これは 6/28 に開催される GraphQL ナイト のための資料です ![]()



ここまでで分かること
- クエリは独自言語みたい
- クエリを変えることで柔軟にデータをとってこれそう
- クエリと結果の見た目が似てるのは分かりやすそう(主観)
でも facebook はなんで作ったの?
facebook の事情
- 数十億ユーザから膨大なリクエストがくる
- 新興国の低速なネットワークからのモバイル接続も多い
- アップデートされないモバイルアプリもサポートする
つまり
- リクエスト回数は可能な限り減らしたい
- 後方互換を維持しながら API を開発したい
- 無駄なデータを送りたくない
- (大規模開発なので型安全も欲しい)
規模は違えど我々も同じような問題を抱えているのでは? 
なぜ既存のものではダメだったのか?
より詳しくは昔の graphql.org のページを参照(internet archive)
v.s. REST
- 複雑なデータを取得しようとするとリクエスト回数が増える
- 後方互換を保ちながら拡張すると送信するデータが増える
- 後方非互換なバージョンが増えると管理が大変
- 型が標準的にはついてこない
v.s. 専用 API
- 巨大システムではメンテンナンスが大変
- REST 同様古いクライアントを壊さないために注意が必要
GraphQL ではどうなっている?
- GraphQL API そのものにはバージョンという概念はない。
- https://api.github.com/graphql
- field 単位で
@deprecatedにする
- クライアントが必要な field だけを返すので、新しい field を追加しても既存のクライアントへのレスポンスが変わらない
- 1 つのクエリで複数のデータを取ってこれるので、何度も API リクエストする必要がない
- 型が強制される
(field と型については割愛 ![]() )
)

よくあるかも知れない質問
Q. 独自言語の学習コストは?
A. ![]() ゼロではないが、SQL とかと比べれば屁でもない
ゼロではないが、SQL とかと比べれば屁でもない
Q. Node.js 使わないといけないの?
A. ![]() そんなことはない
そんなことはない
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data.
https://graphql.org
GraphQL = query language + runtime
仕様と実装は完全に切り離されており、主要な言語にはだいたい runtime がすでに存在する。(facebook 内で使われているのは Haskell 製っぽい)
Q. バックエンドはグラフデータベースじゃないといけない?
A. ![]() そんなことはない
そんなことはない
DB は何でもいいし、複数にまたがってもいい。例えば AWS AppSync では Amazon DynamoDB, Amazon Elasticsearch, AWS Lambda を横断して使うことができる。
Q. 採用して大丈夫?
A. ![]() 悲惨な目にあう可能性は低い(が、言語によっては人柱感強いかも)
悲惨な目にあう可能性は低い(が、言語によっては人柱感強いかも)
採用事例は増えているが、ツールの枯れ具合は言語毎に大きく異なる。エコシステムも REST などと比べるとまだまだ未成熟。
GraphQL の柔軟さゆえにいくらでも巨大なクエリを投げつけられるが、標準的な対処方法が存在しないという問題がある。個人的には公開 API にするのはちょっと怖い。
Q. DB 負荷が高いって聞いたけど?
A. ![]() 正しく立ち向かえば基本的に大丈夫
正しく立ち向かえば基本的に大丈夫
何も考えずに実装するとそうなるが dataloader 的なツールを使って正しく実装すると、複数の REST API リクエストよりむしろ DB アクセス回数を減らせる可能性もある。 dataloader についても各種言語ごとに実装があるはず。
まとめ
- GraphQL を作ったモチベーションは我々にも通じる
- GraphQL は仕様と実装で構成される
- エコシステムは発展途上
- dataloader
- Apollo
- Relay
- AWS AppSync
- etc.
- みんなで使って知見を(願わくば Qiita で)共有しよう
おまけ: なぜ GraphQL という名前なのか
(個人の見解です)
アプリケーションのデータはグラフとして解釈することができる
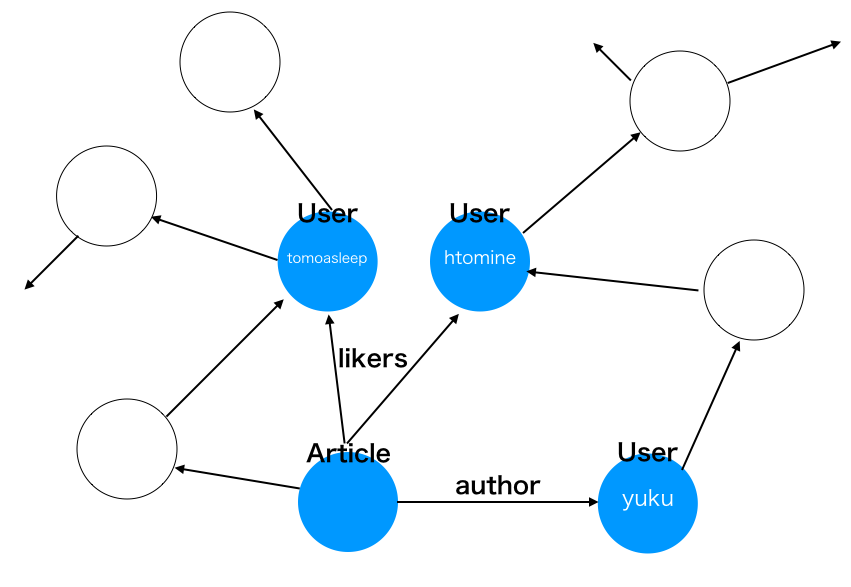
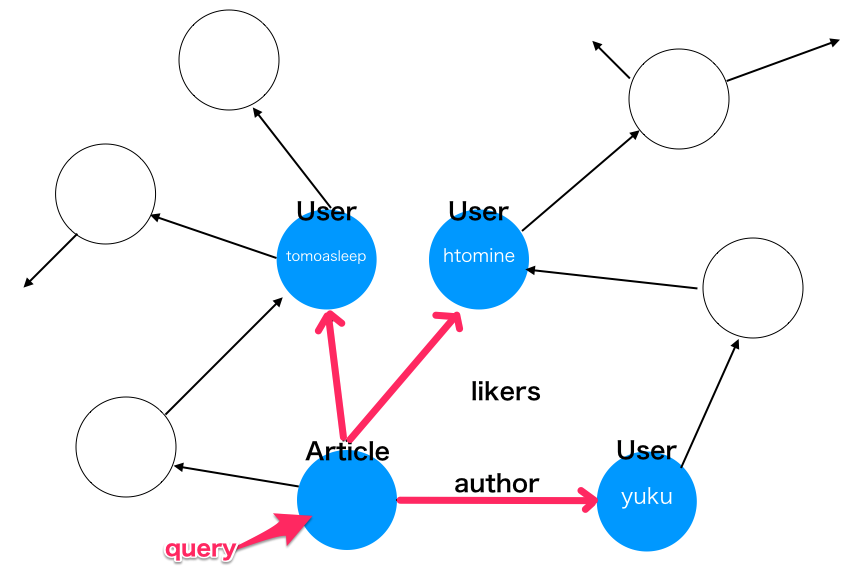
このグラフに対して以下のようなクエリを適用してみる。
query {
# id が 1 の Article の
article(id: 1) {
# author の name と
author { name }
# likers の name をとってくる
likers { name }
}
}
{
"data": {
"article": {
"author": {
"name": "yuku"
},
"likers": [
{ "name": "htomine" },
{ "name": "tomoasleep" }
]
}
}
}
グラフを問い合わせるための言語だから Graph Query Language
おまけ2: Qiita での事例
GraphQL はクライアントからデータを取得することを念頭に置いたシステムだが、 Qiita ではサーバでのレンダリング時にも部分的に使っている。
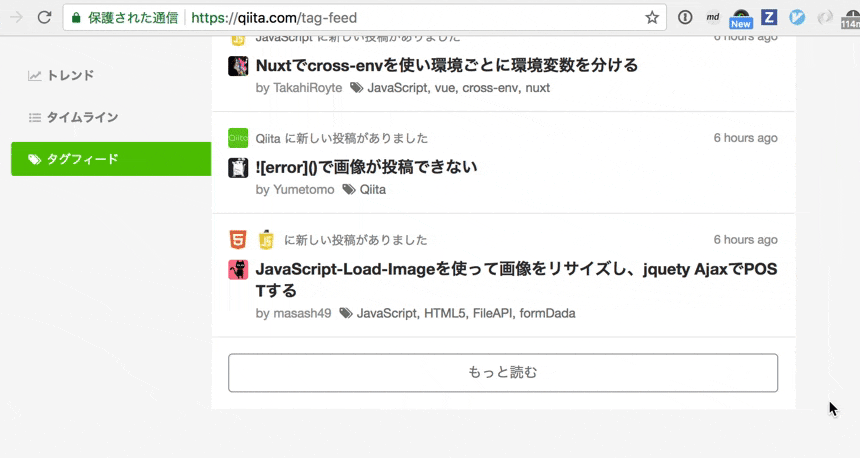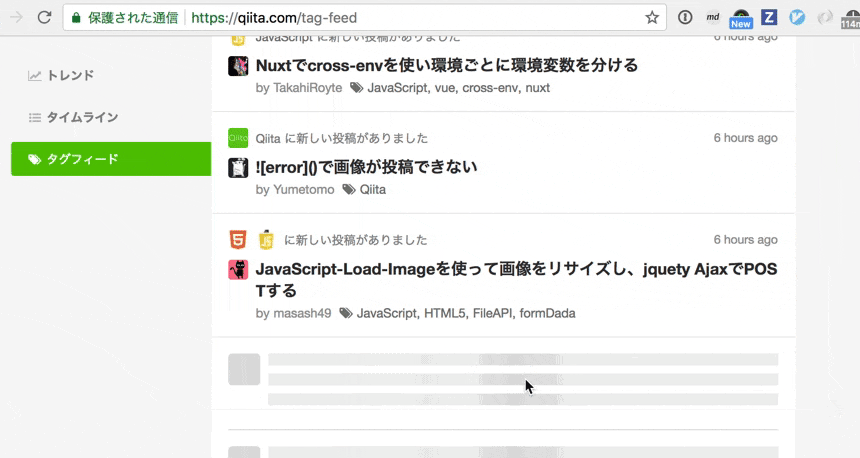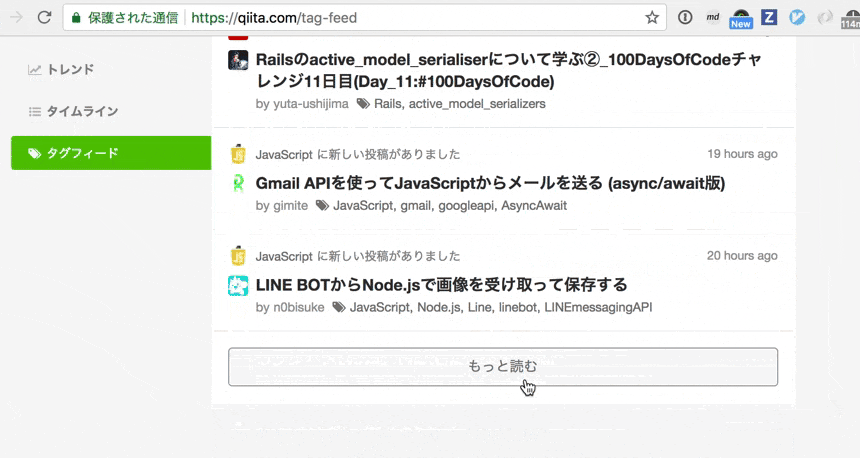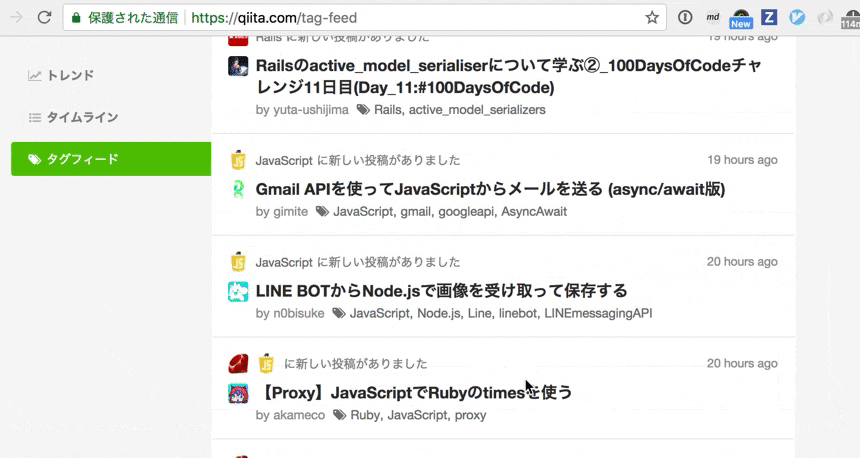
サーバで作る初期データと「もっと読む」を押したときに JS で取得する JSON データの取得周りを DRY にしたい。
class HomeController < ApplicationController
# `load_graphql_from_client` はファイルを読み込んで文字列として返すメソッド。
TAG_FEED_QUERY = <<~GRAPHQL
query {
tagFeed(first: 20) {
...TagFeed
}
}
#{load_graphql_from_client('TagFeedFragment')}
GRAPHQL
def tag_feed
result = execute_graphql(TAG_FEED_QUERY)
@tag_feed = result.data.tag_feed
end
end
fragment TagFeed on TagFeedConnection {
# ...
}
= tag.div(data: { props: @tag_feed })
この view が生成する HTML は以下のような形で
<div data-props="{JSON}"/>
{JSON} は TagFeedFragment.graphql によって定まる。apollo-codegen で TypeScript の型を生成できるので、安全に TypeScript から取り出すことが可能
import { TagFeedFragment } from "./types-generated-by-apollo-codegen"
const props: TagFeedFragment = JSON.parse(el.dataset.props)
また先程の fragment を使ってクライアントからサーバに問い合わせることができる
import TagFeed from "./graphql/TagFeedFragment"
const query = `
query ($after: String!) {
tagFeed(after: $after, first: 20) {
...TagFeed
}
}
${TagFeed}
`
const result = await post('/graphql', query, { after: "Mx==" })
const tagFeed: TagFeedFragment = result.data.tagFeed
こうして HTML に埋め込まれているデータと、クライアントから非同期に取得するデータが一致し、型もあって嬉しい