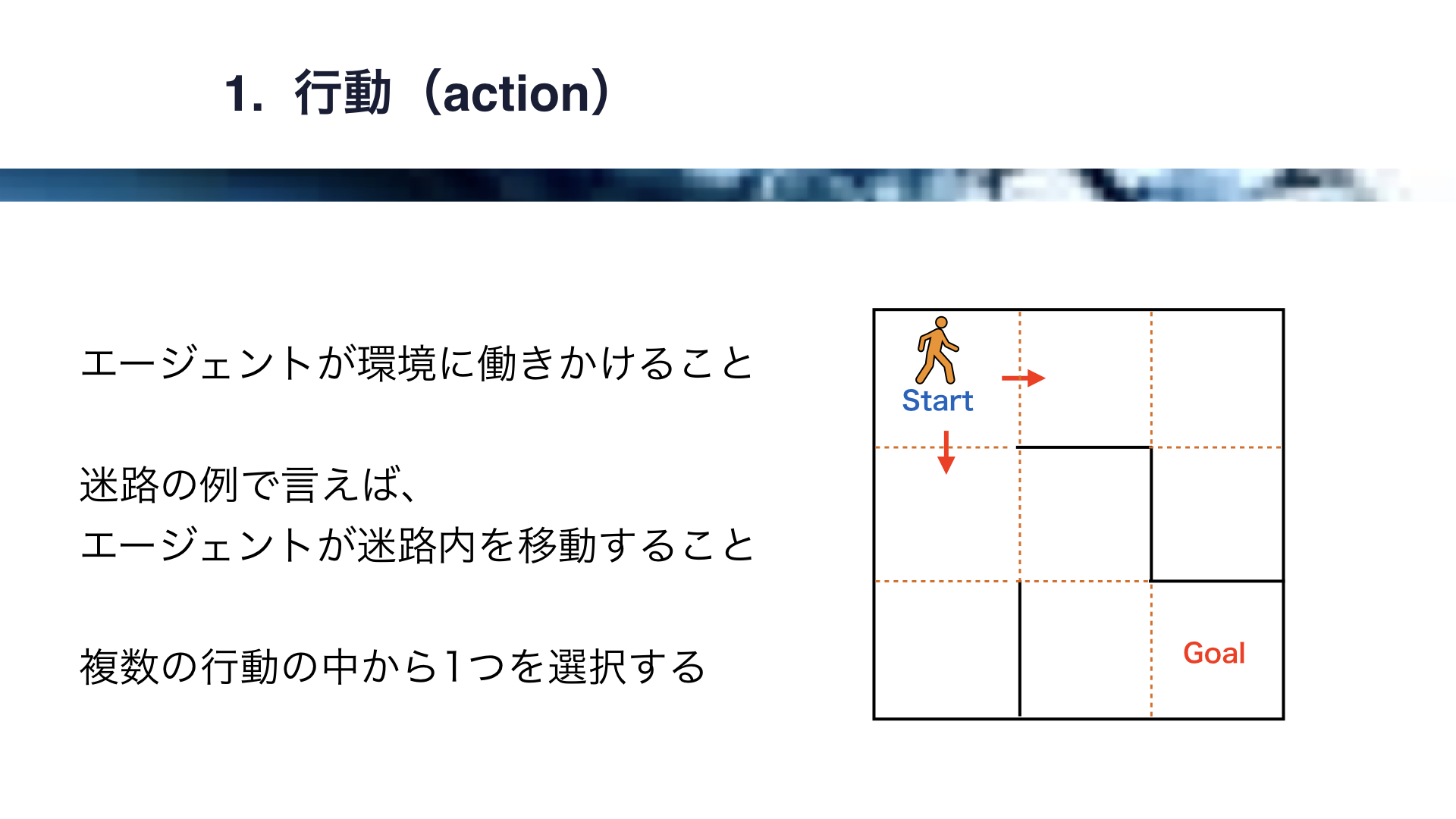
行動とは、エージェントが環境に働きかけることです。
先ほどの迷路の例で言えば、エージェントが迷路内を移動することが行動にあたります。
エージェントが移動する方向には、上下左右が考えられますが、エージェントはこの中から1つの行動を選択することになります。

次に、状態です。
状態とは、エージェントが環境において置かれた状態のことです。
今回の迷路の例で言えば、こちらに示すエージェントの位置、S1からS9が状態になります。
従って、この例では9通りの状態が存在することになります。
このような状態は、行動によって変化します。
エージェントの移動という行動により、エージェントの位置、すなわち状態が変化します。
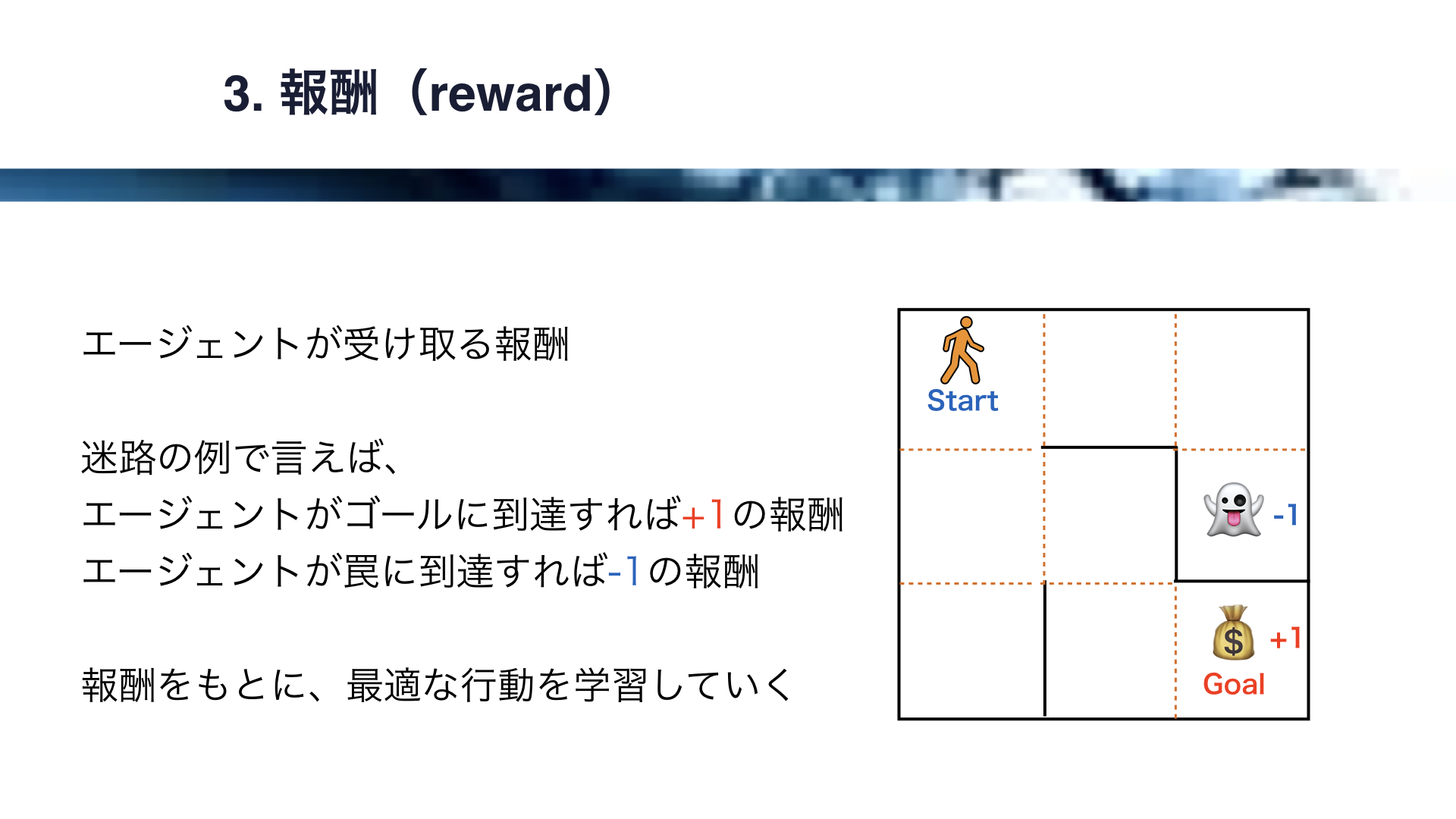
次に、報酬を解説します。
報酬とは、エージェントが受け取る報酬です。
迷路の例で言えば、エージェントがゴールに到達すれば+1の報酬、エージェントが罠に到達すれば-1の報酬、のような報酬の設定を考えることができます。
この報酬をもとに、エージェントは最適な行動を学習していきます。
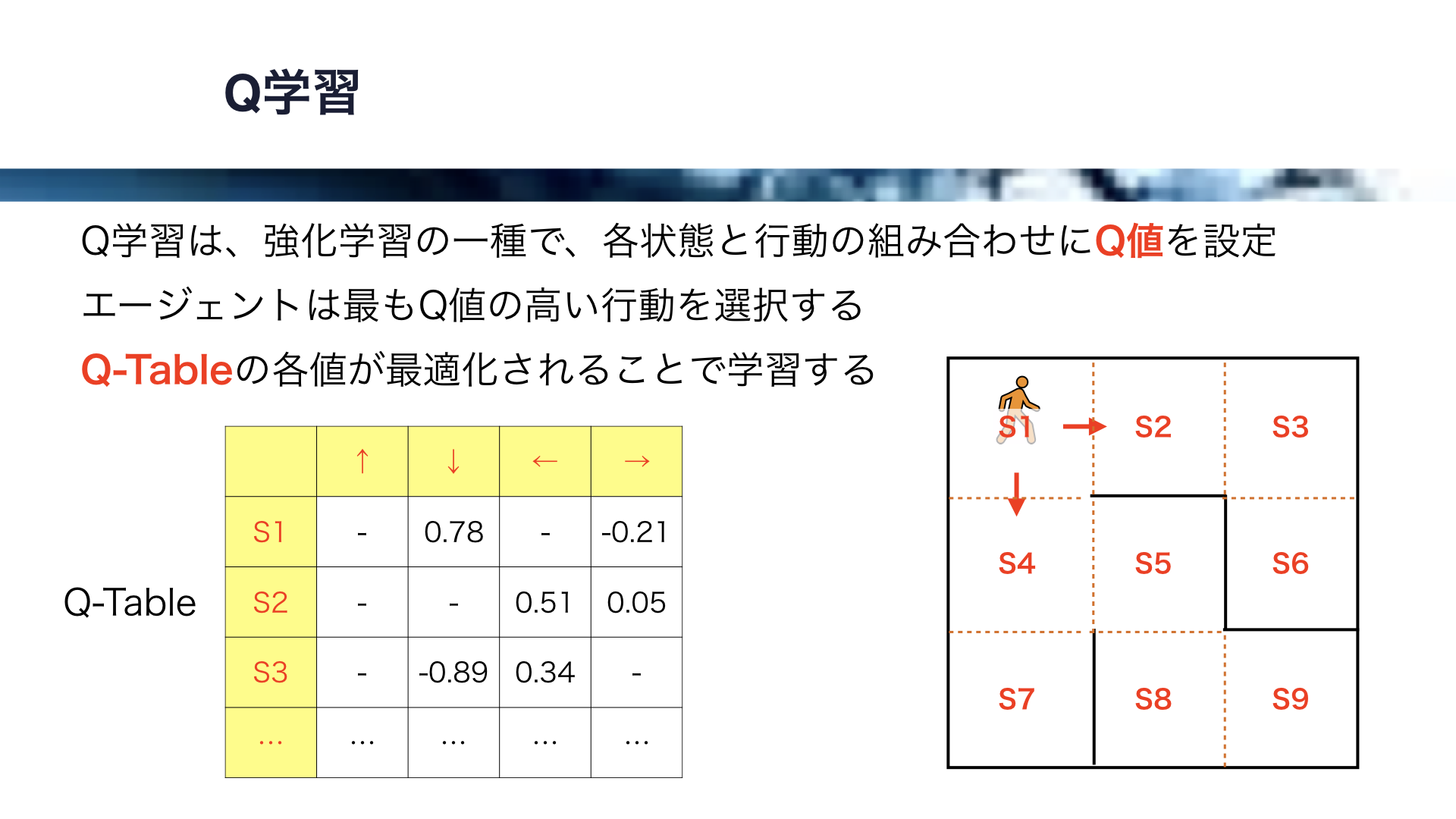
それでは、ここで、Q学習というアルゴリズムを解説します。
Q学習は、強化学習の一種で、各状態と行動の組み合わせにQ値を設定します。
エージェントは最もQ値の高い行動を選択することになります。
Q学習では、Q-Tableというものを設定します。
Q-Tableでは、各状態を行とし、各行動を列とした表です。
例えばエージェントがS1の状態にあるとき、とりうる行動は、下への移動と右への移動の2通りです。
このとき、S1と下、S1と右の組み合わせそれぞれにQ値を設定します。
この場合は下へ移動するQ値が、右に移動するQ値より大きいので、エージェントは下に移動することなります。
同様に、エージェントがS2の状態にあるとき、とりうる行動は、左への移動と右への移動です。
従って、S2と左、S2と右の組み合わせにそれぞれQ値を設定します。
この場合は左へ移動するQ値が、右に移動するQ値より大きいので、エージェントは左に移動することなります。
このようにして全ての状態と行動の組み合わせにQ値を設定しますが、このようなQ-Tableの各値が最適化されることで学習が行われます。
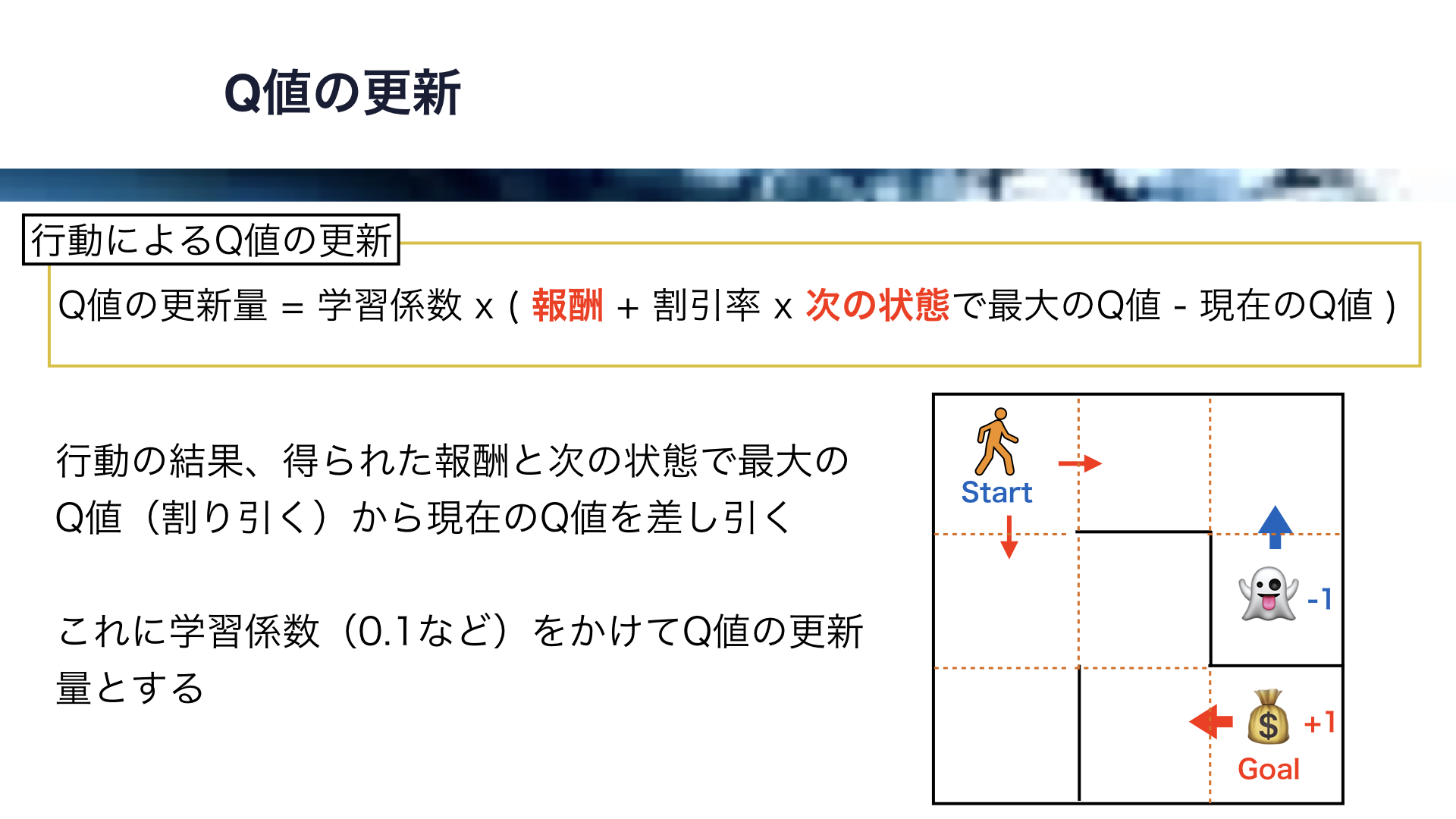
それでは、Q値の更新について解説します。
Q値が更新されることで、学習が進行します。
Q値は、エージェントが行動し、状態が変化する際に更新されます。
迷路ではゴールで正の報酬、罠で負の報酬がもらえますが、これらの報酬が伝播することにより各Q値が変化します。
行動によるQ値の更新式はこちらになります。
まず、行動の結果得られた報酬との次の状態で最大のQ値から、現在のQ値を差し引きます。
報酬は、迷路の例でいうとゴールと罠の箇所でしか得られません。
次の状態で最大のQ値には、割引率という値をかけて価値を差し引きます。
ここの値は、あるべきQ値と現在のQ値のギャップなのですが、これに学習係数と呼ばれる0.1などの小さい数をかけてQ値の更新量とします。
学習係数が小さいので、Q値は少しずつ更新されていくことになります。
以上のように、エージェントが行動することでQ値は更新されていきます。
エージェントはQ値が高い行動を選択するのですが、Q値がうまく更新されるとエージェントは次第に最適な行動をとるようになります。
ところで、以上のようなQ学習にも問題点があります。
扱う状態の数が多いとQ-Tableが巨大になり、学習がうまく進まなくなってしまう問題です。
例えば、こちらのQ-Tableは、マス目が100x100で10000個ある迷路のものです。
この場合、状態を表す行の数は10000になります。
このような巨大なQ-Tableでうまく報酬を伝播させてQ値を最適化するのは困難なので、このあたりがQ学習の限界になります。
この問題に対処するために生まれたのが、深層強化学習です。
深層強化学習は、強化学習に、深層学習、すなわちディープラーニングを取り入れたものです。
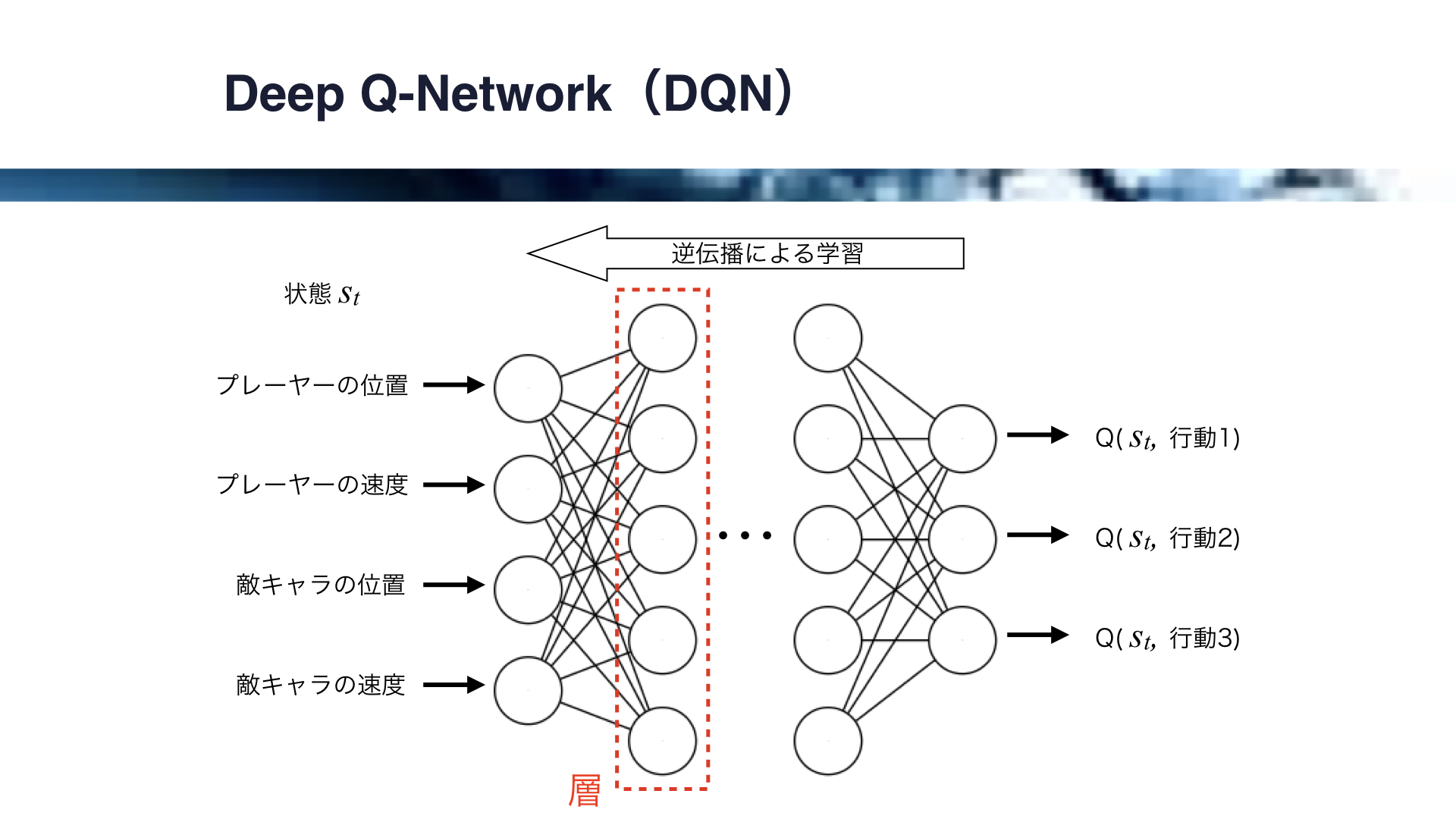
Deep Q-Networkはこのような深層強化学習の一種ですが、Q学習におけるQ-Tableの代わりに、ニューラルネットワークを使用します。
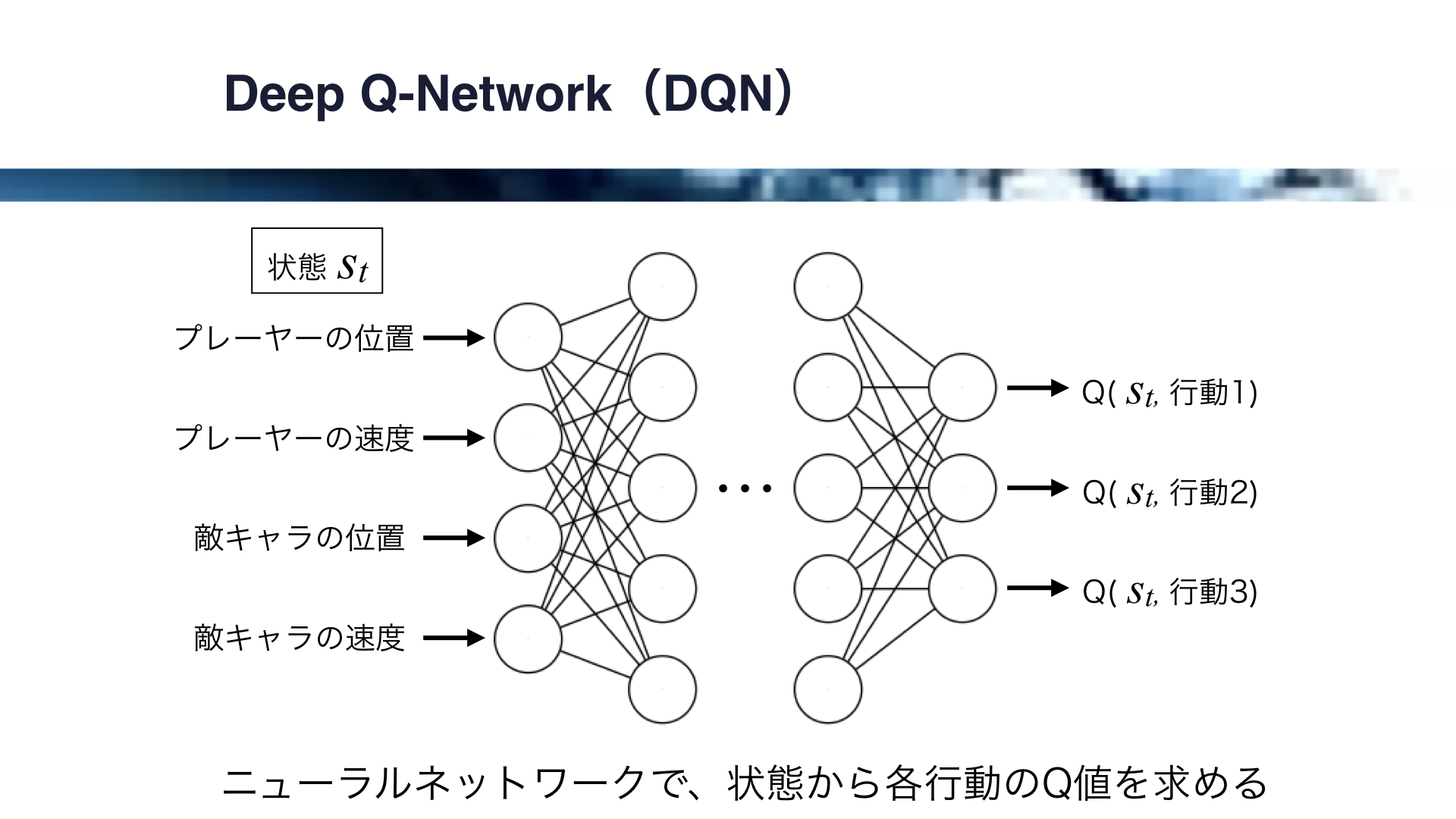
それでは、Deep Q-Networkの例を見ていきましょう。
ここでは、Deep Q-Networkによる、ゲームの自動プレイの例を考えます。
この場合、状態Stはプレイヤーの位置、プレイヤーの速度、敵キャラの位置、敵キャラの速度で決まります。
これらをニューラルネットワークの各入力としますが、各出力は各行動に対応したQ値となります。
すなわち、ニューラルネットワークが状態から各Q値を計算してくれることになります。
なお、Q学習において状態はQ-Tableの行で表されましたが、Deep Q-Networkにおいてはこのように複数の連続した値で状態を表現することができます。
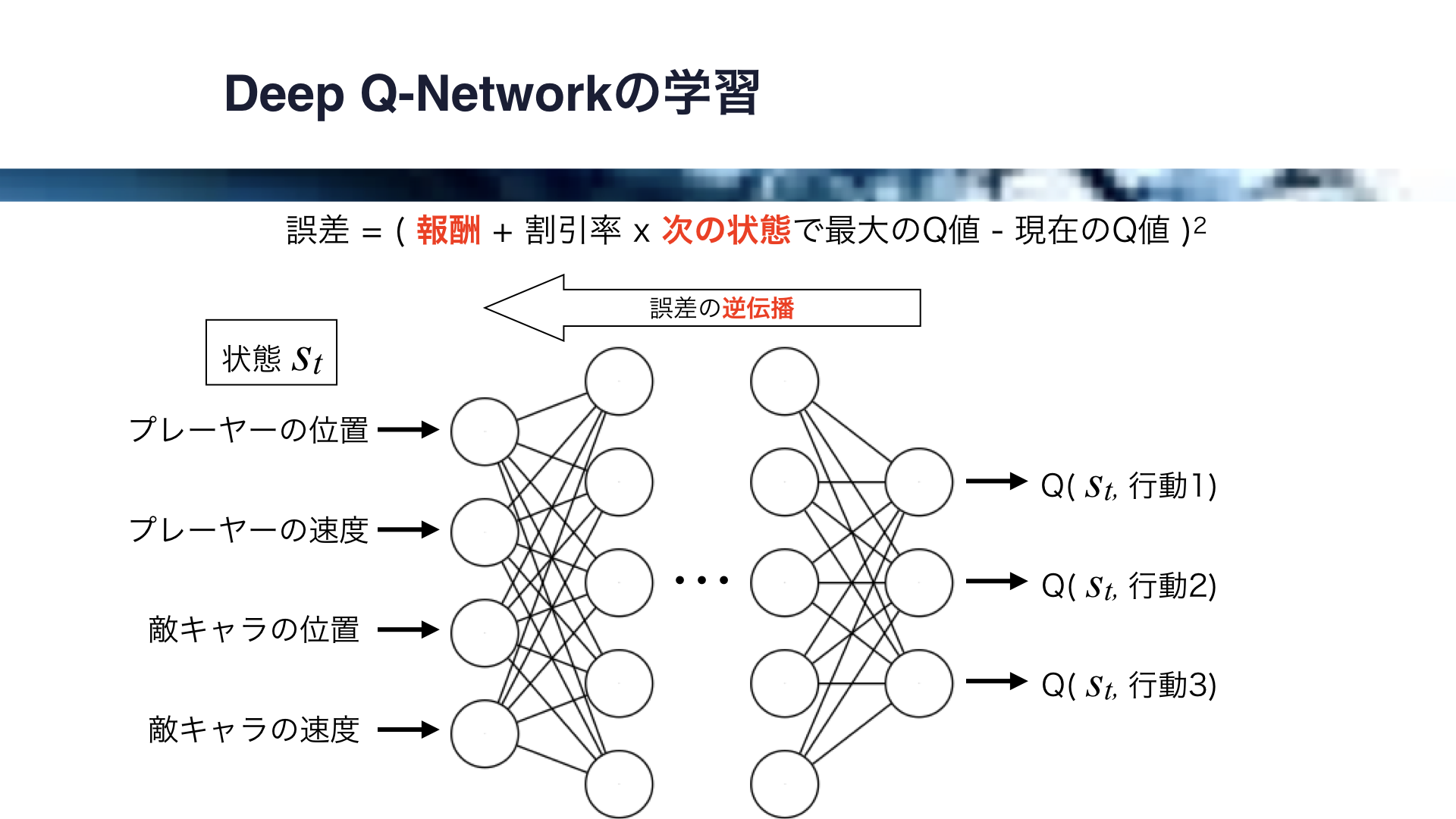
Deep Q-Networkでは、ニューラルネットワークが学習を担います。
Q値から誤差を計算し、その誤差を逆伝播させることによりニューラルネットワークに学習を行わせます。
この際の誤差には、Q値の更新量を求める際に使った式の一部を使います。
報酬に次の状態におけるQ値の最大値を足して、現在のQ値を引いたものは、Q値のあるべき値からのずれでしたね。
これを2乗して誤差とし、逆伝播させて学習が行われます。
以上のように、深層強化学習はディープラーニングと強化学習を組み合わせたものになっています。

それではSection. 2に入ります。
このセクションでは、Swiftで強化学習を実装します。
Cart Poleと呼ばれる問題を扱いますが、このためにQ学習をSwiftで実装し、アプリ上でCart Pole問題をデモします。

Cart Pole問題は、強化学習の古典的な問題です。
ここに示すようにCartの上にPoleが乗っているのですが、Cartを左右に移動させて上に乗ったPoleが倒れないようにします。
ちょっとだけ私の手元でやってみましょう。
(指示棒を使ってCart Poleのデモ)
かなり難しいですね。
これが巨大になったのが秋田の竿燈(かんとう)祭りで、以前に秋田に行った時試したのですが、かなり難しかった記憶があります。
強化学習でこの問題を扱う場合、状態はCartの位置、Cartの速度、Poleの角度、Poleの角速度で決まります。
また、行動はCartを左に動かす、Cartを右に動かすの2通りのみです。
それでは、Swiftで強化学習によりPoleを立てることにトライしてみます。

まずは物理エンジンを使って環境を構築します。
SpriteKitを使って2DのCartとPoleを作成します。
CartとPoleをjointで接続し、重力はPoleのみに適用します。
このコードはこちらのようになります。
SpriteKitを使って、CartとPoleのノードをjointでピン留めしています。
それでは、ここまでのコードを試してみましょう。
(スワイプによるポールの安定化をデモ)
なかなかポールを立てるのは難しいですね。
それでは、ここから強化学習を実装していきます。
今回はQ学習を用います。
そして、CartPole問題はCartの位置と速度がなくても実装できるので、簡単にするためにPoleの角度と角速度のみから状態を決めます。
Poleの角度と角速度は、それぞれ12に分けてデジタル化します。
この結果、状態の数は12 x 12で144通りになります。
こちらにQ-Tableの例を示しますが、状態を表す行の数が144、行動を表す列の数は左に移動と右に移動で2になります。
Q-TableのSwiftによる実装ですが、Q-Tableは2次元配列で表現し、Q-Tableの更新には以前に解説した更新式をそのまま使います。
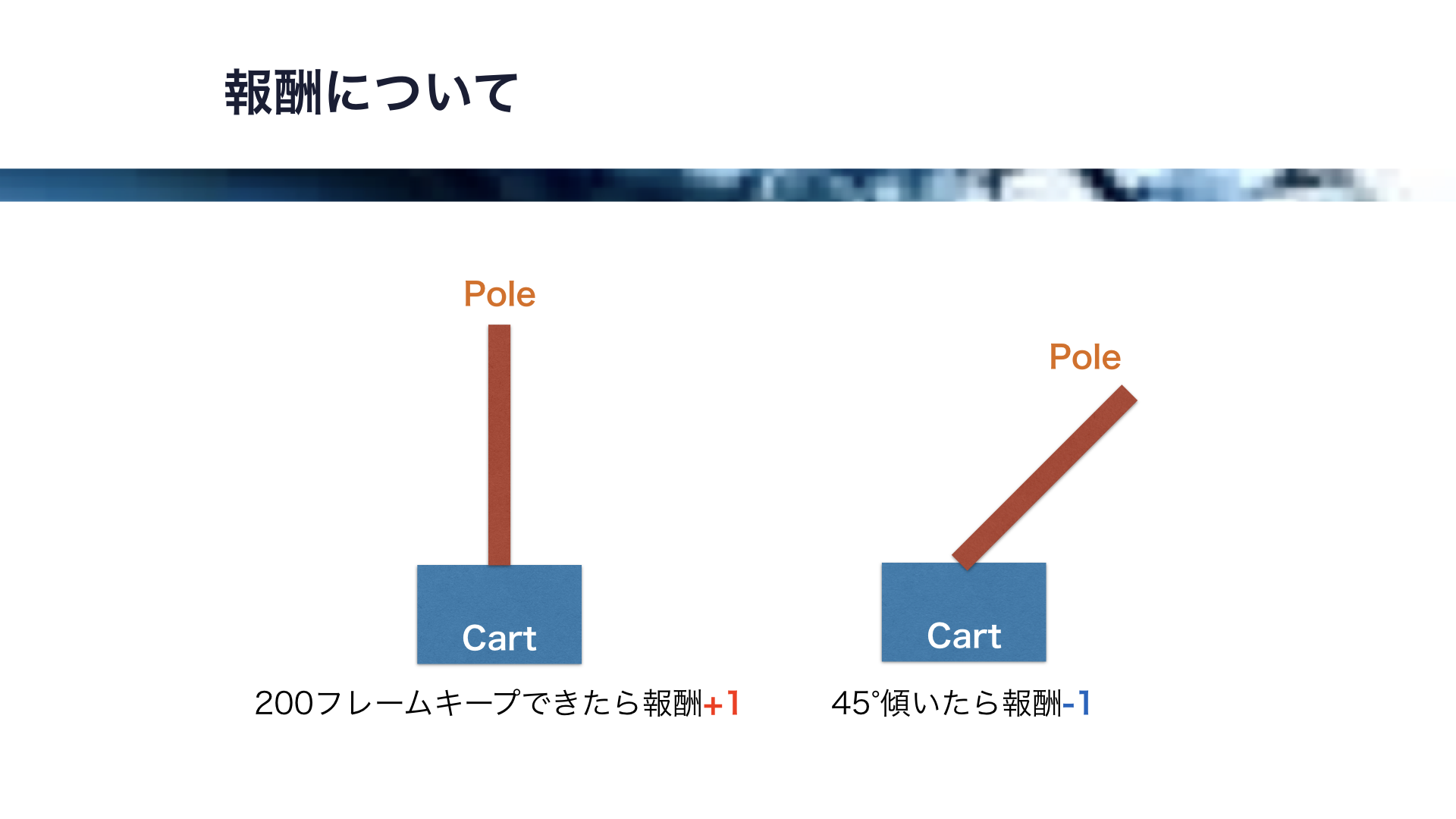
報酬についてですが、ポールが45°傾いたら失敗とし、-1の報酬が与えられます。
また、ポールが45°以上傾かない状態を200フレームキープできたら成功とし、+1の報酬が与えられます。
この報酬が伝播し、Q値が更新されていきます。
それでは、Swiftにより実装したCart Pole問題のデモを行います。
動画にご注目ください。
このロボットに感情移入できるように、成功した時は笑顔、失敗した時は悲しい顔になるようにしています。
各フレームごとに、状態に基づき左右どちらかに小さく移動しています。
移動という行動を繰り返すことで、Q値がQ-Table全体に伝播していきます。
最初は失敗ばかりしていますが、この時負の報酬が伝播することで、同じ行動を繰り返さないように学習が行われます。
次第に学習してきましたね。あとちょいです。
やがて、安定してPoleを立てることができるようになります。
ロボットが失敗を繰り返してもめげずに練習し、やがて成功する姿を見ると思わず感情移入してしまいますね。
この後は、このCartPole問題を深層強化学習を用いて実装することにトライします。

それでは、Section 3に入ります。
ここではまず、深層強化学習に必要なニューラルネットワークの実装方法を選定します。
そして、Accelerate Framework、及びこれに含まれる線形代数ライブラリBLASの解説をします。
BLASを用いることによるニューラルネットワークの構築に必要な行列の操作を比較的簡単に行うことができます。
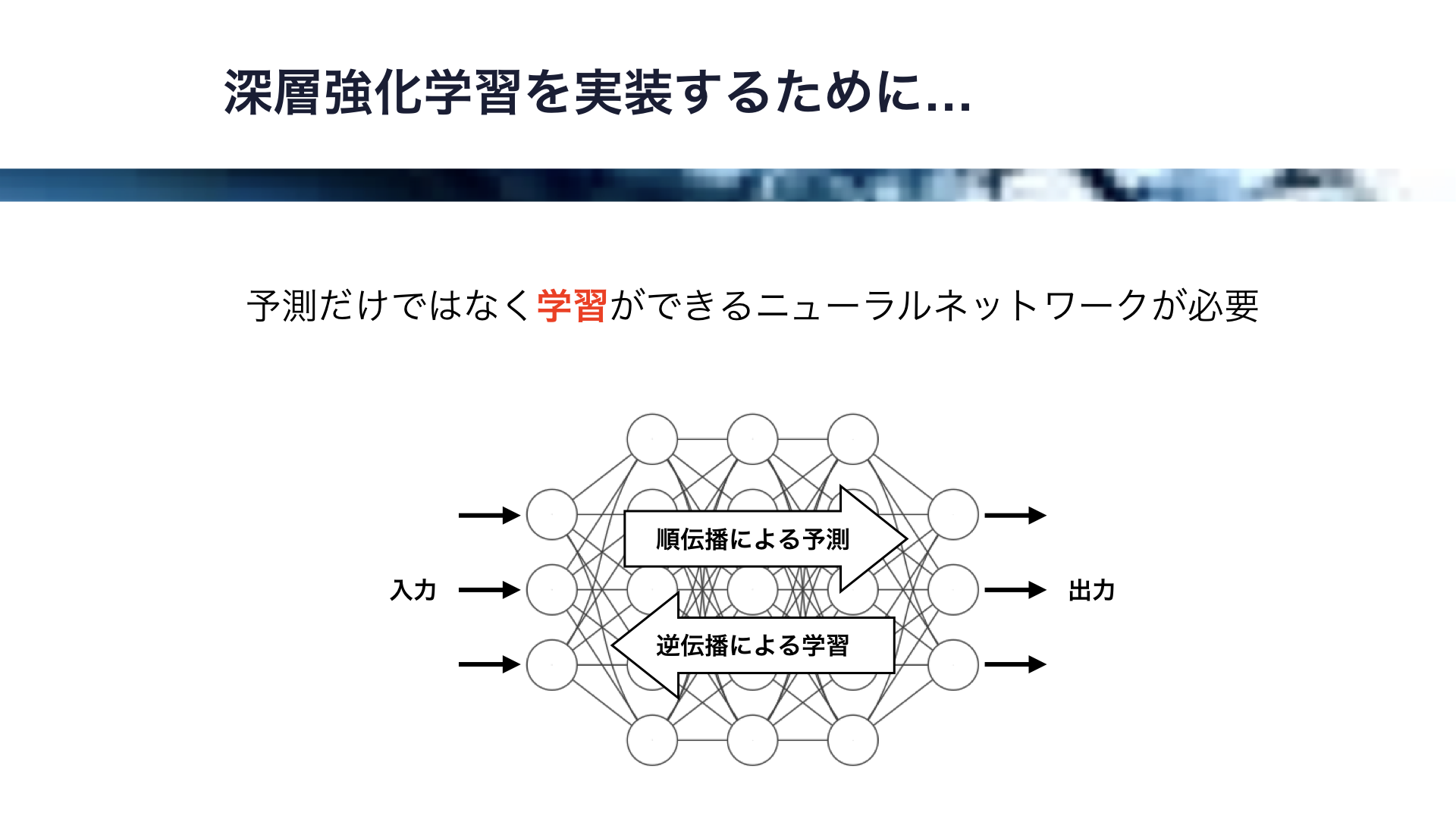
それでは、ニューラルネットワークの実装方法を選定していきましょう。
ここに、ニューラルネットワークを示します。
このように入力から出力に情報が伝わることを順伝播といいますが、ニューラルネットワークが学習するためには出力から入力に情報が伝わる逆伝播が必要です。
順伝播では予測が行われ、逆伝播では学習が行われます。
深層強化学習では逆伝播による学習が必要なので、このセクションではまずiOSにおける学習可能なニューラルネットワークの実装方法を模索します。
それでは、iOSにおける機械学習関係のフレームワークを見ていきましょう。
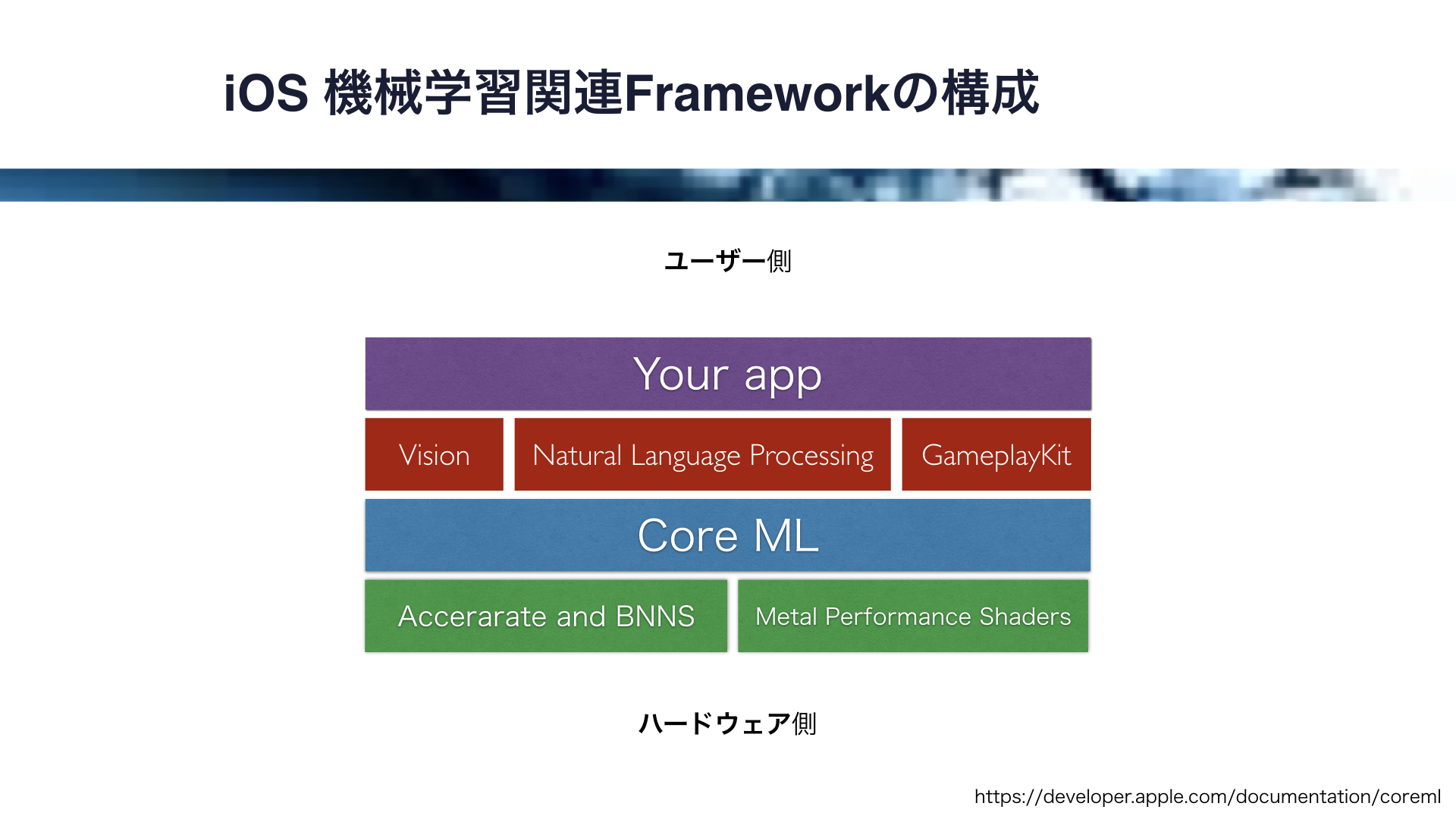
フレームワークの構成はこの図のようになっています。
一番ハードウェアに近いところにあるのが、CPUで動作するAcceratateとBNNS、そしてGPUで動作するMetal Performance Shdersです。
そして、それらをベースとして動作する機械学習フレームワークが、iOS11で導入されたCore MLです。
また、このCore MLをベースとして、画像解析のVisionフレームワーク、自然言語解析のNatural Language Processing、ゲーム用のGameplayKitフレームワークが動作します。
これらの中でも、比較的ハードウェアに近いものを見ていきましょう。
まずCoreMLは、訓練済みのモデルを簡単にアプリに導入することができるのですが、これは機械学習の予測に特化しています。
学習はできないので、今回の目的には適していません。
そして、MPS、Metal Performance Shadersですが、これはGPUを用いたMeltaの高い演算能力をアプリに導入することができます。
しかしながら、これも機械学習の予測に特化しており、今回の目的には適していません。
BNNS、Basic Neural Network SubroutinesはCPUの性能をフルに引き出して演算を行います。
これも予測に特化しており、学習ができないため今回の目的には適しておりません。
以上のようにAppleが提供しているフレームワークでは学習ができないので、今回はニューラルネットワークを自作することにします。
さて、ニューラルネットワークを実装するために重要な行列演算が2つあります。
それは、行列積と転置です。
この2つを簡単に解説します。
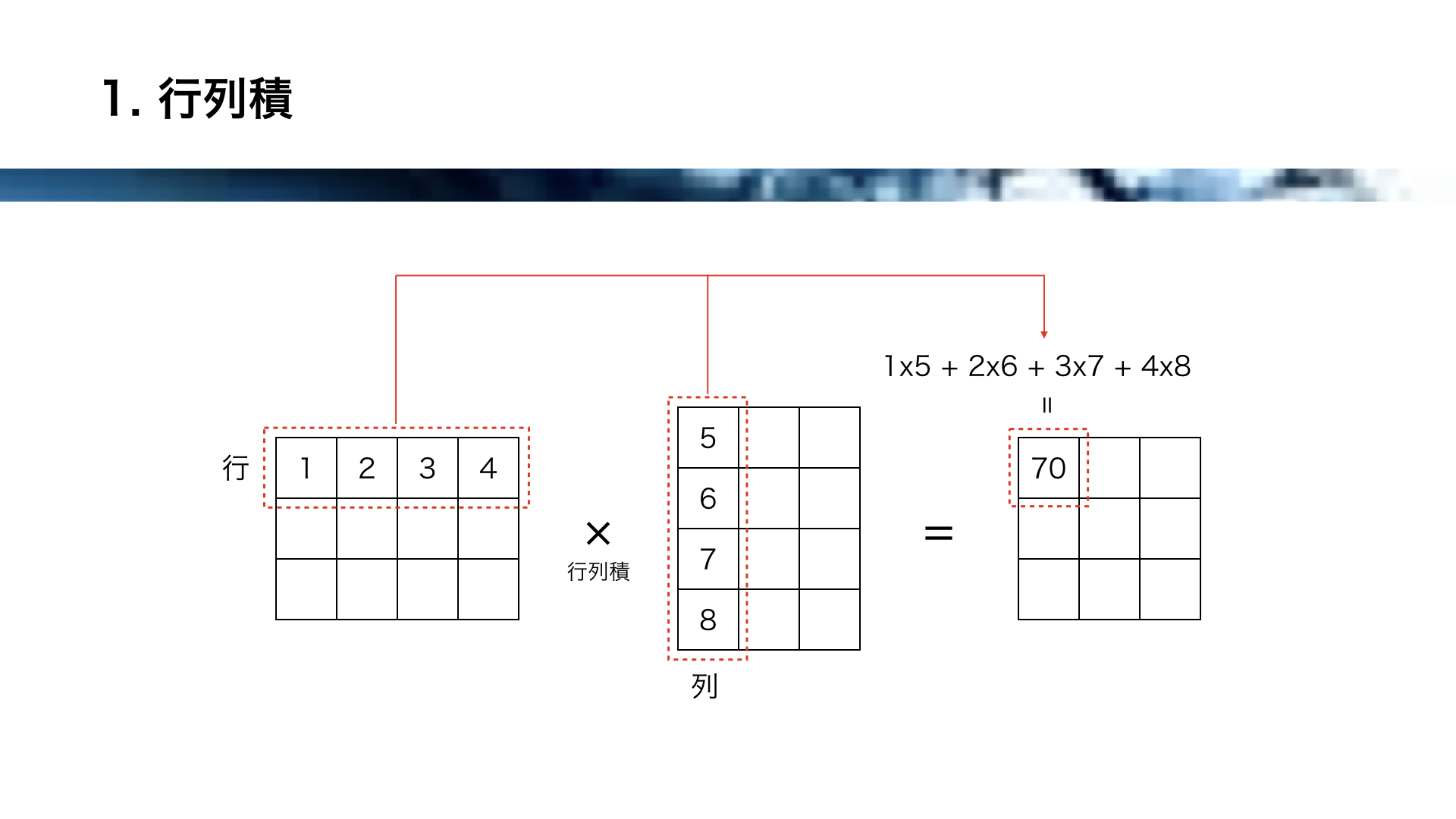
行列積は、左の行列の各行と、右の行列の各列の、各要素をかけ合わせて総和をとります。
これにより、ニューラルネットワークに必要な膨大な計算を、1つの行列積で一度に行うことが可能になります。

そして、転置もニューラルネットワークにおいて重要な操作です。
転置により、ここに示すように行列の行と列が入れ替わります。
これにより、数値が並ぶ方向を状況に応じて入れ替えることが可能になります。
ニューラルネットワークの実装方法は、以上の行列積と転置ができることを基準に選定します。
実装にはいくつかの方法が考えられますので、リストアップしていきます。
まず、Pure Swiftによる実装です。
この場合、行列やベクトルを自分で定義する必要があります。
行列積や転置を含め、全て自前で実装する必要があり手間がかかるので、今回はパスしました。
また、Metalの演算機能により実装する方法も考えられます。
しかしながら、Metalの演算を行うとなぜかSpriteKitと干渉して画面がちらつくという問題が発生しました。
また、GPUに頻繁にアクセスするとパフォーマンスが落ちるので、リアルタイムで処理が必要な今回のケースには適していないと判断しました。
そして、Accelerate Frameworkによる実装です。
これは、線形代数ライブラリBLASを含みます。
BLASには、行列積、転置を簡単に行える関数が存在します。
従って、今回はこのAccelerate Frameworkによる実装を採用しました。
Accelerate Frameworkは、大規模な数学計算、画像演算に用いられるライブラリで、CPUの性能をフルに引き出して演算を行います。
そして、高いパフォーマンスと省電力を両立しています。
Accelerate Frameworkが含むライブラリ群には次のようなものがあります。
まず、画像処理用のvImage、先ほど紹介したニューラルネットワーク用のBNNS、線形代数用のBLASなどです。
今回は、この中のBLASを使います。

BLASはBasic Liner Algebra Subprogramsの略で、その名の通り線形代数のライブラリです。
BLASは行列やベクトルを表す型、la_object_tを持っています。
この型を持つ行列のオブジェクトは、例えばla_matrix_from_double_buffer関数を使ってSwiftの配列から生成することができます。
la_object_t型の行列オブジェクトは、la_matrix_product関数を使って行列積を簡単に計算することができて、la_transpose関数を使って簡単に転置を行うことができます。
以上のように、BLASを採用することでニューラルネットワークを実装する準備は整いました。

それでは、最後のSection 4に入ります。
ここでは、深層強化学習の一種、Deep Q-Networkの実装を行います。
まずはSwiftによるニューラルネットワークの構築方法を解説し、Deep Q-Networkのデモを行います。
それでは、Deep Q-Networkの復習をします。
ネットワークの入力が状態を表し、出力がQ値になります。
このネットワークは、逆伝播によりQ値が最適な値になるように学習を行います。
ニューラルネットワークはニューロンが層状に並んで構成されていますが、この層をSwiftのクラスとして実装します。

各層をこのようにクラスとして実装した上で、行列積と転置を実装します。
行列積に関しては、la_object_tオブジェクト同士の積の演算子をこのように定義しておきます。
また、転置はla_object_tのextensionで実装しておくと扱いやすいです。

そして、層のクラスの中には、順伝播と逆伝播のメソッドを実装します。
順伝播と逆伝播は、それぞれこちらのように実装します。
原理を解説すると長くなるので今回は省きますが、la_object_tを用いることで短いコードで順伝播と逆伝播を実装できることが分かるかと思います。
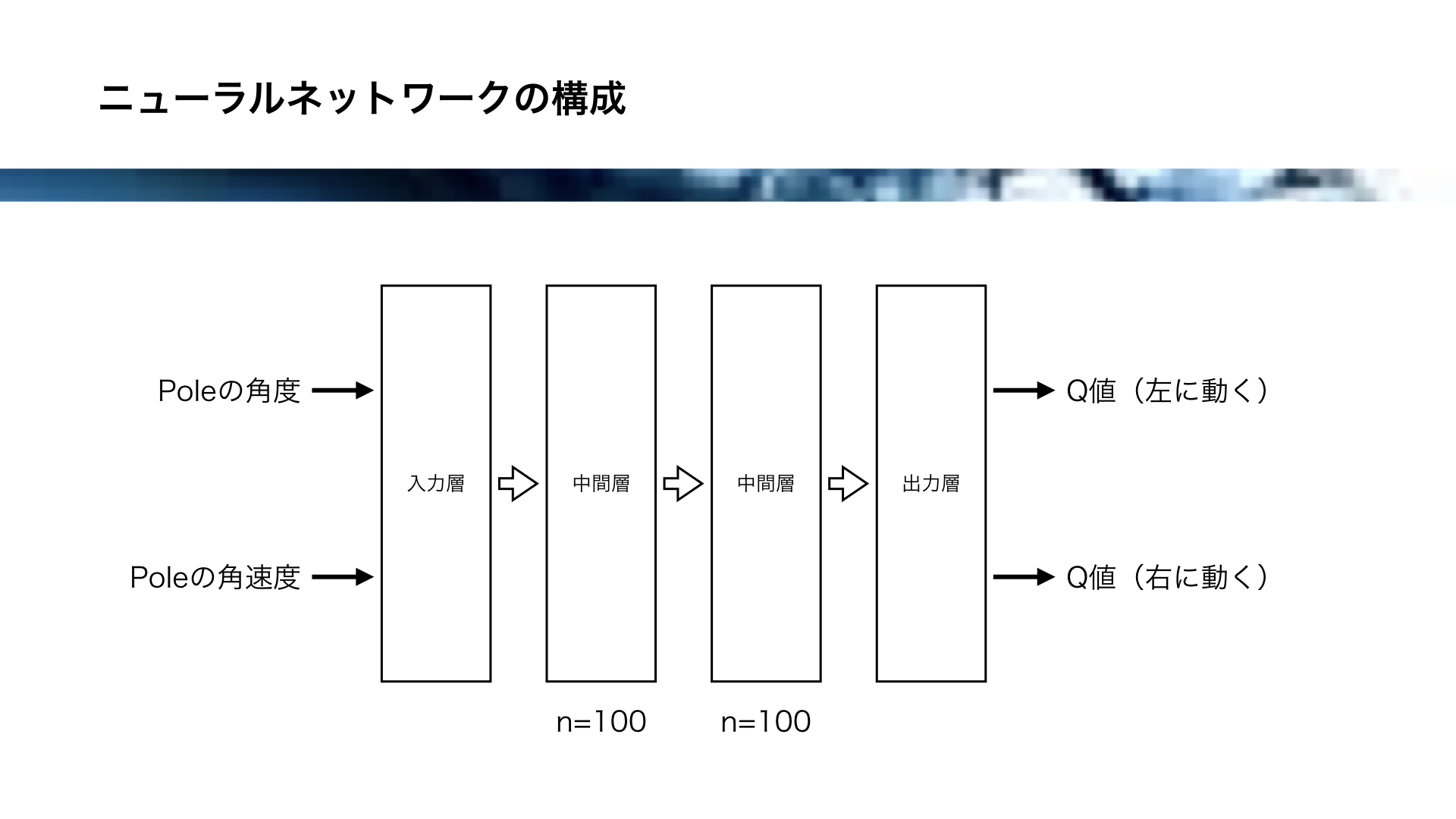
このような層のクラスのオブジェクトを並べることで、ニューラルネットワーク が構成されます。
今回Deep Q-Networkに使用するネットワークの構成はこちらの通りです。
入力層、中間層が2つ、出力層の4層構造になります。
入力には、状態としてPoleの角度とPoleの角速度の2つがあり、出力には左に動く行動のQ値と、右に動く行動のQ値があります。
2つの中間層には、それぞれ100個のニューロンがあります。
それでは、Deep Q-NetworkによるCart Pole問題のデモを行います。
動画にご注目ください。
Q学習の場合と同様に、最初は失敗ばかりです。
しかしながら、次第にニューラルネットワークが学習していきます。
その結果、ロボットは次第に失敗につながる行動を避けるようになります。
だんだん成功する頻度が高くなり、最終的には安定してポールを立てられるようになります。
ロボットがにっこりするようになりましたね。
安定してポールを保持できるようになりました。
以上のようにして、iOSに深層強化学習を実装することができました。
ところで、Deep Q-Networkにおいてロボットは様々な戦略を見せることがあります。
そのうちのいくつかを紹介したいと思います。
まず、ぶるぶる移動作戦です。
このように体を小刻みに震わせながら、一方向に移動していきます。
皆さんの中にも、ほうきを手に立てるとき一方向に歩くと安定することを経験した方もいるのではないでしょうか。
次に、スイッチ作戦です。
まるでフラフープのように体を左右に振ることで安定化します。
今回の実装に体を振ることへのペナルティはありませんので、このような作戦もありです。
そして、カウンターアタックです。
ロボットは最初にあえて一方向にポールを傾け、倒れた方向に加速することで安定化を図ります。
以上のように、深層強化学習によるAIは、開発者の意図しない創造性のようなものを時には発揮することがあります。
それでは、まとめに入ります。
iOS上における学習可能なニューラルネットワーク ですが、Accelerate FrameworkのBLASを使えば比較的容易に実装することができます。
また、Cart Pole問題を題材に、Q学習とDeep Q-NetworkをiOS上に実装することができました。
その結果、AIが思わぬ創造性のようなものを発揮しました。
今回の発表のテーマは、「iOSに深層強化学習は実装できるのか?」でしたが、少なくとも比較的シンプルなCart Pole問題のようなものであれば、iOSに深層強化学習が実装可能であることが実証できました。
なお、少し宣伝になってしましますが今回実装したようなニューラルネットワークは著書の「はじめてのディープラーニング」を読めば、どの言語でも実装できるようになるかと思います。
フレームワークを使わずにディープラーニングを実装するので、ディープラーニングの原理が身につくからです。
また、今回使用したコードはGitHubに置いておきますので、興味のある方はぜひ動かして遊んでみてくださいね。
https://github.com/yukinaga/CartPoleSwift
https://github.com/yukinaga/CartPoleDeepSwift
今回の発表は以上になります。ご静聴をありがとうございました。